以下為精彩視訊内容整理:
實時計算概述
實時計算
阿裡雲實時計算(Alibaba Cloud Realtime Compute)是一套基于Apache Flink建構的一站式、高性能實時大資料處理平台,廣泛适應于流式資料處理、離線資料處理等場景,最重要的一點是免運維,可以為企業節省了大量的成本。
産品模式
阿裡雲的實時計算産品模式有Flink雲原生版和獨享模式。目前Flink雲原生版支援部署于容器服務ACK提供的Kubernetes。獨享模式是指在阿裡雲ECS上單獨為使用者建立的獨立計算叢集。單個使用者獨享計算叢集的實體資源(網絡、磁盤、CPU或記憶體等),與其它使用者的資源完全獨立。獨享模式分為包年包月和按量付費兩種方式。
Flink簡介
Flink是開源的流處理架構,其核心是用Java和Scala編寫的分布式流資料流引擎。它的特點是支援高吞吐、低延遲、高性能的流處理,支援帶有事件時間的視窗(Window)操作,支援有狀态計算的Exactly-once語義,支援基于輕量級分布式快照(Snapshot)實作的容錯,同時支援Batch on Streaming處理和Streaming處理,Flink在JVM内部實作了自己的記憶體管理,支援疊代計算,支援程式自動優化,避免特定情況下Shuffle、排序等昂貴操作,中間結果有必要進行緩存。
Flink架構圖
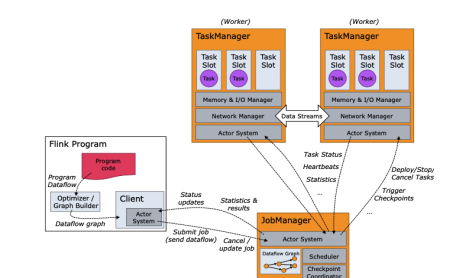
阿裡雲的程式送出主要從用戶端進行送出。其中,JobClient負責接收程式、解析程式的執行計劃、優化程式的執行計劃,然後送出執行計劃到JobManager。JobManager主要負責申請資源,協調以及控制整個job的執行過程。TaskManager的主要作用是接收并執行JobManager發送的task,并且與JobManager通信,回報任務狀态資訊。Slot是TaskManager資源粒度的劃分,每個Slot都有自己獨立的記憶體。所有Slot平均配置設定TaskManger的記憶體,比如TaskManager配置設定給Solt的記憶體為8G,兩個Slot,每個Slot的記憶體為4G,并且Slot僅劃分記憶體,不涉及cpu的劃分。
Flink程式設計模型

在Flink程式設計模型中最低級的抽象僅提供狀态流(stateful streaming),向上一層為DataStream API(資料流接口,有界/無界流)和DataSet API(資料集接口,有界資料集)。再向上為表接口(Table API),是以表為中心的聲明性DSL,可以動态地改變表(當展示流的時候)。Flink提供的最進階抽象是SQL。阿裡雲的實時計算暫時不提供批處理。
Flink計算模型
Flink計算模型主要分為三部分,第一部分為Source,第二部分為Transformation,第三部分為Sink。每一個資料流起始于一個或多個Source,經過Transformation操作,對一個或多個輸入Stream進行計算處理并終止于一個或多個Sink。
Flink的容錯機制
Flink容錯的核心機制是checkpoint,可以定期地将各個Operator處理的資料進行快照存儲(Snapshot)。如果Flink程式出現當機,可以重新從這些快照中恢複資料。Flink的checkpoint原理是Flink定期的向流應用中發送barrier,當算子收到barrier會暫停處理會将state制成快照,然後向下遊廣播barrier,直到Sink算子收到barrier,快照制作完成。阿裡雲的barrier是不參與計算的,并且是非常輕量的。
Spark Streaming與實時計算的對比
生态內建對比
Spark Streaming資料源支援KafKa、Flume、HDFS/S3、Kinesis以及Twitter資料源,同樣Flink也支援這些資料源。在資料計算中分為資料源表、資料結果表和資料維表。資料源表支援DataHub、消息隊列MQ,KafKa、MaxCompute、表格存儲TableStore。資料結果表支援分析型資料庫MySQL版2.0、據總線DataHub、日志服務LOG結果表、消息隊列MQ結果表、表格存儲TableStore、雲資料庫RDS版、MaxCompute、雲資料庫HBase版、Elastic Search、Kafka、HybridDB for MySQL、自定義、雲資料庫MongoDB版、雲資料庫Redis版、雲資料庫RDS SQL Server版、分析型資料庫MySQL版3.0結果表。資料維表支援表格存儲TableStore、雲資料庫RDS版、雲資料庫HBase版、MaxCompute(ODPS)、ElasticSearch。
API對比
Spark Streaming支援底層的API是RDD,而Flink支援底層的API是Process Function。Spark Streaming核心API是DataFrame/DataSet/Structured Streaming,而Flink的核心API是DataStream/DataSet。Spark Streaming支援的SQL是Spark SQL,而Flink支援的SQL是Table API和 SQL。相同的是,Spark Streaming和Flink都支援機器學習,Spark Streaming支援MLlib,而Flink支援FlinkML。Spark Streaming支援的圖計算是GraphX,而Flink支援Gelly。但阿裡雲的Flink在流計算方面更成熟一些。
資料處理模式對比
上圖所示為Spark Streaming,是基于Spark高效的批處理能力,對流資料劃分為多個小批資料,再分别對這些資料進行處理,即微批處理模式,運作的時候需要指定批處理的時間,每次運作作業時處理一個批次的資料。并不是真正的流計算,而是進行微批處理的。
上圖所示為阿裡雲的Flink,是基于事件驅動的,事件可以了解為消息,即源源不斷沒有邊界的資料,并且資料的狀态可以改變,對于批處理則認為是有邊界的流進行處理。
時間機制對比
Flink提供了3種時間模型:EventTime、ProcessingTime、IngestionTime,在實時計算中支援EventTime、ProcessingTime,而Spark Streaming僅支援ProcessingTime。其中,EventTime指事件生成時的時間,在進入Flink之前就已經存在,可以從event的字段中抽取。IngestionTime指事件進入Flink的時間,即在source裡擷取的目前系統的時間,後續操作統一使用該時間。ProcessingTime指執行操作的機器的目前系統時間(每個算子都不一樣)。阿裡雲的Flink也提供了WaterMark用來處理時間亂序,Watermark是一個對Event Time的辨別,這裡的亂序是指有事件遲到了,對于遲到的元素,不可能無限期的等下去,必須要有一種機制來保證一個特定的時間後,必須觸發window進行計算。比如計算一個10:00到10:10分的視窗,watermark設定延遲3s,當一條資料的watermark到達10:10:03,這個視窗才會觸發,表示這個視窗的資料已經全部到了,然後進行計算并釋放相關被占用的資源。
容錯機制對比
Spark Streaming容錯機制是利用Spark自身的容錯設計、存儲級别和RDD抽象設計,能夠處理叢集中任何worker節點的故障。Driver端利用checkpoint機制。對于接收的資料使用預寫日志的形式。Flink的容錯機制主要是基于checkpoint。定期地将各個Operator處理的資料進行快照存儲(Snapshot)。
如何使用阿裡雲實時計算
上圖所示為一個購買界面,分為master型号和slave型号。地域選擇為當時所在的地方,master主要負責管理整個叢集的資源和slave之間的互動,但不能用于計算。Slave主要負責計算。
建立項目
建立完叢集之後,來到叢集的控制台中,點選叢集清單,找到對應的叢集建立項目,填寫項目名稱和備注,其中CU指叢集還剩餘多少CU。1CU為1核4G,簡單業務時,1CU每秒可以處理10000條資料。例如,單流過濾、字元串變換等操作。複雜業務時,1CU每秒可以處理1000到5000條資料。例如,JOIN、WINDOW、GROUP BY等操作。
作業開發
然後點選對應的項目,點選開發進入到開發界面,通過建立作業和檔案夾的方式編寫自己的DDL語句。對于資源引用,阿裡雲的Flink SQL支援UDF、DataStream。 再編寫一個以DataHub為資料源,資料維表在RDS資料庫中,結果表輸出到RDS資料庫中建立一個DatahubData檔案夾,建立一個DatahubData作業。
資料存儲
資料存儲支援明文方式和存儲注冊方式。明文方式是通過在作業的DDL語句WITH參數中配置accessId和accessKey的方法。存儲注冊方式是将上下遊存儲資源預先注冊至實時計算開發平台,然後通過實時計算控制台的資料存儲管理功能,對上下遊存儲資源進行引用,可以對資料進行預覽。阿裡雲采用存儲注冊的方式注冊DataHub。填寫對應的endpoint和項目的名稱,單機作為輸入表引用,就會在作業開發界面生成DDL語句。
注冊資料結果表和維表
由于RDS資料庫存在白名單限制,連接配接RDS需要添加白名單,獨享模式的IP位址在叢集清單頁面,單擊名稱字段下目标叢集名稱,在叢集資訊視窗,檢視叢集的ENI資訊。
編寫自己SQL
從資料源表中過濾出place是北京的資料。Sql中使用了計算列,計算列的文法為column_name AS computed_column_expression,計算列可以使用其它列的資料,計算出其所屬列的數值。如果您的資料源表中沒有TIMESTAMP類型的列,可以使用計算列方法從其它類型的字段進行轉換。
檢視運維界面
Failover曲線顯示目前作業出現Failover(錯誤或者異常)的頻率。計算方法為目前Failover時間點的前1分鐘内出現Failover的累計次數除以60(例如,最近1分鐘Failover了一次,Failover的值為1/60=0.01667)。延遲分為業務延時、資料滞留時間及資料間隔時間。其中業務延遲指目前資料時間減去最後一條資料的時間,資料滞留時間指資料實時計算的時間減去eventime,資料間隔時間指業務延時減去資料滞留時間。Source的TPS資料是指直接讀取資料源的資料,Source的RPS是指讀取TPS解析後的資料。
本地調試
需要從本地上傳對應的資料。
實時計算的使用限制
針對區域的限制,獨享模式僅支援華東1(杭州)、華東2(上海)、華南1(深圳)、華北2(北京)地區。針對CU的處理能力,實時計算目前在内部壓測場景下,一個CU的處理能力大約為:簡單業務時,例如,單流過濾、字元串變換等操作,1CU每秒可以處理10000條資料。複雜業務時,例如,JOIN、WINDOW、GROUP BY等操作,1CU每秒可以處理1000到5000條資料。針對作業、任務數量限制,單個項目下允許最多建立業務的個數為100。單個項目下允許最多的檔案夾的個數為50,層數最大不超過5層,單個項目下允許最多的UDX或JAR的個數為50,單個項目下允許最多注冊資料存儲的個數為50,單個作業允許最多的曆史儲存版本數為20。