程式員的成長之路
網際網路/程式員/技術/資料共享
閱讀本文大概需要 15 分鐘。
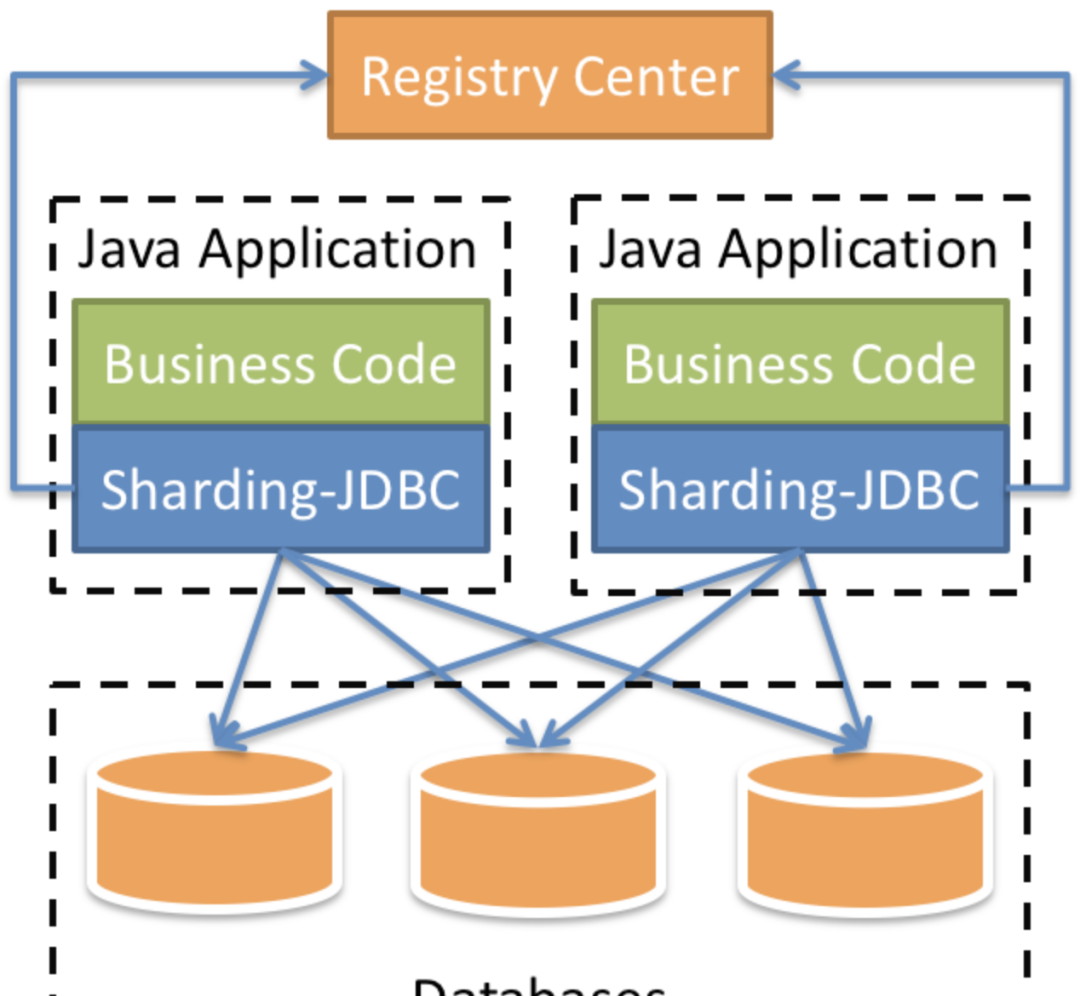
ShardingSphere-Jdbc定位為輕量級Java架構,在Java的Jdbc層提供的額外服務。它使用用戶端直連資料庫,以jar包形式提供服務,可了解為增強版的Jdbc驅動,完全相容Jdbc和各種ORM架構
1)建立主伺服器所需目錄
2)定義主伺服器配置檔案
3)建立并啟動mysql主服務
4)添加複制master資料的使用者reader,供從伺服器使用
5)建立從伺服器所需目錄,編輯配置檔案
6)建立并運作mysql從伺服器
7)在從伺服器上配置連接配接主伺服器的資訊
首先主伺服器上檢視<code>master_log_file</code>、<code>master_log_pos</code>兩個參數,然後切換到從伺服器上進行主伺服器的連接配接資訊的設定
主服務上執行:
docker檢視主伺服器容器的ip位址
從伺服器上執行:
8)從伺服器啟動I/O 線程和SQL線程
Slave_IO_Running: Yes,Slave_SQL_Running: Yes即表示啟動成功
1)redo log(重做日志)
InnoDB首先将redo log放入到redo log buffer,然後按一定頻率将其重新整理到redo log file
下列三種情況下會将redo log buffer重新整理到redo log file:
Master Thread每一秒将redo log buffer重新整理到redo log file
每個事務送出時會将redo log buffer重新整理到redo log file
當redo log緩沖池剩餘空間小于1/2時,會将redo log buffer重新整理到redo log file
MySQL裡常說的WAL技術,全稱是Write Ahead Log,即當事務送出時,先寫redo log,再修改頁。也就是說,當有一條記錄需要更新的時候,InnoDB會先把記錄寫到redo log裡面,并更新Buffer Pool的page,這個時候更新操作就算完成了
Buffer Pool是實體頁的緩存,對InnoDB的任何修改操作都會首先在Buffer Pool的page上進行,然後這樣的頁将被标記為髒頁并被放到專門的Flush List上,後續将由專門的刷髒線程階段性的将這些頁面寫入磁盤
InnoDB的redo log是固定大小的,比如可以配置為一組4個檔案,每個檔案的大小是1GB,循環使用,從頭開始寫,寫到末尾就又回到開頭循環寫(順序寫,節省了随機寫磁盤的IO消耗)

Write Pos是目前記錄的位置,一邊寫一邊後移,寫到第3号檔案末尾後就回到0号檔案開頭。Check Point是目前要擦除的位置,也是往後推移并且循環的,擦除記錄前要把記錄更新到資料檔案
Write Pos和Check Point之間空着的部分,可以用來記錄新的操作。如果Write Pos追上Check Point,這時候不能再執行新的更新,需要停下來擦掉一些記錄,把Check Point推進一下
當資料庫發生當機時,資料庫不需要重做所有的日志,因為Check Point之前的頁都已經重新整理回磁盤,隻需對Check Point後的redo log進行恢複,進而縮短了恢複的時間
當緩沖池不夠用時,根據LRU算法會溢出最近最少使用的頁,若此頁為髒頁,那麼需要強制執行Check Point,将髒頁重新整理回磁盤
2)binlog(歸檔日志)
MySQL整體來看就有兩塊:一塊是Server層,主要做的是MySQL功能層面的事情;還有一塊是引擎層,負責存儲相關的具體事宜。redo log是InnoDB引擎特有的日志,而Server層也有自己的日志,稱為binlog
binlog記錄了對MySQL資料庫執行更改的所有操作,不包括SELECT和SHOW這類操作,主要作用是用于資料庫的主從複制及資料的增量恢複
使用mysqldump備份時,隻是對一段時間的資料進行全備,但是如果備份後突然發現資料庫伺服器故障,這個時候就要用到binlog的日志了
binlog格式有三種:STATEMENT,ROW,MIXED
STATEMENT模式:binlog裡面記錄的就是SQL語句的原文。優點是并不需要記錄每一行的資料變化,減少了binlog日志量,節約IO,提高性能。缺點是在某些情況下會導緻master-slave中的資料不一緻
ROW模式:不記錄每條SQL語句的上下文資訊,僅需記錄哪條資料被修改了,修改成什麼樣了,解決了STATEMENT模式下出現master-slave中的資料不一緻。缺點是會産生大量的日志,尤其是alter table的時候會讓日志暴漲
MIXED模式:以上兩種模式的混合使用,一般的複制使用STATEMENT模式儲存binlog,對于STATEMENT模式無法複制的操作使用ROW模式儲存binlog,MySQL會根據執行的SQL語句選擇日志儲存方式
3)redo log和binlog日志的不同
redo log是InnoDB引擎特有的;binlog是MySQL的Server層實作的,所有引擎都可以使用
redo log是實體日志,記錄的是在某個資料也上做了什麼修改;binlog是邏輯日志,記錄的是這個語句的原始邏輯,比如給ID=2這一行的c字段加1
redo log是循環寫的,空間固定會用完;binlog是可以追加寫入的,binlog檔案寫到一定大小後會切換到下一個,并不會覆寫以前的日志
4)兩階段送出
執行器和InnoDB引擎在執行這個update語句時的内部流程:
執行器先找到引擎取ID=2這一行。ID是主鍵,引擎直接用樹搜尋找到這一行。如果ID=2這一行所在的資料也本來就在記憶體中,就直接傳回給執行器;否則,需要先從磁盤讀入記憶體,然後再傳回
執行器拿到引擎給的行資料,把這個值加上1,得到新的一行資料,再調用引擎接口寫入這行新資料
引擎将這行新資料更新到記憶體中,同時将這個更新操作記錄到redo log裡面,此時redo log處于prepare狀态。然後告知執行器執行完成了,随時可以送出事務
執行器生成這個操作的binlog,并把binlog寫入磁盤
執行器調用引擎的送出事務接口,引擎把剛剛寫入的redo log改成送出狀态,更新完成
update語句的執行流程圖如下,圖中淺色框表示在InnoDB内部執行的,深色框表示是在執行器中執行的
将redo log的寫入拆成了兩個步驟:prepare和commit,這就是兩階段送出
從庫B和主庫A之間維持了一個長連接配接。主庫A内部有一個線程,專門用于服務從庫B的這個長連接配接。一個事務日志同步的完整過程如下:
在從庫B上通過change master指令,設定主庫A的IP、端口、使用者名、密碼,以及要從哪個位置開始請求binlog,這個位置包含檔案名和日志偏移量
在從庫B上執行start slave指令,這時從庫會啟動兩個線程,就是圖中的I/O線程和SQL線程。其中I/O線程負責與主庫建立連接配接
主庫A校驗完使用者名、密碼後,開始按照從庫B傳過來的位置,從本地讀取binlog,發給B
從庫B拿到binlog後,寫到本地檔案,稱為中繼日志
SQL線程讀取中繼日志,解析出日志裡的指令,并執行
由于多線程複制方案的引入,SQL線程演化成了多個線程
主從複制不是完全實時地進行同步,而是異步實時。這中間存在主從服務之間的執行延時,如果主伺服器的壓力很大,則可能導緻主從伺服器延時較大
1)、建立Springboot工程,引入相關依賴
2)、application.properties配置檔案
3)、建立t_user表
4)、定義Controller、Mapper、Entity
5)、驗證
啟動日志中三個資料源初始化成功:
調用<code>http://localhost:8080/api/user/save</code>一直進入到ds1主節點
調用<code>http://localhost:8080/api/user/findUsers</code>一直進入到ds2、ds3節點,并且輪詢進入
水準拆分:同一個表的資料拆到不同的庫不同的表中。可以根據時間、地區或某個業務鍵次元,也可以通過hash進行拆分,最後通過路由通路到具體的資料。拆分後的每個表結構保持一緻
垂直拆分:就是把一個有很多字段的表給拆分成多個表,或者是多個庫上去。每個庫表的結構都不一樣,每個庫表都包含部分字段。一般來說,可以根據業務次元進行拆分,如訂單表可以拆分為訂單、訂單支援、訂單位址、訂單商品、訂單擴充等表;也可以,根據資料冷熱程度拆分,20%的熱點字段拆到一個表,80%的冷字段拆到另外一個表
一般資料庫的拆分也是有一個過程的,一開始是單表,後面慢慢拆成多表。那麼我們就看下如何平滑的從MySQL單表過度到MySQL的分庫分表架構
利用MySQL+Canal做增量資料同步,利用分庫分表中間件,将資料路由到對應的新表中
利用分庫分表中間件,全量資料導入到對應的新表中
通過單表資料和分庫分表資料兩兩比較,更新不比對的資料到新表中
資料穩定後,将單表的配置切換到分庫分表配置上
使用者資料根據訂單id%2拆分為2個表,分别是:t_order0和t_order1。他們的邏輯表名是:t_order
多資料源相同表:
多資料源不同表:
單庫分表:
全部手動指定:
上面的配置通過user_id%2來決定具體資料源,通過order_id%2來決定具體表
<code>insert into t_order(user_id,order_id) values(2,3),user_id%2 = 0</code>使用資料源ds0,<code>order_id%2 = 1</code>使用t_order1,insert語句最終操作的是資料源ds0的t_order1表。
Sharding-Jdbc可以配置分布式主鍵生成政策。預設使用雪花算法(snowflake),生成64bit的長整型資料,也支援UUID的方式
需求:
對1000w的使用者資料進行分庫分表,對使用者表的資料進行分表和分庫的操作。根據年齡奇數存儲在t_user1,偶數t_user0,同時性别奇數存儲在ds1,偶數ds0
表結構:
兩個資料庫中都包含t_user0和t_user1兩張表
application.properties:
測試類:
官方文檔:
https://shardingsphere.apache.org/document/current/cn/overview/
視訊資料:
https://www.bilibili.com/video/BV1ei4y1K7dn
<END>