本文重點介紹怎樣利用 阿裡雲InfluxDB® 和spark structured streaming來實時計算、存儲和可視化資料。下面将介紹如何購買和初始化阿裡雲InfluxDB®,擴充spark foreach writer,以及設計阿裡雲InfluxDB®資料庫時需要注意的事項。
關于時序資料的一些重要概念和如何購買阿裡雲InfluxDB®可以參考之前的文章<
阿裡雲InfluxDB®教你玩轉A股資料>和
官方文檔。這裡補充一下阿裡雲InfluxDB®提供的執行個體規格和管理帳号的建立。

目前,阿裡雲InfluxDB®大緻提供2C8G/4C16G/8C32G/16C64G/32C128G/64C256G等大緻6種規格,每種規格的讀寫能力參考如上圖所示。阿裡雲InfluxDB®開放了開源版的幾乎全部功能,使用者可以在控制台建立管理者帳号,該帳号可以通過用戶端和SDK進行所有的操作。
Writing Data From Spark
Spark是目前大資料處理領域中最流行、最高效的開源工具,通過spark structured streaming寫資料到InfluxDB的開源擴充卡主要有
chronicler和
reactive-influx。chronicler與reactive-influx的差別是,在寫入資料點之前,chronicler必須要将資料格式轉換成influxdb行協定,在處理大量field字段和字元串值時會變得相當棘手,相較而言reactive-influx比較友善。
在sbt項目中引入reactive-influx:
libraryDependencies ++= Seq(
"com.pygmalios" % "reactiveinflux-spark_2.11" % "1.4.0.10.0.5.1",
"com.typesafe.netty" % "netty-http-pipelining" % "1.1.4"
) InfluxDB entry 配置,其中阿裡雲InfluxDB®内網和公網的URL可以在控制台上找到:
reactiveinflux {
url = "ts-xxxxx.influxdata.rds.aliyuncs.com:3242/"
spark {
batchSize = 1000 // No of records to be send in each batch
}
} 擴充spark foreach writer, enable spark stuctured streaming 向阿裡雲InfluxDB®寫資料的僞代碼如下:
import com.pygmalios.reactiveinflux._
import com.pygmalios.reactiveinflux.spark._
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.joda.time.DateTime
import com.pygmalios.reactiveinflux.{ReactiveInfluxConfig, ReactiveInfluxDbName}
import com.pygmalios.reactiveinflux.sync.{SyncReactiveInflux, SyncReactiveInfluxDb}
import scala.concurrent.duration._
class influxDBSink(dbName: String) extends org.apache.spark.sql.ForeachWriter[org.apache.spark.sql.Row] {
var db:SyncReactiveInfluxDb = _
implicit val awaitAtMost = 1.second
// Define the database connection here
def open(partitionId: Long, version: Long): Boolean = {
val syncReactiveInflux =
SyncReactiveInflux(ReactiveInfluxConfig(None))
db = syncReactiveInflux.database(dbName);
db.create() // create the database
true
}
// Write the process logic, and database commit code here
def process(value: org.apache.spark.sql.Row): Unit = {
val point = Point(
time = time, // system or event time
measurement = "measurement1",
tags = Map(
"t1" -> "A",
"t2" -> "B"
),
fields = Map(
"f1" -> 10.3, // BigDecimal field
"f2" -> "x", // String field
"f3" -> -1, // Long field
"f4" -> true) // Boolean field
)
db.write(point)
}
// Close connection here
def close(errorOrNull: Throwable): Unit = {
}
} 引入Writer:
val influxWriter = new influxDBSink("dbName")
val influxQuery = ifIndicatorData
.writeStream
.foreach(influxWriter)
.outputMode("append")
.start() 可視化
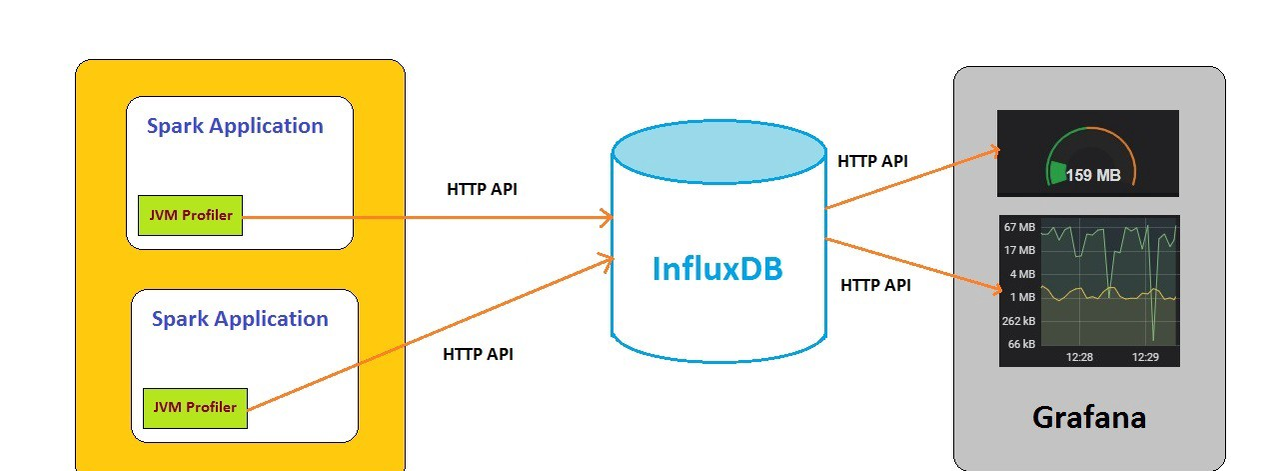
資料寫入InfluxDB之後,便可以利用各種工具進行資料可視化,如Grafana,Chronograf等。一個簡單的可視化展示如下:
目前阿裡雲InfluxDB®已經自帶Grafana資料可視化,使用者隻需要在控制台一鍵開通既可,具體可以參考<
5分鐘快速完成監控系統搭建之實踐篇>
總結
目前InfluxDB已經在阿裡雲完全托管,被使用者廣泛使用。随着商業化時間的發展,我們在提高穩定性和性能的同時,功能也一步步豐富起來。目前已經提供了TIG(Telegraf/InfluxDB/Grafana)生态,下一步将完全相容TICK(Telegraf/InfluxDB/Chorograf/Kapacitor)生态。覆寫的業務場景包括DevOps監控、車聯網、智慧交通、金融和IOT傳感器資料采集,歡迎大家試用并提供意見。
阿裡雲InfluxDB®為使用者提供7*24小時服務,歡迎加入下面的釘釘群咨詢。