作者:關文選,花名雲魄,阿裡雲E-MapReduce 進階開發工程師,專注于流式計算,Spark Contributor
1.背景介紹
流式計算一個很常見的場景是基于事件時間進行處理,常用于檢測、監控、根據時間進行統計等系統中。比如埋點日志中每條日志記錄了埋點處操作的時間,或者業務系統中記錄了使用者操作時間,用于統計各種操作處理的頻率等,或者根據規則比對,進行異常行為檢測或監控系統告警。這樣的時間資料都會包含在事件資料中,需要提取時間字段并根據一定的時間範圍進行統計或者規則比對等。
使用Spark Streaming SQL可以很友善的對事件資料中的時間字段進行處理,同時Spark Streaming SQL提供的時間視窗函數可以将事件時間按照一定的時間區間對資料進行統計操作。
本文通過講解一個統計使用者在過去5秒鐘内點選網頁次數的案例,介紹如何使用Spark Streaming SQL對事件時間進行操作。
2.時間窗文法說明
Spark Streaming SQL支援兩類視窗操作:滾動視窗(TUMBLING)和滑動視窗(HOPPING)。
2.1滾動視窗
滾動視窗(TUMBLING)根據每條資料的時間字段将資料配置設定到一個指定大小的視窗中進行操作,視窗以視窗大小為步長進行滑動,視窗之間不會出現重疊。例如:如果指定了一個5分鐘大小的滾動視窗,資料會根據時間劃分到 [0:00 - 0:05)、 [0:05, 0:10)、[0:10, 0:15)等視窗。
- 文法
- 示例
對inventory表的inv_data_time時間列進行視窗操作,統計inv_quantity_on_hand的均值;視窗大小為1分鐘。
FROM inventory
GROUP BY TUMBLING (inv_data_time, interval 1 minute) 2.2滑動視窗
滑動視窗(HOPPING),也被稱作Sliding Window。不同于滾動視窗,滑動視窗可以設定視窗滑動的步長,是以視窗可以重疊。滑動視窗有兩個參數:windowDuration和slideDuration。slideDuration為每次滑動的步長,windowDuration為視窗的大小。當slideDuration < windowDuration時視窗會重疊,每個元素會被配置設定到多個視窗中。
是以,滾動視窗其實是滑動視窗的一種特殊情況,即slideDuration = windowDuration則等同于滾動視窗。
- 對inventory表的inv_data_time時間列進行視窗操作,統計inv_quantity_on_hand的均值;視窗為1分鐘,滑動步長為30秒。
SELECT avg(inv_quantity_on_hand) qoh
FROM inventory
GROUP BY HOPPING (inv_data_time, interval 1 minute, interval 30 second) 3.系統架構
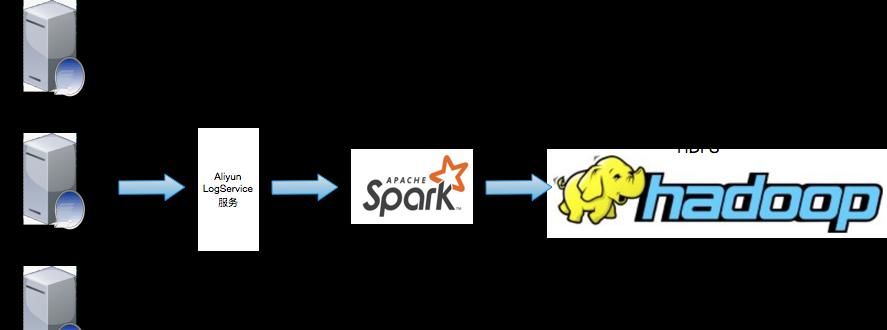
業務日志收集到Aliyun SLS後,Spark對接SLS,通過Streaming SQL對資料進行處理并将統計後的結果寫入HDFS中。後續的操作流程主要集中在Spark Streaming SQL接收SLS資料并寫入HDFS的部分,有關日志的采集請參考
日志服務。
4.操作流程
4.1環境準備
- 建立E-MapReduce 3.21.0以上版本的Hadoop叢集。
- 下載下傳并編譯E-MapReduce-SDK包
git clone [email protected]:aliyun/aliyun-emapreduce-sdk.git
cd aliyun-emapreduce-sdk
git checkout -b master-2.x origin/master-2.x
mvn clean package -DskipTests
編譯完後, assembly/target目錄下會生成emr-datasources_shaded_${version}.jar,其中${version}為sdk的版本。
4.2建立表
指令行啟動spark-sql用戶端
spark-sql --master yarn-client --num-executors 2 --executor-memory 2g --executor-cores 2 --jars emr-datasources_shaded_2.11-${version}.jar --driver-class-path emr-datasources_shaded_2.11-${version}.jar
建立SLS和HDFS表
spark-sql> USE default;
-- 資料源表
spark-sql> CREATE TABLE IF NOT EXISTS sls_user_log
USING loghub
OPTIONS (
sls.project = "${logProjectName}",
sls.store = "${logStoreName}",
access.key.id = "${accessKeyId}",
access.key.secret = "${accessKeySecret}",
endpoint = "${endpoint}");
--結果表
spark-sql> CREATE TABLE hdfs_user_click_count
USING org.apache.spark.sql.json
OPTIONS (path '${hdfsPath}'); 4.3統計使用者點選數
spark-sql>SET spark.sql.streaming.checkpointLocation.user_click_count=hdfs:///tmp/spark/sql/streaming/test/user_click_count;
spark-sql>insert into hdfs_user_click_count
select sum(cast(action_click as int)) as click, userId, window from sls_user_log
where delay(__time__)<"1 minute"
group by TUMBLING(__time__, interval 5 second), userId; 其中,内建函數delay()用來設定Streaming SQL中的watermark,後續會有專門的文章介紹Streaming SQL watermark的相關内容。
4.4檢視結果

可以看到,産生的結果會自動生成一個window列,包含視窗的起止時間資訊。
5.結語
本文簡要介紹了流式進行中基于事件時間進行處理的場景,以及Spark Streaming SQL時間視窗的相關内容,并通過一個簡單案例介紹了時間視窗的使用。後續文章,我将介紹Spark Streaming SQL的更多内容。