本文示例代碼、資料及檔案已上傳至我的 Github
1 簡介
在上一篇文章中我們詳細學習了
geoplot
中較為基礎的三種繪圖API:
pointplot()
、
polyplot()
以及
webmap()
,而本文将會承接上文的内容,對
geoplot
中較為實用的幾種進階繪圖API進行介紹。
圖1
本文是基于geopandas的空間資料分析系列文章的第7篇,通過本文你将學習
geoplot
中的進階繪圖API。
2 geoplot進階
上一篇文章中的
pointplot()
polyplot
webmap()
幫助我們解決了在繪制散點、基礎面以及添加線上地圖底圖的問題,為了制作出資訊量更豐富的可視化作品,我們需要更強的操縱矢量資料與映射值的能力,
geoplot
為我們封裝好了幾種常見的進階可視化API。
2.1 Choropleth
Choropleth圖又稱作地區分布圖或面量圖,我們在系列之前的深入淺出分層設色篇中介紹過其原理及
geopandas
實作,可以通過将名額值映射到面資料上,以實作對名額值地區分布的可視化。
在
geoplot
中我們可以通過
choropleth()
來快速繪制地區分布圖,其主要參數如下:
df:傳入對應的GeoDataFrame
對象
projection:用于指定投影坐标系,傳入
geoplot.crs
中的對象
hue:傳入對應df中指定列名或外部序列資料,用于映射面的顔色,預設為None即不進行設色
cmap:和
matplotlib
中的cmap使用方式一緻,用于控制色彩映射方案
alpha:控制全局色彩透明度
scheme:作用類似
中的scheme參數,用于控制分層設色,詳見本系列文章的分層設色篇,但不同的是在geopandas
0.4.0版本之後此參數不再搭配分層數量k共同使用,而是更新為傳入geoplot
mapclassify
分段結果對象,下文中會做具體示範
legend:bool型,用于控制是否顯示圖例
legend_values:list型,用于自定義圖例顯示的各個具體數值
legend_labels:list型,用于自定義圖例顯示的各個具體數值對應的文字标簽,與legend_values搭配使用
legend_kwargs:字典,在legend參數設定為True時來傳入更多微調圖例屬性的參數
extent:元組型,用于傳入左下角和右上角經緯度資訊來設定地圖空間範圍,格式為
figsize:元組型,用于控制畫幅大小,格式為(min_longitude, min_latitude, max_longitude, max_latitude)
ax:(x, y)
坐标軸對象,如果需要在同一個坐标軸内疊加多個圖層就需要用這個參數傳入先前待疊加的matplotlib
ax
hatch:控制填充陰影紋路,詳情見本系列文章前作基礎可視化篇圖7
edgecolor:控制多邊形輪廓顔色
linewidth:控制多邊形輪廓線型
下面我們通過實際的例子來學習
geoplot.choropleth
的用法,這裡使用到的資料為美國新型冠狀肺炎各州病例數分布,對應日期為2020年5月14日,來自
Github
倉庫:https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_daily_reports_us;使用到的美國本土各州矢量面資料
contiguous-usa.geojson
已上傳到文章開頭對應的
Github
倉庫中:
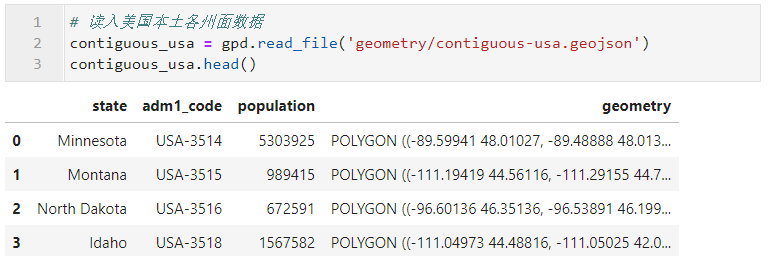
圖2

圖3
首先我們将兩張表中各自對應的州名資料作為鍵進行連接配接(注意
pd.merge
傳回的結果類型為
DataFrame
,需要轉換回
GeoDataFrame
):
# 按照州名列進行連接配接
usa_plot_base = pd.merge(left=contiguous_usa,
right=usa_covid19_20200513,
left_on='state',
right_on='Province_State')
# 轉換DataFrame到GeoDataFrame,注意要加上crs資訊
usa_plot_base = gpd.GeoDataFrame(usa_plot_base, crs='EPSG:4326')
接下來我們将确診數作為映射值,因為美國各州中紐約州和紐澤西州确診數量分别達到了34萬和14萬,遠遠超過其他州,是以這裡作為單獨的圖層進行陰影填充以突出其嚴重程度:
# 圖層1:除最嚴重兩州之外的其他州
ax = gplt.choropleth(df=usa_plot_base.query("state not in ['New York', 'New Jersey']"),
projection=gcrs.AlbersEqualArea(),
hue='Confirmed',
scheme=mc.FisherJenks(usa_plot_base.query("state not in ['New York', 'New Jersey']")['Confirmed'], k=3),
cmap='Reds',
alpha=0.8,
edgecolor='lightgrey',
linewidth=0.2,
figsize=(8, 8)
)
# 圖層2:紐約州
ax = gplt.polyplot(df=usa_plot_base.query("state == 'New York'"),
hatch='/////',
edgecolor='black',
ax=ax)
# 圖層3:紐澤西州
ax = gplt.polyplot(df=usa_plot_base.query("state == 'New Jersey'"),
hatch='/////',
edgecolor='red',
extent=usa_plot_base.total_bounds,
ax=ax)
# 執行個體化cmap方案
cmap = plt.get_cmap('Reds')
# 得到mapclassify中BoxPlot的資料分層點
bp = mc.FisherJenks(usa_plot_base.query("state not in ['New York', 'New Jersey']")['Confirmed'], k=3)
bins = [0] + bp.bins.tolist()
# 制作圖例映射對象清單,這裡配置設定Greys方案到三種色彩時對應的是[0, 0.5, 1]這三個采樣點
LegendElement = [mpatches.Patch(facecolor=cmap(_ / 2), label=f'{int(bins[_])}-{int(bins[_+1])}')
for _ in range(3)] + \
[mpatches.Patch(facecolor='none',
edgecolor='black',
linewidth=0.2,
hatch='/////',
label='New York: {}'.format(usa_plot_base.query("state == \"New York\"").Confirmed.to_list()[0])),
mpatches.Patch(facecolor='none',
edgecolor='red',
linewidth=0.2,
hatch='/////',
label='New Jersey: {}'.format(usa_plot_base.query("state == \"New Jersey\"").Confirmed.to_list()[0]))]
# 将制作好的圖例映射對象清單導入legend()中,并配置相關參數
ax.legend(handles = LegendElement,
loc='lower left',
fontsize=8,
title='确診數量',
title_fontsize=10,
borderpad=0.6)
# 添加标題
plt.title('美國新冠肺炎各州病例數(截至2020.05.14)', fontsize=18)
# 儲存圖像
plt.savefig('圖4.png', dpi=300, pad_inches=0, bbox_inches='tight')
圖4
這樣我們就得到了圖4,需要注意的是,
geoplot.choropleth()
隻能繪制地區分布圖,傳入面資料後
hue
參數必須指定對應映射列,否則會報錯,是以這裡我們疊加紐約州和紐澤西州單獨面圖層時使用的是
polyplot()
。
2.2 Kdeplot
geoplot
中的
kdeplot()
對應核密度圖,其基于
seaborn
kdeplot()
,通過對矢量點資料分布計算核密度估計,進而對點資料進行可視化,可用來展示點資料的空間分布情況,其主要參數如下:
df:傳入對應的存放點資料的GeoDataFrame
geoplot.crs
clip:matplotlib
型,用于為初始生成的核密度圖像進行蒙版裁切,下文會舉例說明GeoSeries
(min_longitude, min_latitude, max_longitude, max_latitude)
(x, y)
matplotlib
ax
shade:bool型,當設定為False時隻有等值線被繪制出,當設定為True時會繪制核密度填充
shade_lowest:bool型,控制是否對機率密度最低的層次進行填充,下文會舉例說明
n_levels:int型,控制等值線數量,即按照機率密度對空間進行均勻劃分的數量
下面我們回到上一篇文章開頭的例子——紐約車禍記錄資料,在其他參數均為預設的情況下,調用
kdeplot
對車禍記錄點資料的空間分布進行可視化:
# 圖層1:行政邊界
ax = gplt.polyplot(df=nyc_boroughs,
projection=gcrs.AlbersEqualArea())
# 圖層2:預設參數下的kdeplot
ax = gplt.kdeplot(df=nyc_collision_factors,
cmap='Reds',
ax=ax)
# 儲存圖像
plt.savefig('圖5.png', dpi=300, pad_inches=0, bbox_inches='tight')
圖5
可以看到,在
kdeplot()
主要參數均為預設值的情況下,我們得到了點資料空間分布的機率估計結果及其等高線,譬如圖中比較明顯能看到的兩個點分布較為密集的中心,下面我們調整
n_levles
參數到比較大的數字:
# 圖層1:行政邊界
ax = gplt.polyplot(df=nyc_boroughs,
projection=gcrs.AlbersEqualArea())
# 圖層2:kdeplot
ax = gplt.kdeplot(df=nyc_collision_factors,
cmap='Reds',
n_levels=30,
ax=ax,
figsize=(8, 8))
# 儲存圖像
plt.savefig('圖6.png', dpi=300, pad_inches=0, bbox_inches='tight')
圖6
可以看到在增大
n_levels
參數後,圖中等值線的數量随之增加,下面我們設定
shade=True
:
# 圖層1:行政邊界
ax = gplt.polyplot(df=nyc_boroughs,
projection=gcrs.AlbersEqualArea())
# 圖層2:kdeplot
ax = gplt.kdeplot(df=nyc_collision_factors,
cmap='Reds',
shade=True,
ax=ax,
figsize=(8, 8))
# 儲存圖像
plt.savefig('圖7.png', dpi=300, pad_inches=0, bbox_inches='tight')
圖7
這時圖像等值線間得到相應顔色的填充,使得點分布中心看起來更加明顯,再添加參數
shade_lowest=True
,即可對空白區域進行填充:
圖8
随之而來的問題是整幅圖像都被填充,為了裁切出核密度圖像的地區輪廓,将底層行政區面資料作為
clip
的參數傳入,便得到理想的效果:
圖9
2.3 Sankey
桑基圖專門用于表現不同對象之間某個名額量的流動情況,譬如最常見的航線流向情況,其本質是對線資料進行可視化,并将名額值映射到線的色彩或粗細水準上,而
geoplot
sankey()
可以用來繪制這種圖,尴尬的是
sankey()
繪制出的OD流向圖實在太醜,但
sankey()
中将數值映射到線資料色彩和粗細的特性可以用來進行與流量相關的可視化,其主要參數如下:
GeoDataFrame
hue:傳入對應df中指定列名或外部序列資料,用于映射線的顔色,預設為None即不進行設色geoplot.crs
matplotlib
geopandas
geoplot
mapclassify
scale:用于設定映射線要素粗細程度的序列資料,格式同hue,預設為None即每條線等粗
linewidth:當不對線寬進行映射時,該參數用于控制線寬
(min_longitude, min_latitude, max_longitude, max_latitude)
(x, y)
matplotlib
ax
下面我們以2015年華盛頓街道路網日平均交通流量資料為例,其中每個要素均為線要素,
aadt
代表日均流量:
圖10
我們将其流量列映射到線的粗細程度和顔色上來,為了美觀起見我們選擇系列文章分層設色篇中
palettable
的
SunsetDark
作為配色方案:
# 選擇配色方案為SunsetDark_5
from palettable.cartocolors.sequential import SunsetDark_5
gplt.sankey(
dc_roads,
projection=gcrs.AlbersEqualArea(),
scale='aadt',
hue='aadt',
limits=(0.1, 2), # 控制線寬範圍
scheme=mc.NaturalBreaks(dc_roads['aadt']),
cmap=SunsetDark_5.mpl_colormap,
figsize=(8, 8),
extent=dc_roads.total_bounds
)
plt.savefig("圖11.png", dpi=500, pad_inches=0, bbox_inches='tight')
圖11
2.4 geoplot中的坐标參考系
geoplot
中的坐标參考系與
geopandas
中管理起來的方式截然不同,因為
geopandas
基于
pyproj
管理坐标參考系,而
geoplot
crs
子子產品來源于
cartopy
,這一點我跟
geoplot
的主要開發者聊過,他表示
geoplot
暫時不支援
geopandas
中那樣自定義任意投影或使用
EPSG
投影,而是内置了一系列常用的投影,譬如我們上文中繪制美國區域時頻繁使用到的
AlbersEqualArea()
即之前我們在
geopandas
中通過proj4自定義的阿爾伯斯等面積投影,其他常見投影譬如Web Mercator、Robinson,或者直接繪制球體地圖,如本文開頭的圖1就來自官方示例(https://residentmario.github.io/geoplot/gallery/plot_los_angeles_flights.html#sphx-glr-gallery-plot-los-angeles-flights-py),關于
geoplot
坐标參考系的細節比較簡單本文不多贅述,感興趣的讀者可以前往官網(https://residentmario.github.io/geoplot/api_reference.html#projections)檢視。
2.5 在模仿中學習
又到了最喜歡的“複刻”環節啦,本文要模仿的地圖可視化作品來自https://github.com/Z3tt/30DayMapChallenge/tree/master/contributions/Day26_Hydrology,同樣是用
R
語言實作,對全球主要河流的形态進行優雅地可視化:
圖12
針對其河流寬度方面的可視化,我們基于上文中的
sankey()
來實作,由于原圖中南極洲區域實際上是誇大了的,其
R
源碼中設定的緯度範圍達到了-110度,這是原作者為了放得下标題内容,是以在圖像下部區域虛構了一篇區域,而
geoplot
extent
參數嚴格要求經度必須在-180到180度之間,緯度在-90到90度之間。是以在原圖的基礎上我們進行微調,将标題移動到居中位置,具體代碼如下:
from palettable.cartocolors.sequential import Teal_7_r
import matplotlib.font_manager as fm
from shapely.geometry import box
# 讀入世界主要河流線資料
world_river = gpd.read_file('geometry/world_rivers_dSe.geojson')
# 讀入世界海洋面資料
world_ocean = gpd.read_file('geometry/world_ocean.shp')
# 圖層1:世界範圍背景色,基于shapely.geometry中的bbox來生成矩形矢量
ax = gplt.polyplot(df=gpd.GeoDataFrame({'geometry': [box(-180, -90, 180, 90)]}),
facecolor='#000026',
edgecolor='#000026')
# 圖層2:世界海洋面圖層
ax = gplt.polyplot(world_ocean,
facecolor='#00003a',
edgecolor='#00003a',
ax=ax)
# 圖層3:世界主要河流線圖層
ax = gplt.sankey(world_river,
scale='StrokeWeig',
hue='StrokeWeig',
scheme=mc.Quantiles(world_river['StrokeWeig'], 7),
cmap=Teal_7_r.mpl_colormap,
limits=(0.05, 0.4),
figsize=(8, 8),
extent=(-180, -90, 180, 90),
ax=ax)
# 添加标題
ax.text(0, 0, 'The Rivers of the World',
fontproperties=fm.FontProperties(fname="AlexBrush-Regular.ttf"), # 傳入Alex Brush手寫字型檔案
fontsize=28,
color=Teal_7_r.mpl_colors[-1],
horizontalalignment='center',
verticalalignment='center')
# 添加作者資訊及資料來源
ax.text(0, -15, 'Visualization by CNFeffery - Data by Natural Earth',
fontproperties=fm.FontProperties(fname="AlexBrush-Regular.ttf"),
fontsize=8,
color='#599bae',
horizontalalignment='center',
verticalalignment='center')
plt.savefig('圖13.png', dpi=600, pad_inches=0, bbox_inches='tight')
圖13
以上就是本文的全部内容,我将在下一篇文章中繼續與大家一起探讨學習
geoplot
中更進階的繪圖API。如有疑問和意見,歡迎留言或在我的
Github
倉庫中發起issues與我交流。