摘要:采用多主執行個體模式的HA方案,不僅可以規避主備切換服務中斷的問題,實作服務不中斷或少中斷,還可以通過橫向擴充叢集來提高并發能力。
本文分享自華為雲社群《FusionInsight Spark支援JDBCServer的多執行個體特性介紹》,作者: 一枚核桃。
基于社群已有的JDBCServer基礎上,采用多主執行個體模式實作了其高可用性方案。叢集中支援同時共存多個JDBCServer服務,通過用戶端可以随機連接配接其中的任意一個服務進行業務操作。即使叢集中一個或多個JDBCServer服務停止工作,也不影響使用者通過同一個用戶端接口連接配接其他正常的JDBCServer服務。
多主執行個體模式相比主備模式的HA方案,優勢主要展現在對以下兩種場景的改進。
主備模式下,當發生主備切換時,會存在一段時間内服務不可用,該時間JDBCServer無法控制,取決于Yarn服務的資源情況。
Spark中通過類似于HiveServer2的Thrift JDBC提供服務,使用者通過Beeline以及JDBC接口通路。是以JDBCServer叢集的處理能力取決于主Server的單點能力,可擴充性不夠。
采用多主執行個體模式的HA方案,不僅可以規避主備切換服務中斷的問題,實作服務不中斷或少中斷,還可以通過橫向擴充叢集來提高并發能力。
多主執行個體模式的HA方案原理如下圖所示。
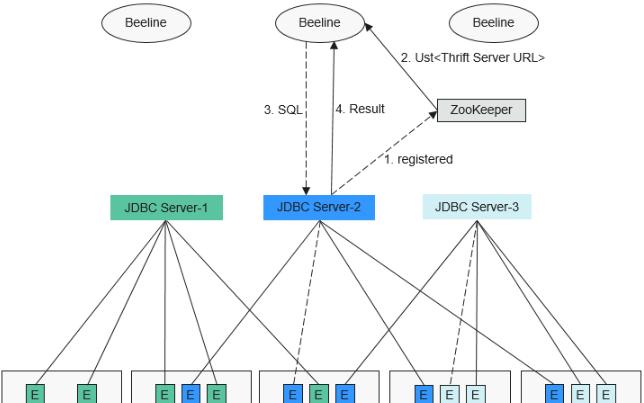
1、JDBCServer在啟動時,向ZooKeeper注冊自身消息,在指定目錄中寫入節點,節點包含了該執行個體對應的IP,端口,版本号和序列号等資訊(多節點資訊之間以逗号隔開)。
示例如下:
3、用戶端成功連接配接JDBCServer服務後,向JDBCServer服務發送SQL語句。
4、JDBCServer服務執行用戶端發送的SQL語句後,将結果傳回給用戶端。
在HA方案中,每個JDBCServer服務(即執行個體)都是獨立且等同的,當其中一個執行個體在更新或者業務中斷時,其他的執行個體也能接受用戶端的連接配接請求。
多主執行個體方案遵循以下規則:
當一個執行個體異常退出時,其他執行個體不會接管此執行個體上的會話,也不會接管此執行個體上運作的業務。
當JDBCServer程序停止時,删除在ZooKeeper上的相應節點。
由于用戶端選擇服務端的政策是随機的,可能會出現會話随機配置設定不均勻的情況,進而可能引起執行個體間的負載不均衡。
執行個體進入維護模式(即進入此模式後不再接受新的用戶端連接配接)後,當達到退服逾時時間,仍在此執行個體上運作的業務有可能會發生失敗。
多主執行個體模式的用戶端讀取ZooKeeper節點中的内容,連接配接對應的JDBCServer服務。連接配接字元串為:
安全模式下:
Kinit認證方式下的JDBCURL如下所示:
其中“<zkNode_IP>:<zkNode_Port>”是ZooKeeper的URL,多個URL以逗号隔開。
例如:“192.168.81.37:24002,192.168.195.232:24002,192.168.169.84:24002”。
其中“sparkthriftserver2x”是ZooKeeper上的目錄,表示用戶端從該目錄下随機選擇JDBCServer執行個體進行連接配接。
示例:安全模式下通過Beeline用戶端連接配接時執行以下指令:
Keytab認證方式下的JDBCURL如下所示:
普通模式下:
非多主執行個體模式的用戶端連接配接的是某個指定JDBCServer節點。該模式的連接配接字元串相比多主執行個體模式的去掉關于Zookeeper的參數項“serviceDiscoveryMode”和“zooKeeperNamespace”。
示例:安全模式下通過Beeline用戶端連接配接非多主執行個體模式時執行以下指令:
其中“<server_IP>:<server_Port>”是指定JDBCServer節點的URL。
“CLIENT_HOME”是指用戶端路徑。
多主執行個體模式與非多主執行個體模式兩種模式的JDBCServer接口相比,除連接配接方式不同外其他使用方法相同。由于Spark JDBCServer是Hive中的HiveServer2的另外一個實作,具體使用方法,請參見Hive官網:https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients。
點選關注,第一時間了解華為雲新鮮技術~
![jdk1.7+Eclipse+Maven3.5+Hadoop2.7.3建構hadoop項目[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)