神經網絡通過大量的參數模拟各種繁多的任務,并能拟合各種複雜的資料集。這種獨特的能力使其能夠在許多難以在“傳統”機器學習時代取得進展的領域——例如圖像識别、物體檢測或自然語言處理等領域表現優異。然而,有時候,最大的優點也是潛在的弱點。模型在學習過程時,如果缺乏控制可能會導緻過拟合(overfitting)現象的發生——神經網絡模型在訓練集上表現很好,但對新資料預測時效果不好。了解過拟合産生的原因以及防止這種現象發生的方法對于成功設計神經網絡而言顯得至關重要。
如何知道模型産生過拟合?
訓練(train sets)、開發(dev sets)和測試集(test sets)
在實踐中,檢測模型過拟合是困難的。很多時候,将訓練好的模型上線後才意識到模型出現問題。事實上,隻有通過新資料的建議,才能確定一切正常。但在訓練期間,應盡量表示真實情況。是以,比較好的作法是将資料集劃分為三個部分——訓練集、開發集(也稱為交叉驗證集)和測試集。建構的模型僅通過訓練集來學習,驗證集用于跟蹤訓練進度并根據驗證集上的結果優化模型。同時,在訓練過程結束後使用測試集來評估模型的性能。使用全新的資料可以讓我們對算法的仿真情況有一個客觀的看法。
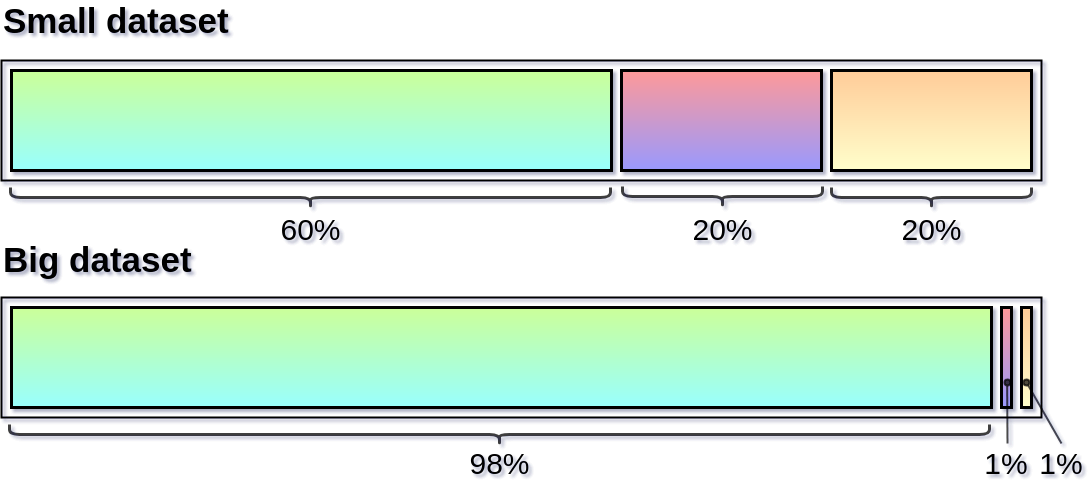
圖1.劃分資料集的推薦方法
確定驗證集和測試集來自同一分布以及它們能夠準确地反映希望将來收到的資料非常重要。隻有這樣,才能確定在學習過程中做出的決策更接近好的解決方案。那麼如何分割手上的資料集呢?最常推薦的拆分方法之一是按照
60/20/20
的比例拆分,但在大資料時代,當資料集是數百萬條目時,這種固定比例的劃分已經不再合适。簡而言之,一切都取決于使用的資料集的大小,如果有數以百萬計的條目可供使用,或許最好的劃分方法是按照
98/1/1
的比例劃分。注意:開發集和測試集應該足夠大,以使得對建構的模型的性能有很高的信心。根據資料大小劃分資料集的推薦方法如圖1所示。
偏差和方差
當準備好資料集後,需要使用工具來評估模型的性能。然而,在得出任何結論之前,我們應該熟悉兩個新的概念——偏差(bias)和方差(variance)。為了讓我們更好地了解這個複雜的問題,這裡舉一個簡單的例子。假設資料集由位于二維空間中的兩類點組成,如圖2所示。

圖2.資料集的可視化
由于這是一個簡單的示範用例,這次就沒有測試集,僅使用訓練集和驗證集。接下來,我們準備三個模型:第一個是簡單的線性回歸,另外兩個是由幾個密集連接配接層建構的神經網絡。在圖3中,我們可以看到使用這些模型定義的分類邊界。右上角的第一個模型非常簡單,是以具有較高的偏差,即它無法找到要素和結果之間的所有重要連結,這是由于資料集中有很多噪音,是以簡單的線性回歸無法有效地處理它。從圖中可以看到,在神經網絡模型上表現得更好,但左下角的模型太緊密地拟合資料,這使得它在驗證集上表現得更糟,這意味着它具有很大的方差——它适合噪聲而不是預期的輸出。在最後的模型中,通過使用正則化來減輕這種不期望的影響。
圖3.建立的分類邊界:右上角——線性回歸; 左下角——神經網絡; 右下角——正則化的神經網絡
上述舉的例子很簡單,隻有兩個特征。當我們在多元空間中操作時,需要使用包含數十個特征的資料集,這種情況該怎麼辦?這個時候需要比較使用訓練集和交叉驗證集計算得到的誤內插補點。當然,最佳情況是這兩組的錯誤率都很低。主要問題是如何定義低錯誤率——在某些情況下它可以是1%,而在其他情況下它可以高達10%或更大。在訓練神經網絡時,設立一個比較模型性能的基準是有所幫助的。通常,這取決于執行此任務的人員能力水準。然後嘗試確定設計的算法在訓練期間有一個接近參考水準的誤差。如果已經實作了這個目标,但是在驗證集上驗證錯誤率時,錯誤率會顯著增加,這可能意味着模型存在過拟合(高方差)。另一方面,如果模型在訓練集和交叉驗證上表現都不佳,那麼它可能太弱并且具有高偏差。當然,這個問題會更複雜,而且涉及的面也更廣,在這裡不做讨論,感興趣的讀者可以閱讀NG的新書。
防止過拟合的方法
介紹
當我們的神經網絡具有較高的方差時,這裡有很多方法可以有所幫助。比如,非常普遍的方法——擷取更多資料,這種方法一般每次都運作良好。還有一些操作,例如正則化,但這種方法需要一些經驗和技巧,因為對神經網絡施加太多限制可能會損害其有效學習的能力。現在讓我們試着看一下減少過拟合的一些最流行的方法,并讨論它們起作用的原因。
L1和L2正則化
當需要減少過拟合時,應該嘗試的第一種方法是正則化。這種方法涉及到在損失函數中添加一個額外的式子,這會使得模型過于複雜。簡單來說,就是在權重矩陣中使用過高的值,這樣就會嘗試限制其靈活性,同時也鼓勵它根據多種特征建構解決方案。這種方法的兩個流行版本是L1-最小絕對偏差(LAD)和L2-最小二乘誤差(LS),相應的公式如下。在大多數情況下,L2正則化是首選,因為它将不太重要的特征的權重值減小到零。但是在處理具有大量異常值的資料集時不是首選。
現在看一下在偏差和方差的例子中使用的兩個神經網絡。正如之前提到的,使用正則化來消除過拟合。在三維空間中可視化權重矩陣并比較在有正則化和沒有正則化的模型之間獲得的結果如下圖所示。此外,還使用正則化對許多模型進行了模拟,改變λ值以驗證其對權重矩陣中包含的值的影響。矩陣行和列索引對應于水準軸值,權重為垂直坐标值。
圖4.可視化沒有和具有正則化的模型權重矩陣
Lambda因子及其影響
在前面提到的L1和L2兩個版本中的正則化公式中,引入了超參數λ (也稱為正則化率)。在選擇其值時,試圖在模型的簡單性和拟合訓練資料之間達到最佳點。增加λ值也會增加正則化效應。在圖4中可以注意到,沒有正則化的模型獲得的平面,以及具有非常低λ的模型其系數值非常“紊亂”,有許多具有重要價值的峰值。在應用具有較高超參數值的L2正則化之後,該平面圖是平坦的。最後,可以看到将lambda值設定為0.1或1會導緻模型中權重值急劇下降。
dropout
另一種非常流行的神經網絡正則化方法是dropout。這個想法實際上非常簡單——神經網絡的每個單元(屬于輸出層的那些單元)都被賦予在計算中被暫時忽略的機率p。超參數p稱為丢失率,通常将其預設值設定為0.5。然後,在每次疊代中,根據指定的機率随機選擇丢棄的神經元。是以,每次訓練會使用較小的神經網絡。下圖顯示了使用dropout操作的神經網絡的示例。從圖中可以看到,在每次疊代過程中是随機停用來自第二和第四層神經元。
圖5:dropout可視化
這種方法的有效性是非常令人驚訝。畢竟,在現實世界中,如果經理每天随機選擇員工并将其送回家,工廠的生産率是不會提高的。讓我們從單個神經元的角度來看這個問題,在每次疊代中,任何輸入值都可能會被随機消除,神經元會嘗試平衡風險而不會支援任何特征。結果,權重矩陣值的分布變得更均勻。
提前停止(early stopping)
下圖顯示了在後續的學習過程疊代期間在測試和交叉驗證集上得到的準确度值的變化情況。從中可以看到,最終得到的模型并不是最好的模型。最終得到的結果比150個epoch後的情況要糟糕得多。為什麼不在模型開始過拟合之前就中斷學習過程?這一觀察啟發了一種流行的過拟合減少方法,即提前停止(early stopping)。
圖6.神經網絡學習過程中後續時期的準确度值的變化
在實踐中,每疊代幾次就對模型進行檢查它在驗證集上的工作情況,并儲存每個比以前所有疊代時都要好的模型。此外,還設定最大疊代次數這個限制,超過此值時停止學習。盡管提前停止可以顯著改善模型的性能,但在實踐中,其應用極大地使得模型的優化過程變得複雜,很難與其他正常技術結合使用。
結論
掌握如何确認模型是否過拟合對于建構神經模型是很重要的,掌握防止過拟合發生的解決方法也是最基本的。受限于篇幅,本文中沒有進行較長的描述,但總結了相關内容,具體的操作技巧還需要各位在實踐中進行嘗試。
作者資訊
Piotr Skalski,熱愛機器學習和資料科學
本文由阿裡雲雲栖社群組織翻譯。
文章原标題《Preventing Deep Neural Network from Overfitting》,譯者:海棠,審校:Uncle_LLD。
文章為簡譯,更為詳細的内容,
請檢視原文。