前言
傳統商業關系資料庫都聲稱可以做到故障恢複後不丢資料(即RPO為0),跟故障前的資料狀态是強一緻的,實際是否一定如此? 開源資料庫MySQL在金融核心業務都不敢用,最重要的一個原因是做不到不丢資料。但是有些基于MySQL修改的資料庫為何又說自己是強一緻的呢?新興的分布式資料庫OceanBase聲稱是金融級的分布式關系型資料庫,強一緻,絕對不丢資料,這個是真的嗎?
本文分為上下兩篇。
上篇分析傳統關系資料庫Oracle/MySQL在應對故障時保障資料不丢失的機制,以及分析PolarDB和AliSQL在這方面曾經探索的改進措施。
下篇分析螞蟻的OceanBase在資料安全方面的創新之處。
OceanBase簡介
叢集
OceanBase是螞蟻金服完全自主研發的通用的分布式關系型資料庫。OceanBase以叢集的形式存在,至少三個節點分布在三個區域(Zone),每個節點上運作一個單程序程式,程序名 observer。每個observer程序都包含兩個子產品:SQL引擎和存儲引擎,是以每個節點地位基本是平等的。稍微特殊的是每個Zone裡會有一個節點的observer内還會運作總控服務,三個總控服務内容一樣,角色上會有一個Leader兩個Follower,隻有Leader提供服務。
OceanBase叢集支援多租戶管理,租戶就是給到業務的執行個體,租戶的使用體驗,目前對外版本會感覺像MySQL,隻是因為OceanBase相容了MySQL的連接配接協定和功能,絕對不是用MySQL代碼或者其他開源資料庫代碼修改的。
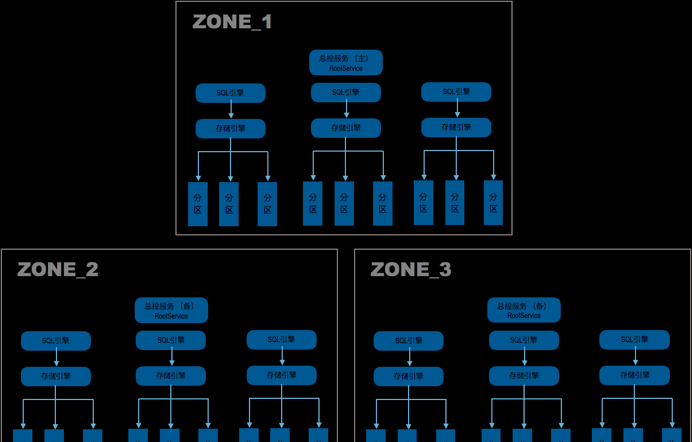
分區
OceanBase的資料存在每個節點上,observer通過分區管理資料。分區是資料的子集,一個非分區表就是一個分區,一個分區表包含多個分區。一個分區不能跨節點,分區表的不同分區可以跨節點。是以分區表可以做水準跨節點擴充。
分區是資料的子集,是高可用的最小粒度。分析OceanBase是否丢資料,隻要分析分區的資料寫是否會丢就行。
OceanBase的讀寫模式
OceanBase在初次讀入一行資料時會将該行所在塊讀入到記憶體的
Block Cache
中,後面修改的時候并不是直接修改這個block,而是在另外一塊記憶體中配置設定少量空間記錄這筆修改。并且隻記錄變化的部分,這部分也稱為增量資料(Memtable)。前面在
Block Cache
裡的資料稱為基線資料(永遠不變)。同一行記錄如果反複修改多次,多個增量會以連結清單形式挂在該記錄下。

OceanBase這種設計導緻業務修改産生的髒塊的量遠小于傳統資料庫,于是OceanBase就索性把這些增量資料盡可能的一直保留在緩存中,也是盡可能的推遲寫入到磁盤上。當然,這個增量資料最終是要落盤的。在落盤的時候,增量資料會當機曆史版本(後續寫會追加新的版本),然後跟其對應的基線資料在記憶體中進行合并,生成SSTable(
Sorted String Table
)格式寫入到磁盤資料檔案中。這個「合并」動作對資源影響不可忽視,是以OceanBase會盡可能的推遲合并到低峰期(時間是使用者設定的)。如果增量記憶體使用率超過門檻值,OceanBase會将增量資料直接以SSTable的格式臨時寫入到磁盤上。這個動作叫「轉儲」對資源消耗小很多,釋放了記憶體。轉儲可以看作資料另一種形式的落盤。
OceanBase的事務
初次聽說OceanBase增量資料一天隻落盤一次的這個設計時,難免會擔心如果節點當機了豈不是會丢資料。實際肯定不會,因為OceanBase在記錄這些增量之前也是遵循前面提到WAL機制,先生成相關的事務日志儲存在日志緩沖區裡。跟Oracle不同的是OceanBase的這些事務日志在事務送出之前會一直在日志緩沖區裡。此時節點若當機,由于事務并沒有送出,對業務而言也沒有資料丢失。當事務送出的時候,OceanBase也會先做事務日志的持久化動作。
從這個設計可以看出OceanBase事務兩個特點。第一是對大事務不是很友好。太大的事務其事務日志可能會占用不少記憶體空間。OceanBase 2.x版本已經在針對大事務做優化。第二就是OceanBase沒有Undo,也不需要Undo。假設業務事務復原了,在OceanBase裡隻有一些清理邏輯,是以會很快。
OceanBase的當機恢複
OceanBase節點當機後,該節點上可能有部分資料(分區)的通路會受影響,但OceanBase叢集會很快恢複這些分區的通路。這是OceanBase的可用性特性,不是本文重點這裡就不展開。這裡接着分析這個宕掉的節點起來後的恢複邏輯。跟傳統關系型資料庫一樣,它會讀取事務日志,重做事務。但是不同的地方在于這個時候observer不需要再次讀入基線資料,而隻需要根據事務日志在增量記憶體裡建構相關分區的Memtable。這個過程也是非常快的。隻有在相關分區再次被業務讀取時,其對應的基線資料所在塊才會被再次讀入到
Block Cache
中。
提前說明一下,OceanBase的備副本應用事務日志邏輯也是同理。
OceanBase的副本複制技術
跟Oracle一樣,光支援WAL是不足以保障資料安全,OceanBase還要設法保障事務日志的可靠性。除了使用DirectIO持久化到本節點磁盤外,也需要持久化到其他節點上。
跟傳統關系資料庫主備兩副本架構不一樣,OceanBase選擇了三副本架構,即每份資料至少有三份。當然這裡三副本并不是唯一選擇,也可以是五副本,七副本,但不能是兩副本,四副本等。其原因是如果副本數是偶數,會有傳統雙機房容災的腦裂問題。腦裂問題的本質就是全體成員在局部通信中斷故障時無法就哪個節點接管服務作出一緻性決議。成員數是奇數,才有可能形成多數派。這裡就以三副本為例進行分析。
副本就是分區的别稱,一個分區有三份資料,每份是一個副本。副本的内容除了資料還有事務日志。在這裡我們隻關心事務日志部分。三個副本在角色上是1個Leader(類似于主副本)2個Follower(類似于備副本)。隻有Leader副本才會對外提供讀寫服務,這樣就規避了單個分區多個節點同時寫入的問題。但是注意每個分區隻能單點寫入跟OceanBase叢集多個節點寫入并不沖突。因為Leader副本是可以分散到所有節點(OBServer)上。跟傳統關系資料庫一樣,OceanBase維持三副本資料的同步是靠傳輸事務日志(Redo)機制實作的。
是以,為了保障事務日志的可靠性,OceanBase要把Leader副本上的事務日志持久化到本機和其他兩個Follower副本上。宏觀上表現就是可能存在各個節點彼此互相傳輸事務日志。這個跟MySQL的
Master-Master
架構裡雙向複制并不完全一樣。 我們重點看看OceanBase如何認定事務日志可靠了。
政策一,就是所有副本成員都接收到事務日志并持久化到各自節點磁盤就是可靠的。這個确實可靠,但是太過嚴格,會降低事務送出性能。
政策二,就是其他多個Follower副本至少一個接收到事務日志并持久化到其節點磁盤就是可靠的。在三副本裡這個結論通常也是可以的, 但是它是能忍受有Follower副本可以不持久化成功,那麼就隻有那個成功的Follower副本能作為備選節點。尤其在五副本的情況下,某個Follower副本的地位特殊會加大風險(如果這個Follower副本先挂了,Leader就沒有備用副本了)。上篇提到的Oracle一主多備高安全的複制模式和MySQL一主多備半同步的複制技術就是這個政策。這個政策有時候也不可靠。
政策三,使用Paxos協定,各個副本成員就事務日志持久化到磁盤進行表決。隻要一半以上成員投票OK,Leader副本上的事務就可以繼續送出了,Follower副本才開始應用Redo。這個協定是強制性限制,不夠一半成員就會表決失敗,Leader副本上事務就會復原。這裡沒有類似Oracle或者MySQL的同步降級的做法。此外,剩餘少數派成員最終也是要表決成功的,否則就是一個異常狀态。
OceanBase選擇政策三,會盡力自動去保障三副本成員狀态的正常,否則就會告警等運維處理。這點也是強制性的限制,也是跟傳統關系資料庫不一樣的地方。
容災場景RPO分析
故障轉移屬于高可用和容災範疇,表面上看跟本文主題資料強一緻無關,實際上如果應對方法(即主備切換)不當也可能間接導緻資料丢失,是以這裡也分析一下。
主備切換分析
傳統關系資料庫的主備通常是同機房或者同城雙機房。 主備切換多需要人工操作,運維開發技術實力強的團隊可能還開發了針對Oracle或MySQL自動切換的工具。
如果是DBA切換,會依賴DBA的經驗能力,當時的狀态等。熟練的DBA能夠切換成功,也要花費一些時間,Oracle是分鐘級别以上,MySQL順利的話可以幾秒。重大業務資料庫切換時,如果對備庫資料是否有丢失不确認時,還需要等待上司做決策。在實際操作時很多DBA都有過手心冒汗的經曆。
如果是工具切換,在面對腦裂情形時工具可能會導緻兩個主庫出現。又或者當主備資料已經不一緻的時候工具拒絕切換還好,如果強制切換成功就導緻資料丢失。工具自身的可靠性也需要額外驗證。
傳統關系資料庫,特别是MySQL,在做主備架構或異地容災時,為了性能放棄了一些底線。比如說事務日志務必落盤,事務日志務必同步在備機落盤等。使得主備資料可能面臨不一緻的情形,而在故障的時候就讓「切換」這個動作變得更加艱難。而OceanBase在事務日志持久化到本機和其他機器上的流程是嚴格規定的,不存在修改某個參數就可以犧牲安全性而去提升性能。
OceanBase的「切換」
由于OceanBase的Leader副本可以分布在所有節點上,是以節點就沒有主備之說。同時,OceanBase單節點故障時,也隻有局部資料通路出現故障,具體就是該節點上的Leader副本的讀寫出現故障(前提是沒有針對Follower副本的通路設定)。
OceanBase的切換的粒度是分區級别的。如果有1000個Leader副本,那就有1000個分區的切換事件(在OceanBase裡叫選主,會批量選主)。OceanBase保障選出來的新Leader擁有老Leader的全部事務日志以及資料;否則就選舉失敗。通常一個分區選舉失敗并不影響其他分區的選舉。
對運維而言,OceanBase叢集出現節點故障,隻要故障範圍沒有波及到業務資料的多數派,在可用性恢複方面運維是不需要人為處理的。有可能等運維收到告警并檢視告警細節時資料通路就已經恢複了。這個對運維的體驗非常好。
異地容災的RPO分析
傳統關系資料庫的異地容災,是不能保證資料絕對不丢的,因為主庫到異地的備庫的資料同步一定是異步高性能模式。 OceanBase叢集可以異地部署,隻要保證多數派成員之間的網絡延時滿足業務需求即可。比如說在螞蟻有些業務是兩地三中心三副本(杭州兩個機房,上海一個機房),有些業務是三地五中心五副本(杭州兩機房,上海兩機房,深圳一個機房)。
如果隻是做異地容災,用OceanBase叢集就足夠了,隻是這樣沒有充分發揮OceanBase優勢和充分利用機器資源。螞蟻的業務跟OceanBase一起做分布式拆分,中間件産品跟OceanBase叢集一起實作了異地多活。在保證RPO=0的前提下還提高了機器的使用率,提升了業務處理能力。
後記
本文上下篇詳細分析了事務日志的可靠性對RPO名額的重要性,以及分析了OceanBase在處理這個細節上是非常嚴格的,不犧牲安全性去提升性能,盡管OceanBase在性能上離Oracle資料庫還有不少差距。
有關OceanBase的使用經驗技巧問題等等,都可以來OceanBase論壇( https://bbs.aliyun.com/thread/439.html )看看。
參考
本文作者:MQ4096
文章轉自微信公衆号:技術閑談.原文
連結位址