摘要:本文簡單介紹一下什麼是統計資訊、統計資訊記錄了什麼、為什麼要收集統計資訊、怎麼收集統計資訊以及什麼時候收集統計資訊。
1 WHY:為什麼需要統計資訊
1.1 query執行流程
下圖描述了GaussDB的SQL引擎從接收用戶端SQL語句到執行SQL語句需要經曆的關鍵步驟,以及各個流程中可能對執行産生影響的因素
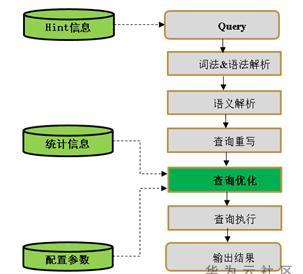
1) 詞法&文法解析
按照約定的SQL語句規則,把輸入的SQL語句從字元串轉化為格式化結構(Stmt),如果SQL語句存在文法錯誤,都會在這個環節報錯。
2) 語義解析
語義解析類似一個翻譯器,把外部輸入的可視化的對象翻譯為資料庫内部可識别的對象(比如把Stmt中以字元串記錄的表名稱轉化為資料庫内部可識别的oid),如果語句存在語義錯誤(比如查詢的表對象不存在),資料庫會在這個環節報錯。
3) 查詢重寫
根據規則将“語義解析”的輸出等價轉化為執行上更為優化的結構,比如把查詢語句中的視圖逐層展開至最低層的表查詢。
4) 查詢優化
資料庫确認SQL執行方式、生成執行計劃的過程
5) 查詢執行
根據執行計劃執行SQL并輸出結果的過程
整個執行流程中,優化器決定了查詢語句的具體執行方式,對SQL語句的性能起着關鍵性的作用。資料庫查詢優化器分為兩類:基于規則的優化器(Rule-Based Optimizer,RBO) 和基于代價的優化器(Cost-Based Optimizer,CBO)。RBO是一種基于規則的優化,對于指定的場景采用指定的執行方式,這種優化模型對資料不敏感;SQL的寫法往往會影響執行計劃,不了解RBO的細則的人員開發的SQL性能不可控,是以RBO逐漸被抛棄,目前GaussDB等資料庫廠商的優化器都是CBO模型。CBO模型是根據SQL語句生成一組可能被使用的執行計劃,并估算出每種執行計劃的代價,最終選擇選擇一個代價最小的執行方式。
1.2 CBO模型
資料庫執行SQL語句的時候,會把執行拆分為若幹步驟,如下SQL
select *
from t1 join t2 on t1.a=t2.b
where t1.b = 2 and t2.a = 3; 在具體執行的時候會拆分為表掃描和表關聯兩個主要查詢動作。這兩個查詢動作都存在多種執行方式,比如表掃描均存在SeqScan、IndexScan、IndexOnlyScan、BitmapScan等多種執行方式、表關聯存在NestLoop、HashJoin、MergeJoin三種執行方式,那麼在具體的業務場景下什麼樣的查詢動作才是代價最小的執行方式,這就是優化器的核心工作。
CBO主要工作原理是通過代價模型(Cost Model)和統計資訊估算每種執行方式的代價,然後選擇一種執行代價最優的執行方式。這裡面代價模型是核心算法邏輯,統計資訊是cost計算的資料源,二者配合完成cost計算;如果統計資訊缺失,計算時代價模型會使用預設值來計算cost,當然這時cost會跟真實值存在較大偏差,大機率會出現選擇非最優執行計劃的情況,是以統計資訊是CBO模型中 cost計算的資料輸入,是CBO最核心的科技之一。
2 WHAT:都有哪些統計資訊
統計資訊是指資料庫描述表或者索引資料特征的資訊,常見的有表記錄條數、頁面數等描述表規模的資訊,以及描述資料分布特征的MCV(高頻非NULL值)、HISTOGRAM(直方圖)、CORRELATION等資訊。
本文中通過如下用例來展示統計資訊是如何表現表的資料特征的
DROP TABLE public.test;
CREATE TABLE public.test(a int, b int, c int[]);
INSERT INTO public.test VALUES (generate_series(1, 20), generate_series(1, 1200));
INSERT INTO public.test VALUES (generate_series(1, 1200), generate_series(1, 1200));
UPDATE public.test SET c = ('{' || a || ','|| a || '}')::int[] WHERE b <= 1000;
UPDATE public.test SET c = ('{' || a || ','|| b || '}')::int[] WHERE b > 1000;
ANALYZE public.test; 3 WHERE:統計資訊在哪裡
3.1 表規模資訊
系統表pg_class中的reltuples和relpages兩個字段能夠反映表規模資訊資訊,其中relpages記錄了表資料存儲到幾個page頁裡面,主要用于表從存儲接口掃描資料的代價計算;reltuples記錄了表記錄條數,主要用于掃描結果集行數估算。
查詢pg_class中的表規模估算資訊,顯示表為2400行

單表全量資料查詢,通過explain檢視表規模估算,顯示表掃描輸出行數估算為2400。
3.2 單列統計資訊
單列統計資訊是指表的單列的資料特征資訊,存儲在系統表pg_statistic中。因為pg_statistic會存儲一些關鍵采樣值來描述資料特征,是以pg_statistic資料是敏感的,隻有超級使用者才可以通路pg_statistic。通常我們推薦使用者使用查詢系統視圖pg_stats來查詢目前使用者有查詢權限的表的統計資訊,同時pg_stats資訊的可讀性更強,pg_stats字段資訊如下
查詢表public.test的a列的資料特征資訊如下
通過統計新可以看出public.test的a列的NULL值比例為0,存在120個distinct值, 1~20是MCV值,每個出現的機率是0.0254167;21~1200出現在在直方圖統計資訊中;
以查詢語句“SELECT count(1) FROM public.test WHERE a < 44;”為例說明統計資訊在優化過程中行數估算場景下的作用
a) 所有MCV值均滿足a < 44,所有MCV值的比例為0.0254167 * 20 = 0.5083340
b) 44為直方圖中第三個邊界,直方圖中滿足a < 44的值的比例為(1-0.5083340)/100 *(3-1)= .0098333200
那麼表中滿足a<56的tuples的個數為1243.6015680 ≈1244,通過explain列印執行計劃如下
3.3 擴充統計資訊
擴充統計資訊存儲在系統表pg_statistic_ext裡面,目前隻支援多列統計資訊這一種擴充統計資訊類型。pg_statistic_ext會存儲一些關鍵采樣值來描述資料特征,是以pg_statistic_ext資料是敏感的,隻有超級使用者才可以通路pg_statistic_ext,通常我們推薦使用者使用查詢系統視圖pg_ext_stats來查詢目前使用者有查詢權限的擴充統計資訊。
表的多個列有相關性且查詢中有同時基于這些列的過濾條件、關聯條件或者分組操作的時候,可嘗試收集多列統計資訊。擴充統計資訊需要手動進行收集(具體收集方法,下個小節會介紹),如下為test表(a,b)兩列的統計資訊
4 HOW:如何生成統計資訊
4.1 顯式收集統計資訊
4.1.1 單列統計資訊
通過如下指令收集單列統計資訊:
{ ANALYZE | ANALYSE } [ VERBOSE ] [ table_name [ ( column_name [, ...] ) ] ]; 如文法描述,我們支援對指定列做統計資訊,但是實際上我們很難統計實際業務SQL中到底使用了目前哪些表的列進行了代價估算,是以建議通常情況下對全表收集統計資訊。
4.1.2 擴充統計資訊
通過如下指令收集多列統計資訊:
{ANALYZE | ANALYSE} [ VERBOSE ] table_name (( column_1_name, column_2_name [, ...] )); 需要注意的是,目前隻支援在百分比采樣模式下生成擴充統計資訊,是以在收集擴充統計資訊之前請確定GUC參數default_statistics_target為負數
4.2 提升統計資訊品質
analyze是按照随機采樣算法從表上采樣,根據樣本計算表資料特征。采樣數可以通過配置參數default_statistics_target進行控制,default_statistics_target取值範圍為-100~10000,預設值為100。
1) 當default_statistics_target > 0時;采樣的樣本數為300*default_statistics_target,default_statistics_target取值越大,采樣的樣本也越大,樣本占用的記憶體空間也越大,統計資訊計算耗時也越長
2) 當default_statistics_target < 0時,采樣的樣本數為 (default_statistics_target)/100*表的總行數,default_statistics_target取值越小,采樣的樣本也越大。但是default_statistics_target < 0時會把采樣資料下盤,不存在樣本占用的記憶體空間的問題,但是因為樣本過大,計算耗時長的問題同樣存在
default_statistics_target < 0時,實際采樣數是(default_statistics_target)/100*表的總行,是以我們又稱之為百分比采樣。
4.3 自動收集統計資訊
當配置參數autoanalyze打開時,查詢語句走到優化器發現表不存在統計資訊,會自動觸發統計資訊收集,以滿足優化器的需求。以文檔的case為列
注:隻有對統計資訊敏感的複雜查詢動作(多表關聯等操作)的SQL語句執行時才會觸發自動收集統計資訊;簡單查詢(比如單點,單表聚合等) 不會觸發自動收集統計資訊
5 WHEN:什麼時候收集統計資訊
5.1 大規模資料變化
大規模資料導入/UPDATE/DELETE等操作,會導緻表資料行數變化,新增的大量資料也會導緻資料特征發生大的變化,此時需要對表重新收集統計資訊
5.2 查詢新增資料
常見于業務表新增資料查詢場景,這個也是收集業務中最常見、最隐蔽的統計資訊沒有及時更新的問題,這種場景最主要的特征如下
1) 存在一個按照時間增長的業務表
2) 業務表每天入庫新一天的資料
3) 資料入庫之後查詢新增資料進行資料加工分析
在最後步驟的資料加工分析時,最長的方法就是使用Filter條件從分區表中篩選資料,如passtime > ‘2020-01-19 00:00:00’ AND pastime < ‘2020-01-20 00:00:00’,假如新增資料入庫之後沒有做analyze,優化器發現Filter條件中的passtime取值範圍超過了統計資訊中記錄的passtime值的上邊界,會把估算滿足passtime > ‘2020-01-19 00:00:00’ AND pastime < ‘2020-01-20 00:00:00’的tuple個數為1條,導緻估算行數驗證失真
6 WHO:誰來收集統計資訊
AP場景下業務表資料量一般都很大,單次導入的資料量也比較大,而且經常是資料導入即用,是以建議在業務開發過程中,根據資料變化量和查詢特征在需要的地方主動對相關表做analyze。
本文分享自華為雲社群《GaussDB(DWS)性能調優系列基礎篇一:萬物之始analyze統計資訊》,原文作者:譡裡個檔。
點選關注,第一時間了解華為雲新鮮技術~