這是另一套基于CRF的詞法分析系統,類似感覺機詞法分析器,提供了完善的訓練與分析接口。
CRF的效果比感覺機稍好一些,然而訓練速度較慢,也不支援線上學習。
預設模型訓練自OpenCorpus/pku98/199801.txt,
随hanlp 1.6.2以上版本釋出。
語料格式等與感覺機詞法分析器相同,請先閱讀《感覺機詞法分析器》。
中文分詞 訓練CRFSegmenter segmenter = new CRFSegmenter(null);
segmenter.train("data/test/pku98/199801.txt", CWS_MODEL_PATH);
輸出為HanLP私有的二進制模型,有興趣的話還可以通過指令導出為相容CRF++的純文字格式。
java -cp hanlp.jar com.hankcs.hanlp.model.crf.crfpp.crf_learn -T cws.bin cws.txt
與CRF++相容由于C++的運作效率和記憶體效率優于Java,是以推薦直接利用CRF++執行大規模訓練。
首先将人民日報語料轉換為CRF++格式:
segmenter.convertCorpus("data/test/pku98/199801.txt", "data/test/crf/cws-corpus.tsv");
然後準備一份特征模闆,或者直接用HanLP預設的:
segmenter.dumpTemplate("data/test/crf/cws-template.txt");
接着用CRF++的crf_learn執行訓練:
crf_learn cws-template.txt cws-corpus.tsv cws -t
·此處必須使用-t指令CRF++輸出文本格式的模型cws.txt
·HanLP隻相容CRF++的文本模型,不相容二進制
将cws.txt格式的模型傳入CRFSegmenter或CRFLexicalAnalyzer的構造函數即可建立分詞器,同時HanLP會自動建立二進制緩存.txt.bin,下次加載耗時将控制在數百毫秒内。
預測可通過如下方式加載:
CRFSegmenter segmenter = new CRFSegmenter(CWS_MODEL_PATH);
List<String> wordList = segmenter.segment("商品和服務");
System.out.println(wordList);
不傳入模型路徑時将預設加載配置檔案指定的模型。
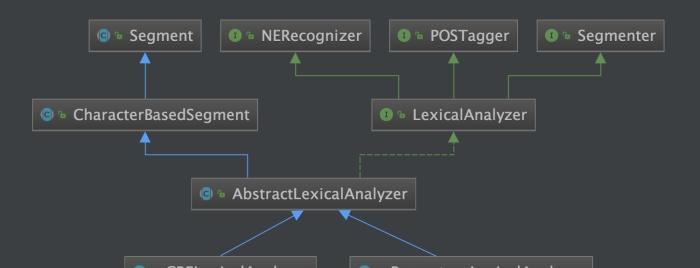
詞性标注CRF詞性标注器的訓練與加載與中文分詞類似,對應CRFPOSTagger。
命名實體識别CRF命名實體識别也是類似的用法,對應CRFNERecognizer。
CRF詞法分析器訓練了1至3個模型後,可以構造CRF詞法分析器:
/**
* 構造CRF詞法分析器
*
* @param cwsModelPath CRF分詞器模型路徑
* @param posModelPath CRF詞性标注器模型路徑
* @param nerModelPath CRF命名實體識别器模型路徑
*/
public CRFLexicalAnalyzer(String cwsModelPath, String posModelPath, String nerModelPath) throws IOException
* 加載配置檔案指定的模型
* @throws IOException
public CRFLexicalAnalyzer() throws IOException
構造後可以調用analyze接口或與舊接口相容的seg:
CRFLexicalAnalyzer analyzer = new CRFLexicalAnalyzer();
String[] tests = new String[]{
"商品和服務",
"上海華安工業(集團)公司董事長譚旭光和秘書胡花蕊來到美國紐約現代藝術博物館參觀",
"微軟公司於1975年由比爾·蓋茲和保羅·艾倫創立,18年啟動以智慧雲端、前端為導向的大改組。" // 支援繁體中文
};
for (String sentence : tests)
{
System.out.println(analyzer.analyze(sentence));
System.out.println(analyzer.seg(sentence));
}
在1.6.2以上版本中,所有的詞法分析接口都同時支援簡繁。
![Java String.format方法的簡單使用[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)