移動裝置的計算資源和能耗預算都很有限,是以模型壓縮對于在移動裝置上部署神經網絡模型至關重要。傳統的模型壓縮技術依賴手工設計的啟發式和基于規則的政策,需要領域專家探索較大的設計空間,在模型大小、速度和準确率之間作出權衡。本論文提出了适用于模型壓縮的 AutoML(AMC),利用強化學習提供模型壓縮政策,優化傳統的基于規則的壓縮政策。
在許多機器學習應用(如機器人學、自動駕駛及廣告排名)中,深度神經網絡受到延遲、能耗及模型大小等因素的限制。人們提出了很多模型壓縮方法來提高神經網絡的硬體效率 [26 ,19 ,22]。模型壓縮技術的核心是決定每一層的壓縮政策,因為各層的備援情況不同,通常需要手工設計的啟發方法和領域專業技術來探索模型尺寸、速度及準确率之間的大型設計空間權衡。設計空間如此之大,以至于手工設計的方法通常不是最優解,手動模型壓縮也非常耗時。為了解決這一問題,本文旨在為任意網絡自動尋找壓縮政策,以達到優于基于規則的手工模型壓縮方法的性能。
目前已有許多基于規則的模型壓縮啟發方法 [20,16]。例如,在抽取低級特征且參數最少的第一層中剪掉更少的參數;在 FC 層中剪掉更多的參數,因為 FC 層參數最多;在對剪枝敏感的層中減掉更少的參數等。然而,由于深度神經網絡中的層不是孤立的,這些基于規則的剪枝政策并不是最優的,也不能從一個模型遷移到另一個模型。神經網絡架構發展迅速,是以需要一種自動方法對其進行壓縮,以提高工程效率。随着神經網絡逐漸加深,設計空間的複雜度可達指數級,是以利用貪婪、基于規則的方法解決這一問題并不可行。是以,本文提出了針對模型壓縮的 AutoML(AutoML for Model Compression,AMC),該方法利用強化學習自動采樣設計空間并提高模型壓縮的品質。圖 1 展示了 AMC 引擎。壓縮網絡時,AMC 引擎通過基于學習的政策将此過程自動化,而不是依賴基于規則的政策和經驗豐富的工程師。
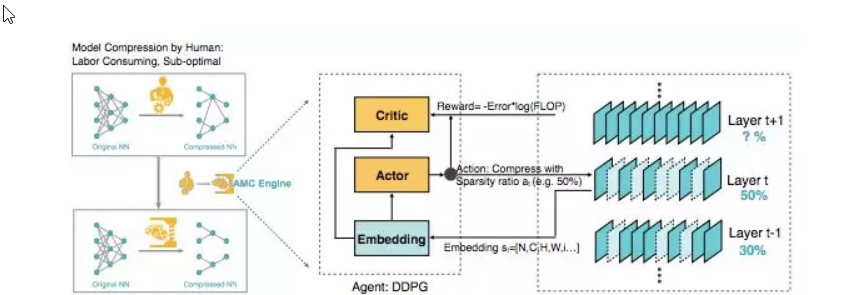
圖 1:AMC 引擎圖示。左:AMC 取代人類,使模型壓縮完全自動化,而且表現優于人類。右:将 AMC 構造成強化學習問題。作者逐層處理了一個預訓練網絡(即 MobileNet)。強化學習智能體(DDPG)從 t 層接收嵌入 s_t,輸出稀疏比率 a_t。用 a_t 對層進行壓縮後,智能體移動到下一層 L_t+1。評估所有層都被壓縮的修剪後模型的準确率。最後,獎勵 R 作為準确率和 FLOP 的函數被傳回到強化學習智能體。
在本文中,壓縮模型的準确率對每一層的稀疏性非常敏感,需要細粒度的動作空間。是以,作者沒有在離散空間中搜尋,而是提出了一種帶有 DDPG[32] 智能體的連續壓縮比控制政策,通過試驗和誤差來學習:在鼓勵模型收縮和加速的同時懲罰準确率損失。行為-評判結構也有助于減少差異,促進更穩定的訓練。具體來說,該 DDPG 智能體逐層處理網絡。對于每層 L_t,智能體接收一層嵌入 s_t,s_t 編碼該層的有用特性,然後輸出精确的壓縮比 a_t。用 a_t 壓縮 L_t 層後,智能體移動到下一層 L_t+1。所有壓縮層修剪模型的驗證準确率是在沒有微調的情況下進行評估的,該準确率可有效代表微調準确率。這種簡單的近似可以減少搜尋時間,而不必重新訓練模型,并提供高品質的搜尋結果。政策搜尋完成後,對最佳探索模型進行微調,以獲得最佳性能。
本文針對不同的場景提出了兩種壓縮政策搜尋協定。針對受延遲影響較大的人工智能應用(如移動 APP、自動駕駛汽車和廣告排名),本文提出了資源受限的壓縮,以便在給定最大量硬體資源(如 FLOP、延遲和模型大小)的情況下實作最佳準确率;對于品質至上的人工智能應用(如 Google Photos),本文提出了保證準确率的壓縮,以便在不損失準确率的情況下得到最小的模型。
作者通過限制搜尋空間來實作資源受限的壓縮,在搜尋空間中,動作空間(剪枝率)受到限制,使得被智能體壓縮的模型總是低于資源預算。對于保證準确率的壓縮,作者定義了一個獎勵,它是準确率和硬體資源的函數。有了這個獎勵函數,作者能夠在不損害模型準确率的前提下探索壓縮的極限。
為了證明其廣泛的适用性,作者在多個神經網絡上評估了該 AMC 引擎,包括 VGG [45], ResNet [21], and MobileNet [23],并測試了壓縮模型從分類到目标檢測的泛化能力。大量實驗表明,AMC 提供了比手工設計的啟發式政策更好的性能。對于 ResNet-50,作者把專家調優的壓縮比 [16] 從 3.4 倍提高到了 5 倍而不損失準确率。此外,該研究将 MobileNet 的 FLOP 減少了 2 倍,使最高準确率達到了 70.2%,這一數字的曲線比 0.75 MobileNet 的帕累托曲線(Pareto curve)更好。在 Titan XP 和安卓手機上,分别實作了 1.53 倍和 1.95 倍的加速。
論文:AMC: AutoML for Model Compression and Acceleration on Mobile Devices

論文連結:https://arxiv.org/pdf/1802.03494.pdf
摘要:移動裝置的計算資源和能耗預算都很有限,是以模型壓縮對于在移動裝置上部署神經網絡模型至關重要。傳統的模型壓縮技術依賴手工設計的啟發式和基于規則的政策,需要領域專家探索較大的設計空間,在模型大小、速度和準确率之間作出權衡,而這通常是次優且耗時的。本論文提出了适用于模型壓縮的 AutoML(AMC),利用強化學習提供模型壓縮政策。這一基于學習的壓縮政策優化傳統的基于規則的壓縮政策,因其具備更高的壓縮率,能夠更好地維持準确率,免除人類的手工勞動。在 4 倍每秒浮點運算次數縮減的情況下,在 ImageNet 上對 VGG-16 進行壓縮時,使用我們的壓縮方法達到的準确率比使用手工設計的模型壓縮政策的準确率高 2.7%。我們将該自動、一鍵式壓縮流程應用到 MobileNet,在安卓手機上得到了 1.81 倍的推斷延遲速度提升,在 Titan XP GPU 上實作了 1.43 倍的速度提升,而 ImageNet Top-1 準确率僅損失了 0.1%。
表 1:模型搜尋強化學習方法對比(NAS:神經架構搜尋 [57]、NT:網絡變換(Network Transformation)[6]、N2N:Network to Network [2] 和 AMC:AutoML for Model Compression。AMC 與其他方法的差別在于它無需微調和連續搜尋空間控制即可擷取獎勵,且能夠生成兼具準确率和适應有限硬體資源的模型。
3.3 搜尋協定
資源受限的壓縮。通過限制動作空間(每一層的稀疏率(sparsity ratio)),我們能夠準确達到目标壓縮率。我們使用下列獎勵函數:
通過調整獎勵函數獲得保證準确率的壓縮,我們可以準确找到壓縮的極限而不損失準确率。我們憑經驗觀察到誤差與 log(FLOP s) 或 log(#Param) [7] 成反比。受此啟發,我們設計了以下獎勵函數:
4 實驗
表 2:Plain-20、ResNet [21] 在 CIFAR-10 [28] 上的剪枝政策對比。R_Err 指使用通道剪枝的限制 FLOP 壓縮,R_Param 指使用微調剪枝的保證準确率壓縮。對于淺層網絡 Plain-20 和較深層的網絡 ResNet,AMC 顯著優于手動設計的政策。這說明無需微調也能實作高效壓縮。盡管 AMC 在模型架構上做了很多嘗試,但本文使用的是單獨的驗證集和測試集。實驗中未觀察到過拟合現象。
圖 2:在 2 倍每秒浮點運算次數的情況下,Plain-20 的剪枝政策對比。統一政策為每個層統一設定相同的壓縮率。淺層和深層政策分别大幅修剪較淺和較深的層。AMC 給出的政策看起來像鋸齒,類似于瓶頸結構 [21]。AMC 給出的準确率優于手工政策。
圖 4:本文中的強化學習智能體(AMC)可以在不損失準确率的前提下将模型修剪為與人類專家相比密度較低的模型(人類專家:在 ResNet50 上壓縮 3.4 倍。AMC:在 ResNet50 上壓縮 5 倍)。
表 3:基于學習的模型壓縮(AMC)優于基于規則的模型壓縮。基于規則的啟發方法不是最優方法。(參考資訊:VGG-16 的基線 top-1 準确率是 70.5%,MobileNet 是 70.6%,MobileNet-V2 是 71.8%)。
圖 5:(a)比較 AMC、人類專家、未修剪的 MobileNet 之間的準确率和 MAC 權衡。在帕累托最優曲線中,AMC 遙遙領先人類專家。(b)比較 AMC、NetAdapt、未修剪 MobileNet 之間的準确率和延遲權衡。AMC 大幅改善了 MobileNet 的帕累托曲線。基于 AMC 的強化學習在帕累托曲線上超越了基于啟發方法的 NetAdapt(推斷時間都是在谷歌 Pixel 1 上測量的)。
表 4:AMC 加速 MobileNet。之前利用基于規則的政策修剪 MobileNet 導緻準确率大幅下降 [31],但 AMC 利用基于學習的修剪就能保持較高的準确率。在谷歌 Pixel-1 CPU 上,AMC 實作了 1.95 倍的加速,批大小為 1,同時節省了 34 % 的記憶體。在英偉達 Titan XP GPU 上,AMC 實作了 1.53 倍的加速,批大小為 50。所有實驗中的輸入圖像大小為 224×224,蘋果與蘋果的比較不采用量化。
表 5:在 PASCAL VOC 2007 上用 VGG16 壓縮 Faster R-CNN。與分類任務一緻,AMC 在相同壓縮比的情況下,在目标檢測任務上也能獲得更好的性能。
原文釋出時間為:2018-09-16
本文作者:機器之心
本文來自雲栖社群合作夥伴“CVer”,了解相關資訊可以關注“CVer”。