LevelDB整體架構
LevelDB可以看作是Google BigTable的單機kv存儲引擎,它是一個kv型持久性存儲的C++程式庫。關于它的整體架構這裡不在詳述,可以參考文章
LevelDB的設計與實作,文章主要講述了LevelDB的全局結構,資料扭轉流程,系統中的資料布局,以及一些重要的結構等,可以通過這篇文章從宏觀上了解LevelDB。下面主要講述自己通過閱讀LevelDB源碼後,對它的一些了解。
源碼結構分析
源碼結構
下圖為閱讀LevelDB源碼後,對它的各個子產品之間的關系的一個抽象化的了解
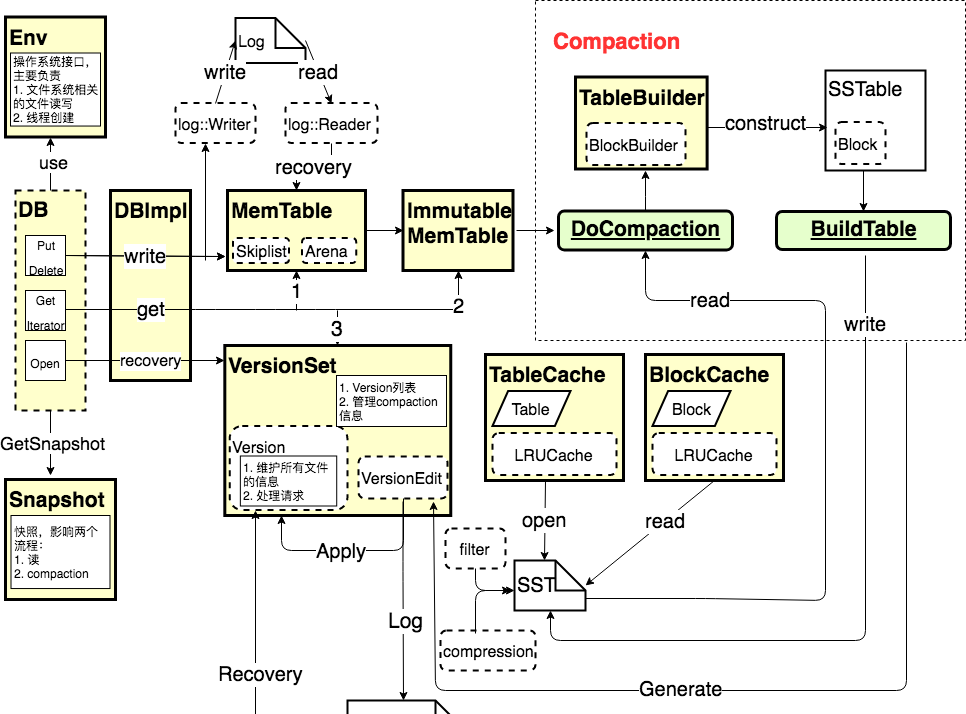
下面首先來了解各子產品,然後來通過一些重要流程來把各個子產品串聯起來
子產品說明
DB 和 DBImpl
DB是leveldb對外的子產品,它提供了對leveldb資料庫進行操作的接口。它提供的通路資料庫的接口有:
Open: 打開資料庫,擷取操作資料庫的對象指針。同時leveldb隻能單程序通路,程序間通過lock檔案來保證這一點,同時程序内通過記錄打開的db name來保證這一點
Put: 将(key,value)寫入資料庫
Write: 提供原子的批量寫操作
Delete: 删除某個key對應的entry,leveledb内部當作寫操作,用類型字段區分正常寫入操作和删除操作
Get: 擷取key對應的value
NewIterator: 資料庫的疊代器,可以用它進行scan操作
同時它還提供了一些其它操作接口,比較重要的有兩個:
GetSnapshot: 擷取目前DB狀态的快照,這樣使得讀操作能在DB目前狀态下進行,不受後續寫操作的影響
compactRange: 提供manual compact的接口,可以制定range去做compaction
DBImpl則提供了DB各個接口的具體實作,這裡就不在細述
Env
Env抽象化和作業系統相關的環境,這樣友善使用者定制。它主要提供了和檔案系統相關的接口,比如檔案建立,讀寫等。還提供了和線程相關的接口,主要用在使用background線程去做compaction的時候
VersionSet, Version, VersionEdit
- Version儲存目前磁盤以及記憶體中的檔案資訊,一般隻有一個version為”current version”。同時還儲存了一系列的曆史version,這些version的存在是因為有讀操作還在引用(iterator和get,Compaction操作後會産生新的version作為current version
- VersionSet就是一系列Version的集合
- VersionEdit表示Version之間的變化,表示增加了多少檔案,删除了多少檔案
Snapshot
- 快照提供了一個目前KV存儲的一個可讀視圖,使得讀取操作不受寫操作影響,可以在讀操作過程中始終看到一緻的資料
- 一個快照對應目前存儲的最新資料版本号
MemTable, Immutable MemTable
- MemTable是leveldb的記憶體緩存。它也提供了資料的寫入,删除,讀取等操作接口。它内部采用Skiplist作為資料組織結構,同時它使用自己實作的Arena作為記憶體配置設定器。
- Immutable MemTable和MemTable結構是完全一樣的,隻不過它是隻讀的,當MemTable中的資料量達到一定程度時會轉換成Immutable MemTable。
TableBuilder, BlockBuilder
TableBuilder: 将資料按照sst檔案的格式組織後,寫入sst檔案
BlockBuilder: 将資料按照Block的格式組織起來,被TableBuilder使用
BuildTable: 在将MemTable的資料寫入sst時調用,使用TableBuilder來實作
TableCache, BlockCache
TableCache和BlockCache底層都是用了LRUCache的資料結構
- TableCache: 緩存了Table相關的資訊,包括Table對應的File指針,以及Table對象的指針,Table對象包含了Table的中繼資料,索引資訊等。可以防止過多的檔案open
- BlockCache: 緩存塊資料
重要流程分析
下面我們通過一些重要流程的分析,将上述子產品串聯起來
Open
下圖為Open流程的簡要流程圖

它的主要流程為:
- New DBImpl: 建立DBImpl對象
- DBImpl::Recover: 恢複資料庫,主要流程就是通過manifest檔案來恢複出VersionSet,表示目前資料庫的檔案資訊;然後再恢複未記錄在manifest中的log檔案,将log檔案的資料重新寫入MemTable中。
- VersionSet::LogAndApply: 如果DBImpl在恢複過程中産生了新的檔案,那麼就會産生VersionEdit,需要将VersionEdit記錄在manifest檔案中,同時将VersionEdit Apply在VersionSet中,産生新的version。
- DBImpl::DeleteObsoleteFiles:将一些不需要的檔案删除
- DBImpl::MaybeScheduleCompaction:嘗試是否需要進行Compaction
Put
下圖為Put流程的簡要流程圖
- Put操作會将(key,value)轉化成writebatch後,通過write接口來完成
- 在write之前需要通過MakeRoomForWrite來保證MemTable有空間來接受write請求,這個過程中可能阻塞寫請求,以及進行compaction。
- BuildBatchGroup就是盡可能的将多個writebatch合并在一起然後寫下去,能夠提升吞吐量
- AddRecord就是在寫入MemTable之前,現在操作寫入到log檔案中
- 最後WriteBatchInternal::InsertInto會将資料寫入到MemTable中
Get
下圖為Get流程的簡要流程圖
- 首先判斷options.snapshot是否為空,如果為不為空,快照值就取這個值,否則取最新資料的版本号
- 然後依次嘗試去MemTable, Immutable MemTable, VersionSet中去查找。VersionSet中的查找流程:
- 逐層查找,确定key可能所在的檔案
- 然後根據檔案編号,在TableCache中查找,如果未命中,會将Table資訊Load到cache中
- 根據Table資訊,确定key可能所在的Block
- 在BlockCache中查找Block,如果未命中,會将Block load到Cache中。然後在Block内查找key是否命中
- 更新讀資料的統計資訊,作為一根檔案是否應該進行Compaction的依據,後面講述Compaction時會說明
- 最後釋放對Memtable,Immutable MemTable,VersionSet的引用
Compaction
在leveldb中compaction主要包括Manual Compaction和Auto Compaction,在Auto Compaction中又包含了MemTable的Compaction和SSTable的Compaction。
Manual Compaction
leveldb中manual compaction是使用者指定需要做compaction的key range,調用接口CompactRange來實作,它的主要流程為:
- 計算和Range有重合的MaxLevel
- 從level 0 到 MaxLevel依次在每層對這個Range做Compaction
- 做Compaction時會限制選擇做Compaction檔案的大小,這樣可能每個level的CompactRange可能需要做多次Compaction才能完成
SSTable Compaction
- 啟動條件
- 每個Level的檔案大小或檔案數超過了這個Level的限制(L0對比檔案個數,其它Level對比檔案大小。主要是因為L0檔案之間可能重疊,檔案過多影響讀通路,而其它level檔案不重疊,限制檔案總大小,可以防止一次compaction IO過重)。
- 含有被尋道次數超過一定門檻值的檔案(這個是指讀請求查找可能去讀多個檔案,如果最開始讀的那個檔案未查找到,那麼這個檔案就被認為尋道一次,當檔案的尋道次數達到一定數量時,就認為這個檔案應該去做compaction)
- 條件1的優先級高于條件2
- 觸發條件
- 任何改變了上面兩個條件的操作,都會觸發Compaction,即調用MaybeScheduleCompaction
- 涉及到第一個條件改變,就是會改變某層檔案的檔案數目或大小,而隻有Compaction操作之後才會改變這個條件
- 涉及到第二個條件的改變,可能是讀操作和scan操作(scan操作是每1M資料采樣一次,獲得讀最後一個key所尋道的檔案,1M資料的cost大約為一次尋道)
- 檔案選取
- 每個level都會記錄上一次Compaction選取的檔案所含Key的最大值,作為下次compaction選取檔案的起點
- 對于根據啟動條件1所做的Compaction,選取檔案就從上次的點開始選取,這樣保證每層每個檔案都會選取到
- 對于根據啟動條件2所做的Compaction,需要做compaction的檔案本身就已經确定了
- Level + 1層檔案的選取,就是和level層選取的檔案有重合的檔案
MemTable Compaction
MemTable Compaction最重要的是産出的檔案所在層次的選擇,它必須滿足如下條件: 假設最終選擇層次L,那麼檔案必須和[0, L-1]所有層的檔案都沒有重合,且對L+1層檔案的覆寫不能超過一定的門檻值(保證Compaction IO可控)
Compaction 檔案産出
- 什麼時候切換産出檔案
- 檔案大小達到一定的門檻值
- 産出檔案對Level+2層有交集的所有檔案的大小超過一定門檻值
- key丢棄的兩個條件
- last_sequence_for_key <= smallest_snapshot (有一個更新的同樣的user_key比最小快照要小)
- key_type == del && key <= smallest_snapshot && IsBaseLevelForKey(key的類型是删除,且這個key的版本比最小快照要小,并且在更高Level沒有同樣的user_key)
總結與思考
- LSM存儲模型:犧牲讀性能,提高随機寫性能
- Level存儲架構:盡可能地優化讀性能,同時減少對寫性能的影響。假設沒有Level的概念,每次讀請求都要去通路多個檔案,于是才有Level的概念去做compaction,盡可能減少讀取的檔案數,同時又保證了每次Compaction IO的資料量,保證對正常的寫請求影響不會太大。
- LSM和Level之間是互相均衡的關系,它們決定了讀寫性能。在不同的應用場景下,我們需要在兩者間有所取舍。
參考文獻
[1].
https://github.com/google/leveldb/tree/master/doc.[2].
https://dirtysalt.github.io/html/leveldb.html#orgheadline88.[3].
https://blog.csdn.net/anderscloud/article/details/7182165.[4].
https://www.atatech.org/articles/65485