小叽導讀:本文提出一種基于注意力機制的使用者異構行為序列的模組化架構,并将其應用到推薦場景中。我們将不同種類的使用者行為序列進行分組編碼,并映射到不同子空間中。我們利用self-attention對行為間的互相影響進行模組化。
最終我們得到使用者的行為表征,下遊任務就可以使用基本的注意力模型進行有更具指向性的決策。我們嘗試用同一種模型同時預測多種類型的使用者行為,使其達到多個單獨模型預測單類型行為的效果。另外,由于我們的方法中沒有使用RNN,CNN等方法,是以在提高效果的同時,該方法能夠有更快的訓練速度。
團隊:雲零售事業部-資料技術團隊, 北京大學
作者:周暢,白金澤,宋軍帥,劉效飛,趙争超,陳修司,高軍
▌研究背景
一個人是由其所表現出的行為所定義。而對使用者精準、深入的研究也往往是很多商業問題的核心。從長期來看,随着人們可被記錄的行為種類越來越多,平台方需要有能力通過融合各類不同的使用者行為,更好地去了解使用者,進而提供更好的個性化服務。
對于阿裡巴巴來說,以消費者營運為核心理念的全域營銷正是一個結合使用者全生态行為資料來幫助品牌實作新營銷的資料&技術驅動的解決方案。是以,對使用者行為的研究就成為了一個非常核心的問題。其中,很大的挑戰來自于能否對使用者的異構行為資料進行更精細的處理。
在這樣的背景下,本文提出一個通用的使用者表征架構,試圖融合不同類型的使用者行為序列,并以此架構在推薦任務中進行了效果驗證。另外,我們還通過多任務學習的方式,期望能夠利用該使用者表征實作不同的下遊任務。
▌相關工作
異構行為模組化: 通常通過手動特征工程來表示使用者特征。這些手工特征以聚合類特征或無時序的id特征集合為主。
單行為序列模組化: 使用者序列的模組化通常會用RNN(LSTM/GRU)或者CNN +Pooling的方式。RNN難以并行,訓練和預測時間較長,且LSTM中的Internal Memory無法記住特定的行為記錄。CNN也無法保留特定行為特征,且需要較深的層次來建立任意行為間的影響。
異構資料表征學習:參考知識圖譜和Multi-modal的表征研究工作,但通常都有非常明顯的映射監督。而在我們的任務中,異構的行為之間并沒有像image caption這種任務那樣明顯的映射關系。
本文的主要貢獻如下:
- 嘗試設計和實作了一種能夠融合使用者多種時序行為資料的方法,較為創新的想法在于提出了一種同時考慮異構行為和時序的解決方案,并給出較為簡潔的實作方式。
- 使用類似Google的self-attention機制去除CNN、LSTM的限制,讓網絡訓練和預測速度變快的同時,效果還可以略有提升。
- 此架構便于擴充。可以允許更多不同類型的行為資料接入,同時提供多任務學習的機會,來彌補行為稀疏性。
▌ATRank方案介紹

整個使用者表征的架構包括原始特征層,語義映射層,Self-Attention層和目标網絡。語義映射層能讓不同的行為可以在不同的語義空間下進行比較和互相作用。Self-Attention層讓單個的行為本身變成考慮到其他行為影響的記錄。目标網絡則通過Vanilla Attention可以準确地找到相關的使用者行為進行預測任務。通過TimeEncoding + Self Attention的思路,我們的實驗表明其的确可以替代CNN/RNN來描述序列資訊,能使模型的訓練和預測速度更快。
1. 行為分組
某個使用者的行為序列可以用一個三元組來描述(動作類型、目标、時間)。我們先将使用者不同的行為按照目标實體進行分組,如圖中最下方不同顔色group。例如商品行為、優惠券行為、關鍵字行為等等。動作類型可以是點選、收藏、加購、領取、使用等等。
每個實體都有自己不同的屬性,包括實值特征和離散id類特征。動作類型是id類,我們也将時間離散化。三部分相加得到下一層的向量組。
即,某行為的編碼 = 自定義目标編碼 + lookup(離散化時間) + lookup(動作類型)。
由于實體的資訊量不同,是以每一組行為編碼的向量長度不一,其實也代表行為所含的資訊量有所不同。另外,不同行為之間可能會共享一些參數,例如店鋪id、類目id這類特征的lookuptable,這樣做能減少一定的稀疏性,同時降低參數總量。
分組的主要目的除了說明起來比較友善,還與實作有關。因為變長、異構的處理很難高效地在不分組的情況下實作。并且在後面還可以看到我們的方法實際上并不強制依賴于行為按時間排序。
2. 語義空間映射
這一層通過将異構行為線性映射到多個語義空間,來實作異構行為之間的同語義交流。例如架構圖中想表達的空間是紅綠藍(RGB)構成的原子語義空間,下面的複合色彩(不同類型的使用者行為)會投影到各個原子語義空間。在相同語義空間下,這些異構行為的相同語義成分才有了可比性。
類似的思路其實也在knowledge graph representation裡也有出現。而在NLP領域,今年也有一些研究表明多語義空間的attention機制可以提升效果。個人認為的一點解釋是說,如果不分多語義空間,會發生所謂語義中和的問題。簡單的了解是,兩個不同種類的行為a,b可能隻在某種領域上有相關性,然而當attention score是一個全局的标量時, a,b在不那麼相關的領域上會增大互相影響,而在高度相關的領域上這種影響則會減弱。
盡管從實作的角度上來說,這一層就是所有行為編碼向一個統一的空間進行映射,映射方法線性非線性都可以,但實際上,對于後面的網絡層來說,我們可以看作是将一個大的空間劃分為多語義空間,并在每個子空間裡進行self-attention操作。是以從解釋上來說,我們簡單地把這個映射直接描述成對多個子語義空間進行投影。
3. Self Attention層
Self Attention層的目的實際上是想将使用者的每一個行為從一個客觀的表征,做成一個使用者記憶中的表征。客觀的表征是指,比如A,B做了同樣一件事,這個行為本身的表征可能是相同的。但這個行為在A,B的記憶中,可能強度、清晰度是完全不一樣的,這是因為A,B的其他行為不同。實際上,觀察softmax函數可知,某種相似行為做的越多,他們的表征就越會被平均。而帶來不一樣體驗的行為則會更容易保留自己的資訊。是以self attention實際上模拟了一個行為被其他行為影響後的表征。
另外,Self Attention可以有多層。可以看到,一層Self-Attention對應着一階的行為影響。多層則會考慮多階的行為影響。這個網絡結構借鑒的是google的self-attention架構。
具體計算方式如下:

記S是整個語義層拼接後的輸出,是第k個語義空間上的投影,則經過self-attention後第k個語義空間的表征計算公式為:
這裡的attention function可以看做是一種bilinear的attention函數。最後的輸出則是這些空間向量拼接後再加入一個前饋網絡。
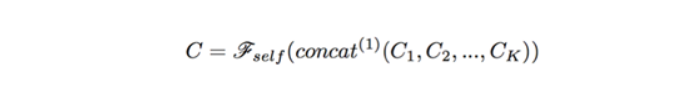
4. 目标網絡
目标網絡會随着下遊任務的不同而定制。本文所涉及的任務是使用者行為預測及推薦場景的點選預測的任務,采用的是point-wise的方式進行訓練和預測。
架構圖中灰色的bar代表待預測的任意種類的行為。我們将該行為也通過embedding、projection等轉換,然後和使用者表征産出的行為向量做vanilla attention。最後Attention向量和目标向量将被送入一個Ranking Network。其他場景強相關的特征可以放在這裡。這個網絡可以是任意的,可以是wide & deep,deep FM,pnn都行。我們在論文的實驗中就是簡單的dnn。
▌離線實驗
為了比較架構在單行為預測時的效果,我們在amazon購買行為的公開資料集上的實驗。
訓練收斂結果如下圖:
使用者平均AUC如下圖:
實驗結論:在行為預測或推薦任務中,self-attention + time encoding也能較好的替代cnn+pooling或lstm的編碼方式。訓練時間上能較cnn/lstm快4倍。效果上也能比其他方法略好一些。
CaseStudy
為了深究Self-Attention在多空間内的意義,我們在amazon dataset上做了一個簡單的case study。如下圖:
從圖中我們可以看到,不同的空間所關注的重點很不一樣。例如空間I, II, III, VIII中每一行的attention分的趨勢類似。這可能是主要展現不同行為總體的影響。另一些空間,例如VII,高分attention趨向于形成稠密的正方形,我們可以看到這其實是因為這些商品屬于同樣的類目。
下圖則是vanilla attention在不同語義空間下的得分情況。
多任務學習
論文中,我們離線收集了阿裡電商使用者對商品的購買點選收藏加購、優惠券領取、關鍵字搜尋三種行為進行訓練,同樣的也對這三種不同的行為同時進行預測。其中,使用者商品行為記錄是全網的,但最終要預測的商品點選行為是店鋪内某推薦場景的真實曝光、點選記錄。優惠券、關鍵字的訓練和預測都是全網行為。
我們分别構造了7種訓練模式進行對比。分别是單行為樣本預測同類行為(3種),全行為多模型預測單行為(3種),全行為單模型預測全行為(1種)。在最後一種實驗設定下,我們将三種預測任務各自切成mini-batch,然後統一進行shuffle并訓練。
實驗結果如下表:
all2one是三個模型分别預測三個任務,all2all是單模型預測三個任務,即三個任務共享所有參數,而沒有各自獨占的部分。是以all2all與all2one相比稍低可以了解。我們訓練多任務all2all時,将三種不同的預測任務各自batch後進行充分随機的shuffle。文中的多任務訓練方式還是有很多可以提升的地方,前沿也出現了一些很好的可借鑒的方法,是我們目前正在嘗試的方向之一。
實驗表明,我們的架構可以通過融入更多的行為資料來達到更好的推薦、行為預測的效果。
▌總結
本文提出一個通用的使用者表征架構,來融合不同類型的使用者行為序列,并在推薦任務中得到驗證。
未來,我們希望能結合更多實際的商業場景和更豐富的資料沉澱出靈活、可擴充的使用者表征體系,進而更好的了解使用者,提供更優質的個性化服務,輸出更全面的資料能力。