前言:
在之前寫的一篇計算機視覺入門路線文章中,我推薦大家在不用任何架構、隻使用numpy這種包的情況下,從零實作一個卷積神經網絡。其中一個很重要的因素就是在這個過程中大家會了解到卷積過程在底層中是如何優化實作的,其主流的方法就是GEMM。這篇部落格比較細緻地介紹了什麼是GEMM,以及它的優缺點。
我大部分時間都在考慮如何讓神經網絡的深度學習更快、更高效。在實踐中,這意味着要關注一個名為GEMM的函數。它是1979年首次建立的BLAS(基本線性代數子程式)庫的一部分,直到我開始嘗試優化神經網絡之前,我從未聽說過它。為了解釋為什麼它如此重要,這是我朋友楊慶嘉論文的圖表
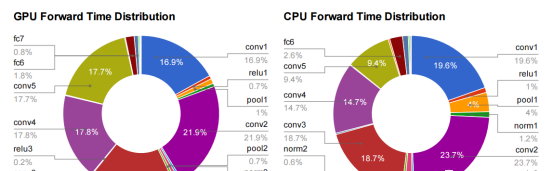

所有以fc(完全連接配接)或卷積)開頭的層都使用GEMM實作,幾乎所有時間(95%的GPU版本,89%的CPU)都花在這些層上。
那麼什麼是GEMM呢?它代表全局矩陣到矩陣的乘法,它本質上完全按照它在tins上所說的那樣,将兩個輸入矩陣乘法在一起,得到一個輸出矩陣。它和我在三維圖形世界中使用的矩陣操作類型之間的差別在于,它所工作的矩陣通常非常大。
例如,典型網絡中的單個層可能需要将256行、1152列矩陣乘以1152行、192列矩陣,以産生256行、192列的結果。天真地說,這需要5700萬層(256x1152x192)浮點操作,在現代架構中可以有幾十個這樣的層,是以我經常看到網絡需要幾十億FLOP來計算一幀。下面是我繪制的一個關系圖,以幫助我可視化它的工作原理:
關注公衆号CV技術指南,及時擷取更多計算機視覺的内容。
完全連接配接的圖層
全連接配接層是已經存在了幾十年的經典神經網絡,并且可以最簡單地從如何使用GEMM開始。FC層的每個輸出值檢視輸入層中的每個值,将它們全部乘以該輸入索引的相應權重,并将結果相加以得到其輸出。根據上圖的說明,具體情況如下:
有“k”輸入值,也有“n”神經元,每個輸入值都有自己的學習權值集。有“n”輸出值,每個神經元都有一個輸出值,通過做其權值和輸入值的點積來計算。
卷積圖層
使用GEMM進行卷積層并不是一個明顯的選擇。卷積層将其輸入視為二維圖像,每個像素都有多個通道,很像具有寬度、高度和深度的經典圖像。與我習慣處理的圖像不同,通道的數量可以是數百個,而不僅僅是RGB或RGBA!
卷積操作通過擷取一些“核”的權重來産生其輸出。并在圖像中應用它們。下面是輸入映像和單個核心的外觀:
每個卷積核都是一個三維數組,其深度與輸入圖像相同,但其寬度和高度要小得多,通常就像7×7一樣。為了産生結果,卷積核将應用到輸入圖像的點網格。在應用它的每個點,所有相應的輸入值和權重相乘,然後在該點相加産生單個輸出值。以下是視覺效果:
您可以将這個操作看作是一個邊緣檢測器。卷積核包含一個權重模式,并且當它所檢視的輸入圖像的部分具有類似的模式時,它會輸出一個高值。當輸入與模式不比對時,結果是該位置的數較低。以下是一些典型的模式,它們是由網絡的第一層學習的。
因為第一層的輸入是RGB圖像,所有這些核也可以可視化為RGB,它們顯示網絡正在尋找的原始模式。這些96個核心中的每一個在輸入上以網格模式應用,結果是一系列96個二維數組,它們被視為具有96個通道深度的輸出圖像。如果您習慣了像Sobel操作符這樣的圖像處理操作,您可以想象它們都有點像針對圖像中不同重要模式優化的邊緣檢測器,是以每個通道都是輸入中這些模式發生位置的映射。
您可能已經注意到,我對核心應用的網格類型很模糊。它的關鍵控制因素是一個稱為“步幅”的參數,它定義了核心應用程式之間的間距。例如,随着步幅為1,256×256輸入圖像将在每個像素處應用一個核心,并且輸出将是與輸入圖像相同的寬度和高度。隻要邁出4步,相同的輸入圖像就隻能每四個像素應用一次核心,是以輸出将隻有64×64。典型的步幅值小于核心的大小,這意味着在可視化核心應用程式的圖表中,其中很多值實際上會在邊緣重疊。
GEMM如何處理卷積解決方案
這似乎是一個相當專門的操作。它涉及大量的乘法和求和,比如完全連接配接層,但不清楚如何或為什麼要将其變成GEMM的矩陣乘法。最後我将讨論動機,但這個操作是如何用矩陣乘法表示的
第一步是将來自一個實際上是一個三維數組的圖像的輸入變成一個二維數組,我們可以像一個矩陣一樣處理。應用每個核心的地方是圖像中的一個小三維多元方體,是以我們提取每個輸入值的多元方體,并将它們作為一列複制到一個矩陣中。這被稱為im2col,對于圖像到列,我相信從一個原始的Matlab函數,下面是我如何可視化它的:
如果步幅小于核心大小,你可能會對我們進行此轉換時發生的記憶體大小的擴充感到震驚。這意味着包含在重疊核站點中的像素将在矩陣中被複制,這看起來效率低下,但實際上利大于弊。
現在您有了矩陣形式的輸入圖像,您可以對每個核心的權重執行同樣的操作,将三維多元資料集序列化為行,作為乘法的第二個矩陣。以下是最終的GEMM的外觀:
這裡的“k”是每個更新檔和核心中的值數,是以它是核心寬度*核心高度”深度。結果矩陣是“patches數”列高,按“kernels數”行寬計算。這個矩陣實際上被随後的操作視為一個三維數組,以核心維數作為深度,然後根據它們在輸入圖像中的原始位置将斑塊分割回行和列。
為什麼GEMM适用于卷積
希望您現在可以看到如何将卷積層表示為矩陣乘法,但仍然不清楚您為什麼要這麼做。簡而言之,答案是,科學程式員的格式世界已經花了幾十年時間優化代碼來執行大矩陣到矩陣乘法,而非正常則的記憶體通路模式的好處超過了浪費的存儲成本。這篇來自Nvidia的論文(文末附下載下傳方式)很好地介紹了一些不同的方法,但他們也描述了為什麼他們最終以一個修改版本的GEMM作為他們最喜歡的方法。同時對相同的核心批處理大量輸入圖像還有很多優點,本文關于《Caffe con troll》的論文(文末附下載下傳方式)使用了非常好的效果。GEMM方法的主要競争對手是使用傅裡葉變換在頻率空間中進行操作,但在卷積中使用步進使其難以如此有效。
好消息是,擁有一個單一的、被充分了解的算法(即GEMM)占據了我們的大部分時間,這為優化速度和功率的使用提供了一條非常清晰的路徑,無論是通過更好的軟體實作,還是通過定制硬體來很好地運作操作。因為深度網絡已被證明對跨語音、NLP和計算機視覺的大量應用程式有用,是以我期待看到未來幾年的巨大改進,就像對3D遊戲的廣泛需求通過迫使頂點和像素處理操作的革命,推動了GPU的革命。
論文:cuDNN: Efficient Primitives for Deep Learning
位址:https://arxiv.org/pdf/1410.0759.pdf
論文:Caffe con Troll: Shallow Ideas to Speed Up Deep Learning
位址:https://arxiv.org/pdf/1504.04343v1.pdf
擷取方式:公衆号中回複“0002”可擷取
原文連結:
https://petewarden.com/2015/04/20/why-gemm-is-at-the-heart-of-deep-learning/
本文來源于公衆号 CV技術指南 的論文分享系列。
歡迎關注公衆号 CV技術指南 ,專注于計算機視覺的技術總結、最新技術跟蹤、經典論文解讀。
在公衆号中回複關鍵字 “技術總結” 可擷取以下文章的彙總pdf。
其它文章
使用深度神經網絡為什麼8位足夠?
經典論文系列 | 目标檢測--CornerNet & 又名 anchor boxes的缺陷
如何看待人工智能的泡沫
使用Dice loss實作清晰的邊界檢測
PVT--無卷積密集預測的多功能backbone
CVPR2021 | 開放世界的目标檢測
Siamese network總結
視覺目标檢測和識别之過去,現在及可能
在做算法工程師的道路上,你掌握了什麼概念或技術使你感覺自我提升突飛猛進?
計算機視覺專業術語總結(一)建構計算機視覺的知識體系
欠拟合與過拟合技術總結
歸一化方法總結
論文創新的常見思路總結
CV方向的高效閱讀英文文獻方法總結
計算機視覺中的小樣本學習綜述
知識蒸餾的簡要概述
優化OpenCV視訊的讀取速度
NMS總結
損失函數技術總結
注意力機制技術總結
特征金字塔技術總結
池化技術總結
資料增強方法總結
CNN結構演變總結(一)經典模型
CNN結構演變總結(二)輕量化模型
CNN結構演變總結(三)設計原則
如何看待計算機視覺未來的走向
CNN可視化技術總結(一)特征圖可視化
CNN可視化技術總結(二)卷積核可視化
CNN可視化技術總結(三)類可視化
CNN可視化技術總結(四)可視化工具與項目