| 這個作業屬于哪個課程 | 2021春/S班 |
|---|---|
| 這個作業要求在哪裡 | 軟工實踐寒假作業(2/2) |
| 這個作業的目标 | 閱讀《建構之法》提出5-10個問題,提出軟工發展過程冷知識,編寫WordCount程式,學習使用GitHub |
| 作業正文 | |
| 其他參考文獻 | GitHub、CSDN、部落格園 |
GitHub連結:https://github.com/lidaming1
項目連結:https://github.com/lidaming1/PersonalProject-C
目錄
- 任務一
- 閱讀完《建構之法》提出的幾個問題:
- 軟體工程發展的過程中有趣的冷知識和故事
- 任務二
- PSP表格
- 解題思路
- 需求分析
- 統計檔案的字元數
- 統計檔案的單詞總數
- 統計檔案的有效行數
- 統計檔案中各單詞的出現次數,最終隻輸出頻率最高的10個,頻率相同的單詞,優先輸出字典序靠前的單詞。
- 計算子產品接口的設計與實作過程
- 單元測試
- 心路曆程與收獲
問題一:
第三章提到過早擴大化/泛化會使整個軟體變得四不像最後隻能讓後人來完善,怎樣才能避免陷入這種誤區,又應該在什麼階段對軟體進行擴大化/泛化,使得程式更加完善?
我認為擴大化的前提是軟體所需的基本功能基本完善的時候才進行考慮的,避免過早擴大化就應該先立足于目前的工作,而非在軟體剛開始時就想着對軟體進行優化,運用更好的架構進行設計。
問題二:
第四章提到結對程式設計使用同一機器一同完成工作,那麼應該如何根據各自的特長配置設定兩個人的任務範圍以取得更高的投入産出比?
有較高程式設計經驗或管理經驗的成員應該對任務的程序加以規劃,為另一個隊友提供相關的幫助。
問題三:
第五章中提到為解決瀑布模型的問題提出了生魚片模型和大瀑布帶着小瀑布模型,分别有什麼優缺點,這兩種模型分别适應與哪種開發場景?
大瀑布帶着小瀑布模型:當子系統的所要求的的難度不同,任務相差較大時,有利于差別對待每個項目,分不同層次的投入,但各個解決步驟分離。
生魚片模型:各個步驟關聯度較高時更适用于生魚片模型,解決各個步驟分離的缺點,但不如大瀑布帶着小瀑布靈活。
問題四:
第六章中提到Scrum/Sprint能成功實施的關鍵在于Scrum Master,那麼應該如何判斷一個人能否勝任Scrum Master的工作?
scrum master是負責一個team按照scrum方式運作的角色。Scrum Master通過以身作則、尊重及對靈活團隊組織和效益的有效影響力來上司團隊。Scrum Master也通過價值觀、勇氣、承諾及固執來引領團隊。固執地擁有強烈的信仰、擁有強烈的改變組織的意願。
問題五:
第九章介紹的PM對團隊起着重要作用,但應該如何處理好與團隊成員的關系,了解成員的狀态,合理配置設定工作來提高項目的完成效率何工作品質?
PM要對小組成員以往承擔的項目進行了解和分析,根據每個成員的能力和特長進行工作的配置設定,通過分析以前項目的進度和目前項目的進度來制定合适的工作目标,以免由于過多的任務導緻成員的激憤。
1975年,艾倫和蓋茨給Altair 8800計算機寫了個BASIC解釋器賣給MITS,他們很快完成了解釋器,甚至包括自己的IO系統和編輯器,一共隻需要4k記憶體。 不過最後他們發現還需要一個引導程式将這些東西從外存整進去。 Paul Allen在飛機航班上完成了這項工作。這是1975年,沒有筆記本。他用的是紙筆。寫的是8080機器碼。(來源于知乎)
| PSP2.1 | Personal Software Process Stages | 預估耗時(分鐘) | 實際耗時(分鐘) |
|---|---|---|---|
| Planning | 計劃 | 20 | |
| • Estimate | • 估計這個任務需要多少時間 | 790 | 890 |
| Development | 開發 | 690 | |
| • Analysis | • 需求分析 (包括學習新技術) | 40 | 60 |
| • Design Spec | • 生成設計文檔 | ||
| • Design Review | • 設計複審 | 15 | |
| • Coding Standard | • 代碼規範 (為目前的開發制定合适的規範) | ||
| • Design | • 具體設計 | 30 | 35 |
| • Coding | • 具體編碼 | 450 | 500 |
| • Code Review | • 代碼複審 | ||
| • Test | • 測試(自我測試,修改代碼,送出修改) | 80 | |
| Reporting | 報告 | 100 | |
| • Test Repor | • 測試報告 | 45 | |
| • Size Measurement | • 計算工作量 | ||
| • Postmortem & Process Improvement Plan | • 事後總結, 并提出過程改進計劃 | ||
| 合計 |
這個功能十分簡單,隻需要逐個字元讀取文本就可以統計了。
單詞的定義在作業描述裡面寫的十分明确:至少以4個英文字母開頭,跟上字母數字元号,單詞以分隔符分割,不區分大小寫,隻需要按照定義把單詞取出來從文本中統計即可。
有效行數的定義是包含非空白字元的行,這裡的非空白字元指的是 ASCII 碼:32~126,逐行讀取文本之後再對每一行逐個字元判斷即可。
在統計檔案的單詞總數的時候每當判斷得到一個單詞就先儲存,之後再使用排序算法得到頻率最高的10個單詞。
主要分為兩個類,一個類為檔案流的輸入輸出,有兩個主要函數,另一個類為對檔案資料的處理,有五個主要函數。
檔案讀取函數過濾掉ascll外的字元,計算字元數時直接擷取資料流長度就可以。
計算行數時,每次讀取一行,判斷該行是否存在可視字元,若存在則有效行數加一。
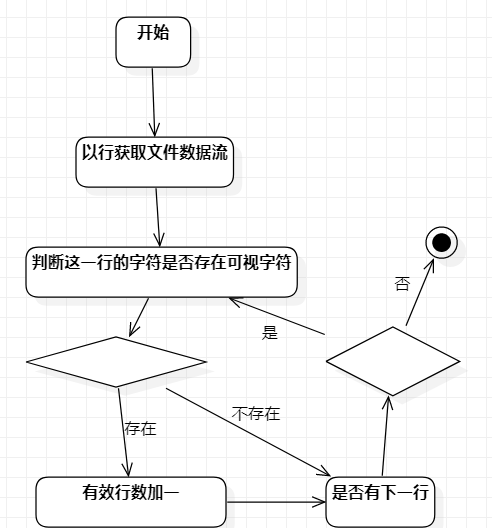
軟工實踐寒假作業(2/2)
for (int i = 0; i < linesBuf.size(); i++)
{
for (string::iterator it = linesBuf[i].begin(); it != linesBuf[i].end(); it++)
{
if (*it >= 32&& *it <= 126) //可列印字元(32~126)
{
lineCount++;
break;
}
}
}
在計算單詞數時,可以同時将單詞存到map中,以便在統計單詞頻率時使用。統計頻率前十單詞數代碼:
軟工實踐寒假作業(2/2)
int WordMapSize = int(WordMap.size());
for (int i = 0; i < WordMapSize && i < 10; i++)
{
auto maxFreWord = WordMap.begin();
for (map<string, int>::iterator it = WordMap.begin(); it != WordMap.end(); it++)
{
if (it->second > maxFreWord->second)
{
maxFreWord = it;
}
}
Top10Word.push_back(maxFreWord);
maxFreWord->second = -maxFreWord->second;
}
經過測試發現讀取字元流函數所耗費的時間最長,這也是因為我為安字元讀取,每個字元都進行判斷處理,當檔案資料較多時就會導緻這個函數的耗時占比較高。
這次的作業總體上不難,大多是以前學過的知識,通過CSDN、部落格園上的内容以及以前的程式複習後就有了較清晰的思路。由于以前用java就寫過了類似的功能,于是就根據寫過的程式修改成C++程式(當時想着好久沒寫過C++了就寫一次)。雖然有着java程式的參照,但由于語言的不同也出現了很大的麻煩,由于該程式中需要注意的細節較多,是以在編寫過程中也出現了較多的bug。由于整行讀取一直會出現丢字元的情況(暫時也不知道是什麼原因),于是我幹脆就直接以字元形式讀取檔案進行字元串處理和存儲,也友善過濾掉ascll碼外的字元。
收獲:這次的作業讓我重新學習了C++,撿回了不少C++的相關知識,也讓我知道我對C++的陌生,為我敲響了警鐘。在出bug的時候與同學的讨論,與學長的讨論也讓我學習了不少新的解題思路、對bug的排查與處理,在當局者迷的時候往往旁觀者能更好的看出你的漏洞。學會了GitHub的基本使用,讓注冊了許久的賬号開始工作。