自然語言處理屬于人工智能領域,它将人類語言當做文本或語音來處理,以使計算機和人類更相似,是人工智能最複雜的領域之一。 由于人類的語言資料格式沒有固定的規則和條理,機器往往很難了解原始文本。
要想使機器能從原始文本中學習,就需要将資料轉換成計算機易于處理的向量格式,這個過程叫做詞表示法。
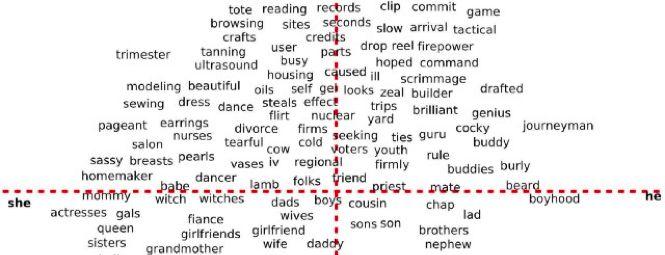
詞向量
詞表示法在向量空間内表達詞語。 是以,如果詞向量之間距離較近,這就意味着這些詞是互相關聯的。 在上圖中,可以看到與女性有關的詞語聚集在左邊,而與男性有關的詞語聚集在右邊。 是以,如果我們給出“耳環”這種詞語,電腦會把它和女性聯系起來,這在邏輯上是正确的。
語言的詞彙量很大,人類難以對其進行一一分類和辨別; 是以我們需要使用無監督學習技術,該技術可以獨立學習詞語的上下文。 無監督學習是指: 沒有标注的訓練資料集,需要根據樣本間的規律統計對樣本進行分析,常見如任務聚類等。 Skip-gram就是一種無監督學習技術,常用于查找給定單詞的最相關詞語。
Skip-gram用于預測與給定中心詞相對應的上下文詞。 它和連續詞袋模型(CBOW)算法相反。 在Skip-gram中,中心詞是輸入詞(input word),上下文詞是輸出詞(output word)。 因為要預測多個上下文詞,是以這一過程比較困難。

Skip-gram示例
給定 “sat” 一詞後,鑒于sat位于0位,我們會嘗試在-1位上預測單詞 “cat” ,在3位上預測單詞 “mat” 。 我們不預測常用詞和停用詞,比如 “the”。
**架構
Skip-gram模型架構
上圖中,w(t)就是中心詞,也叫給定輸入詞。 其中有一個隐藏層,它執行權重矩陣和輸入向量w(t)之間的點積運算。 隐藏層中不使用激活函數。 現在,隐藏層中的點積運算結果被傳遞到輸出層。 輸出層計算隐藏層輸出向量和輸出層權重矩陣之間的點積。 然後用softmax激活函數來計算在給定上下文位置中,單詞出現在w(t)上下文中的機率。
使用到的變量
- 在資料庫或文本中出現的特殊單詞的彙總詞典。 這個詞典就叫做詞彙量,是系統的已知詞。 詞彙量用字母“v”來表示。
- “N”代表隐藏層中神經元的數量。
- 視窗大小就是預測單詞的最大的上下文位置。 “c” 代表視窗大小。 比如,在給定的架構圖中視窗大小為2,是以,我們會在 (t-2), (t-1), (t+1) 和 (t+2) 的上下文位置中預測單詞。
- 上下文視窗是指會在給定詞的範圍内出現的、要預測的單詞數量。 對于2*c的并且由K表示的視窗大小來說,上下文視窗值是該視窗大小的兩倍。 給定圖像的上下文視窗值是4。
- 輸入向量的次元等于|V|。 每個單詞都要進行one-hot編碼。
- 隐藏層的權重矩陣(W)的次元是[|V|, N]。 “||” 是把數組值還原的模函數。
- 隐藏層的輸出向量是H[N]。
- 隐藏層和輸出層之間的權重矩陣 (W’) 次元是[N,|V|]。
- W’和H之間的點積生成輸出向量U[|v|]。
N = 上下文視窗
工作步驟
- 利用one-hot編碼将單詞轉換為向量,這些向量的次元是 [1,|v|]。
one-hot編碼
- 單詞w(t)從|V|神經元被傳遞到隐藏層。
- 隐藏層執行權重向量W[|v|, N] 和輸入向量w(t)之間的點積運算。 這裡,我們可以總結出: 第(t)行的W[|v|, N] 會輸出(H[1, N])。
- 謹記: 隐藏層不使用激活函數,是以H[1,k] 會直接傳遞到輸出層。
- 輸出層會執行 H[1, N] 和 W’[N, |v|] 之間的點積運算,并給出向量 U 。
- 現在,要得出每個向量的機率,我們要使用softmax函數,因為每次疊代都得出輸出向量U,這是一種one-hot編碼模式。
- 機率最大的那個單詞就是最終結果。 如果在指定上下文位置中預測的單詞是錯誤的,我們會使用反向傳播算法來修正權重向量W和W’。
以上步驟對字典中的每個單詞w(t) 都要執行。 而且,每個單詞w(t) 會被傳遞K次。 是以我們可以得知,正向傳播算法在每段時間内會執行 |v|*k次。
機率函數
Softmax機率
w(c, j) 是在第c個上下文位置上預測的第j個單詞; w(O, c)是在第c個上下文位置上出現的實際單詞; w(I)是唯一的輸入詞; u(c, j)是在第c個上下文位置上預測單詞時,U向量的第j個值。
損失函數
由于我們想在第c個上下文位置預測w(c, j) 時實作機率最大化,可以使用損失函數L。
優勢
- Skip-gram是一種無監督學習技術,是以它可以用于任何原始文本。
- 相比于其他單詞轉向量表達法,Skip-gram需要的記憶更少。
- 它隻需要兩個次元為[N, |v|]而不是[|v|, |v|]的權重矩陣。 而且通常情況下,N約為300,|v| 則約為數百萬。
劣勢
- 找到N和c的最佳值很困難。
- Softmax函數計算耗費的時間很長。
- 訓練這個算法耗時較長。