摘要:在整合開源能力的同時,MRS HetuEngine相較于開源社群也做了大量的優化,其中一個重要的特性就是On Yarn。
本文分享自華為雲社群《MRS HetuEngine 特性之 On Yarn原理介紹》,作者:一顆檸檬 。
HetuEngine是華為自研高性能分布式SQL查詢&資料虛拟化引擎。與大資料生态無縫融合,實作海量資料秒級查詢;支援多源異構協同,使能資料湖内一站式SQL融合分析。在整合開源能力的同時,MRS HetuEngine相較于開源社群也做了大量的優化,其中一個重要的特性就是On Yarn。本文介紹HetuEngine實作On Yarn的原理,通過閱讀本文,讀者可以了解HetuEngine如何在資源使用方面融入Hadoop生态體系。
顧名思義,就是将程序運作在Yarn上,由Yarn進行資源的管理和排程。
不論是TrinoDB/PrestoDB還是openLooKeng,部署方式都是将coordinator和worker程序直接運作在主機上,與主機上的其他應用程式共享資源,無法做到資源隔離,并且難以擴充。
MRS HetuEngine借助Yarn Service提供的能力,将coordinator和worker程序以Yarn application的形式運作在Yarn container中,通過MRS叢集的租戶劃分,可以将HetuEngine計算執行個體啟動在特定租戶隊列裡,進而實作資源隔離。
下圖是HetuEngine的拓撲圖。HetuEngine向下可以對接各類資料源(比如Hive,GaussDB,HBASE,Elasticsearch等),對外向使用者提供CLI/JDBC接口。在同一套MRS叢集中,HetuEngine可以在不同租戶隊列中啟動多個HetuEngine計算執行個體,支援一個租戶隊列上啟動一個計算執行個體。由HetuEngine的HSBroker執行個體與Yarn Service互動,将租戶隊列與計算執行個體綁定,由HSConsole提供運維管理頁面,對HetuEngine的多個計算執行個體進行運維管理操作,包括啟動、停止、删除計算執行個體,對計算執行個體進行資源配置,擴縮容等。
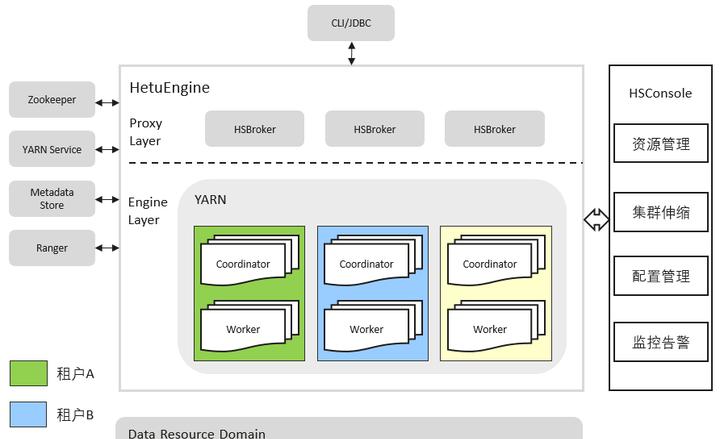
如前所述,On Yarn就是把程序運作在了Yarn 的container中。HetuEngine 是如何實作将coordinator 和worker運作中Yarn中呢?
Yarn Service提供了一系列API以及一個通用的AM,讓使用者可以調用API即可将任務送出到Yarn上,由Yarn實作任務的容器化,對容器進行資源和生命周期管理。詳細請參考開源社群的介紹。https://hadoop.apache.org/docs/r3.1.0/hadoop-yarn/hadoop-yarn-site/yarn-service/Overview.html
HetuEngine的 On Yarn實作正是借助了Yarn Service所提供的能力。在HetuEngine的HSBroker中,調用Yarn Service的API,拉起application,在container中運作HetuEngine自己的程序,也就是coordinator和worker。其中有以下幾個關鍵點:
建立一個Yarn Service服務的接口是/app/v1/services,參數json結構如下。
name:服務名稱,顯示在Yarn的resource manager WEB界面servicename;
version:版本号
description:服務的描述
components:一個service中可以包含多個component,以運作不同的任務;
components.name:component名稱
number_of_containers:此component中container的數量;
artifact:程序依賴的資源檔案,包含id和type資訊,type支援docker和tarball
launch_command:程序啟動指令
resource:此component所需的資源。
HetuEngine的HSBroker根據使用者輸入構造此json,然後調用Yarn Service API,實作On Yarn。此外Yarn Service還提供stop/delete等API,也由HSBroker調用,實作對HetuEngine計算執行個體的停止/删除等運維操作。
Yarn Service支援資源檔案在HDFS上的形式啟動程序,其提供的API可以接收tar包以及docker等形式的資源檔案,由Yarn Service自行将HDFS上的檔案進行資源本地化。是以,HetuEngine隻需将依賴的jar包和資源檔案提前部署在HDFS上的指定位置,在調用Yarn Service的API時指定資源檔案即可。

HetuEngine支援将計算執行個體與Yarn的租戶隊列綁定,每個隊列上都可以運作一套coordinator + worker的組合。基于前面Yarn Service能力,隻需在構造json時,指定隊列資訊即可。除了隊列,還可以設定container的放置政策(plecement policy),這裡不進行詳述,可以參考yarn的文檔。
HetuEngine支援使用者自定義coordinator和worker的個數以及CPU記憶體大小。如下圖,在HetuEngine的HSConsole頁面,使用者可以設定計算執行個體的CPU,記憶體,節點個數。内部實作是由HSBroker接收使用者輸入,将container運作所需的資源大小設定在json的resource段中。
目前HetuEngine支援橫向擴充worker的個數,實作資源的彈性伸縮。即使在計算執行個體處于運作中時,也可以手動調整worker的個數,無需重新開機計算執行個體。這得益于Yarn Service的API中提供的flex接口,可以實作向一個運作中的application增加或者減少container的數量。
HetuEngine的計算執行個體建立完成後,使用者可以通過hetu-cli或者JDBC程式進行通路,需要使用者綁定對應的租戶隊列權限,才能向指定的隊列送出任務。
Hetu CLI示例:
租戶名:(可選)租戶名。指定HetuEngine啟動的租戶資源隊列,不指定為租戶的預設隊列。使用此參數時,kinit的使用者需要具有該租戶對應角色的權限。
Hetu JDBC示例:
本文主要介紹了HetuEngine On Yarn的原理,其實作主要是借助了Yarn Service提供的能力,感興趣的讀者可以深入閱讀開源社群相關的介紹。
點選關注,第一時間了解華為雲新鮮技術~