原文位址:
http://mechanitis.blogspot.com/2011/07/dissecting-disruptor-why-its-so-fast.html,作者是 Trisha Gee, LMAX 公司的一位女工程師。
Martin Fowler 寫了一篇非常不錯的
文章,不僅描述了
Disruptor,還展示了它是如何适配到 LMAX 架構中的。這篇文章揭示了一些至今還沒有提到的内容,但是最常被問到的問題還是:“什麼是 Disruptor?”
我正在着手回答它。現在先讓我對付第二個問題:“為什麼它這麼快?”
這些問題手拉着手互相糾纏。不管怎麼樣,我不能隻說它為什麼快而不提它是什麼,也不能隻說它是什麼而不提它為什麼會這麼快。
是以我陷在了一個循環依賴裡。這是一個循環依賴的部落格。
為了打破依賴關系,我準備用最簡單的答案回答第一個問題。幸運的話,我會在後面的文章中解釋——如果它還需要解釋的話:Disruptor 是線程間傳遞資料的一種方式。
作為一個開發,我的報警已經響起來了。因為剛剛提到了“線程“ ,這意味着它和并發有關,而 并發是困難的 (Concurrency Is Hard)。
Concurrency 101
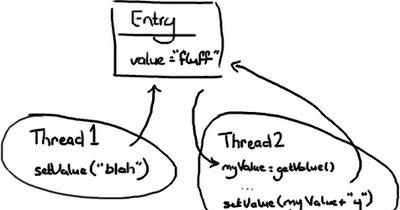
想象兩個線程同時試圖改變一個變量。
場景 1:線程 1 先執行:
1. 變量先被修改成“blah”
2. 線程 2 到了後,把變量修改為“blahy”。
場景 2:線程 2 先執行:
1. 變量先被修改成“fluffy”
2. 線程 1 到了後,把變量修改為“blah”。
場景 3:線程 1 打斷了線程 2:
1. 線程 2 拿到了變量值 "fluff" 并存入 myValue
2. 線程 1 進來把變量更新為“blah”
3. 接着線程 2 醒來把變量設定成“fluffy”。
場景 3 是唯一一個絕對錯誤的場景,除非你認為 wiki 那種幼稚的編輯方式是 OK 的(
Google Code Wiki, 我正瞧着你呢)。另外兩種場景完全取決于代碼的意圖和可預測性。線程 2 也許并不關心 value 是什麼,代碼的意圖可能是:無論那裡有什麼,都在後面加“y”。
但是如果線程 2 隻打算把“fluff”改成“fluffy”,那 2 和 3 兩種場景都錯了。如果線程 2 隻想把值改成“fluffy”,那麼有一些不同的方法可以解決這個問題。
方法一:悲觀鎖(Pessimistic locking)

(“No Entry(禁止進入)”标志對于不在英國開車的人有意義嗎?)
術語“悲觀鎖”和“樂觀鎖”看上去在談論資料庫讀寫時更常用一些,但是這個原則也适用于在變量上加鎖。
線程 2 一旦在它需要時會立即搶占 Entry 對象上的鎖,并阻止任何人再設定鎖。然後它接着做它的事,更新 value,并且讓其他人繼續。
你可以想象這個代價相當昂貴:線程在四處轉着嘗試擷取對象,卻總是被阻塞。你使用的線程越多,執行陷入停頓的機會就越大。
方法二:樂觀鎖(Optimistic locking)
在這種場景下,線程 2 隻需要在更新 Entry 對象時候加鎖。為了實作這個目的,它需要檢查 Entry 對象在第一次通路後是否被修改過。如果線程 2 讀出 value 值以後,線程 1 插進來把value 值改成“blah”,線程 2 就不能繼續向 Entry 對象寫入“fluffy”覆寫線程 1 的修改。線程 2 要麼選擇重試(回過頭來,重新讀出 value 值,再在新值的末尾加“y”)——如果線程 2 并不關心它改變的 value 值是什麼的話;要麼線程 2 會抛出異常或者傳回一些更新失敗的标志——如果它僅僅希望把“fluff”值改為“fluffy”。後一類場景的一個例子是:有兩個使用者嘗試修改同一個 Wiki 頁面,你應該告訴線程 2 那端的使用者,他需要從線程 1 加載新的變更,然後再重新應用他們的修改。
潛在的問題:死鎖
鎖會帶來各種各樣的問題,例如死鎖。想象兩個線程需要通路兩塊資源來做他們想做的事情:
如果你過度依賴加鎖,兩個線程就可能會永遠停下來等待另外一個線程釋放另一塊資源上的鎖。這時候除了重新開機電腦别無辦法。
已被确認的問題:鎖非常慢
關于鎖的問題是,它們需要作業系統來仲裁争端。線程們就像兄妹們争搶一件玩具,OS 核心就是決定誰該得到玩具的父母。就像當你跑向爸爸,告訴他,姐姐在你要玩
變形金剛 的時候弄壞了它一樣——爸爸有比“你們倆打架”更重要的事情得擔心,也許他要先把碗塞進洗碗機,把衣服送進洗衣店後才有時間來解決你們的争吵。如果你隻把注意力放在一個鎖上,不僅僅要消耗時間等待作業系統來仲裁,而且作業系統也有可能認為 CPU 有比“給你的線程提供服務”更重要的事要做。
Disruptor 論文裡提到了過我們做的一個實驗。這個實驗調用一個函數循環遞增一個 64 位計數器 5 億 (500 million) 次。對于一個不加鎖的線程,運作測試隻需要 300 毫秒。如果加入鎖(這是單線程,沒有通路沖突,也沒有鎖以外的複雜性),運作這個測試需要 10,000 毫秒。這差不多慢 2 個數量級。甚至更驚人的,如果你加入第二個線程(這邏輯上應該隻消耗單線程 + 加鎖場景下一半的時間),則需要消耗 224,000 毫秒。——對于單個計數器遞增 5 億次,如果用兩個線程運作,比用一個不加鎖的線程運作要慢 1000 倍。
并發是困難的,而鎖是邪惡的(Concurrency Is Hard and Locks Is Bad)
我們隻是觸及了問題的表面,而且很明顯的,所用的例子是非常簡單的。但核心問題是,如果你的代碼需要在多線程的環境下工作,你作為開發的工作将變得困難許多。
※ 簡單的代碼可以産生意想不到的後果。上面的場景 3 是一個例子,如果你沒有意識到有多個線程在通路和修改相同的資料,這件事會變成可怕的錯誤。
※ 自私的代碼會減慢你的系統。在場景 3 中,使用加鎖保護你的代碼可以避免問題發生,但是會導緻死鎖或者簡單的性能問題。
這是為什麼很多公司在面試過程中都會問一些并發問題(當然是 Java 面試)。遺憾的是,學會怎麼回答這些問題是簡單的,但是要真正的了解問題,或者找出問題的可能解決方案 很難。
Disruptor 怎麼解決這些問題的?
首先,它不——用鎖,完全不用。
相反,在我們需要保證操作是線程安全的地方(特别是在
多個生産者 的情況,更新下一個可用的序号),我們使用
CAS(Compare And Swap/Set) 操作。這是個 CPU 級别的指令,在我的了解裡,它的工作方式有點像樂觀鎖—— CPU 嘗試去更新一個值,但如果它修改前的值不是預期的那個,操作就會失敗,因為這表明有其他人先更新過了。
注意這裡可能是兩個不同的 CPU 核心 (Core) 而不是兩個獨立的 CPU。
CAS 操作比鎖的代價要低很多,因為它們不與作業系統打交道而是直接通路 CPU。但是它們也不是免費的——在上面提到的實驗中,不加鎖的線程要消耗 300 毫秒,加鎖的線程消耗 10,000 毫秒,而使用 CAS 操作的單個線程會消耗 5,700 毫秒。是以 CAS 消耗的時間比加鎖要少,但是比根本不用擔心沖突的單個線程消耗的時間要多。
回到 Disruptor ——我在
講生産者 的時候提到過
ClaimStrategy。在代碼中可以看到兩個政策:SingleThreadedStrategy 和 MultiThreadedStrategy。你可能會問,為什麼不在隻有單個生産者的時候也使用多線程政策呢?它肯定也能處理這個場景吧? 它當然可以。但是多線程政策使用了一個
AtomicLong 對象(Java 提供 CAS 操作的方式),而單線程政策隻使用簡單的 long 值,不用鎖或者 CAS。這意味着單線程的 ClaimStrategy 是盡可能的快,因為它知道隻有一個生産者,不會産生序号上的沖突。
我知道你在想什麼:把單個 long 改成 AtomicLong 不可能是 Disruptor 快的唯一秘密。當然,它當然不是——否則,這篇部落格也不會被叫做“為什麼它這麼快 (一)”了。
但是這是很重要的一點—— Disruptor 代碼裡隻有這一個地方出現多線程競争修改同一個變量值。在整個複雜的 資料結構/架構 裡隻有這麼“一個”地方。這才是秘密。還記得所有的通路對象都擁有序号嗎?如果隻有一個生産者,那麼系統的每一個序号都隻會由一個線程寫入。這意味着沒有通路沖突,不需要鎖,甚至不需要 CAS。而如果存在一個以上的生産者,唯一會被多線程競争寫入的序号就是 ClaimStrategy 對象裡的那個。
這也是為什麼 Entry 對象上的每個字段都
隻能被一個消費者寫入 的原因。它保證了沒有寫沖突,是以不需要鎖或者 CAS。
回到隊列為什麼不适合這份工作
是以,你開始明白為什麼隊列模式,即使底層也可以用 RingBuffer 來實作,但是仍然在性能上無法與 Disruptor 相比。隊列以及
原始的 RingBuffer,有兩個指針——其中一個指向開頭,另一個指向末尾。
如果有一個以上的生産者要寫入隊列,尾指針就将成為一個沖突點,因為有多個線程要更新它。如果有一個以上的消費者,頭指針也會産生争用,因為當隊列元素被消費時,需要更新頭指針,是以不僅僅有讀操作而且有寫操作。
但是等等,我聽到你在喊冤枉了!因為我們知道這一點,隊列通常用于單生産者和單消費者的情況(或者,至少在我們的性能測試裡所有的隊列對比場景中)。
還有另一件有關隊列/緩沖區的事要牢記。隊列的所有目的都是為了提供一塊空間讓任務在生産者和消費者之間等待處理,以幫助緩沖他們之間的突發消息。這意味着緩沖區通常是滿的(生産者速度超過了消費者),或者是空的(消費者速度超過了生産者)。很難看到生産者和消費者的速度如此協調,在保持緩沖區裡有對象的情況下,生産者和消費者互相步調一緻的工作。
是以,這才是事情的真實情況。一個全空的隊列:
... 以及一個全滿的隊列:
隊列需要一個大小(size)變量,讓它能夠區分空和滿的情況。或者,如果沒有 size 變量的話,它可以基于節點(Entry)的内容來做判斷,在這種情況下消費一個節點(Entry)後需要做一次寫入來清除标記,或者标記節點已經被消費過了。
無論選擇哪種實作方式,都會有相當多的通路沖突圍繞着頭指針,尾指針和大小(size)變量,或者是節點(Entry)本身,如果在消費操作中包含一次寫入或者清除操作的話。
除此之外,這三個變量經常會位于同一個
cacheline (CPU 高速緩存行)中,導緻
僞共享(
false-sharing)。是以,你不僅要擔心生産者和消費者同時對 size 變量(或 Entry)的寫入産生沖突,也要擔心更新頭指針後,繼續更新尾指針會導緻 cache-miss(高速緩存未命中),因為它們都位于于同一塊 cacheline。我要回避讨論這兒的細節,因為這篇文章已經相當長了。
這就是我們在談論“概念細分( Teasing Apart the Concerns)”或者隊列的“概念重合(conflated concerns)”時的含義。通過給每個東西一個獨立的序号并且隻允許一個消費者寫入 Entry 對象的每一個字段,Disruptor 唯一需要管理通路沖突的地方,就隻有在多個生産者寫入 Ring Buffer 的場景。
總結
Disruptor 相比傳統方法的一些優勢:
1. 沒有沖突 = 沒有鎖 = 非常快。
2. 所有通路者都記錄自己的序号的實作方式,允許多個生産者與多個消費者共享相同的資料結構。
3. 在每個獨立的對象(RingBuffer,ClaimStrategy,生産者與消費者)中記錄序号,以及神奇的
cacheline padding(高速緩存行補齊),意味着沒有僞共享(false-shareing)與意外沖突。
更新:注意 Disruptor 2.0 版使用了本文不一樣的命名。如果你對類名感到困惑,請閱讀我的
變更總結。