模型融合有幾大缺點:
1.預測時間長
2.工程上實作麻煩
3.準确率提高不大,時間卻過長
在工程上進行模型融合,需要考慮:
1.穩定
2.預測時間
3.部署
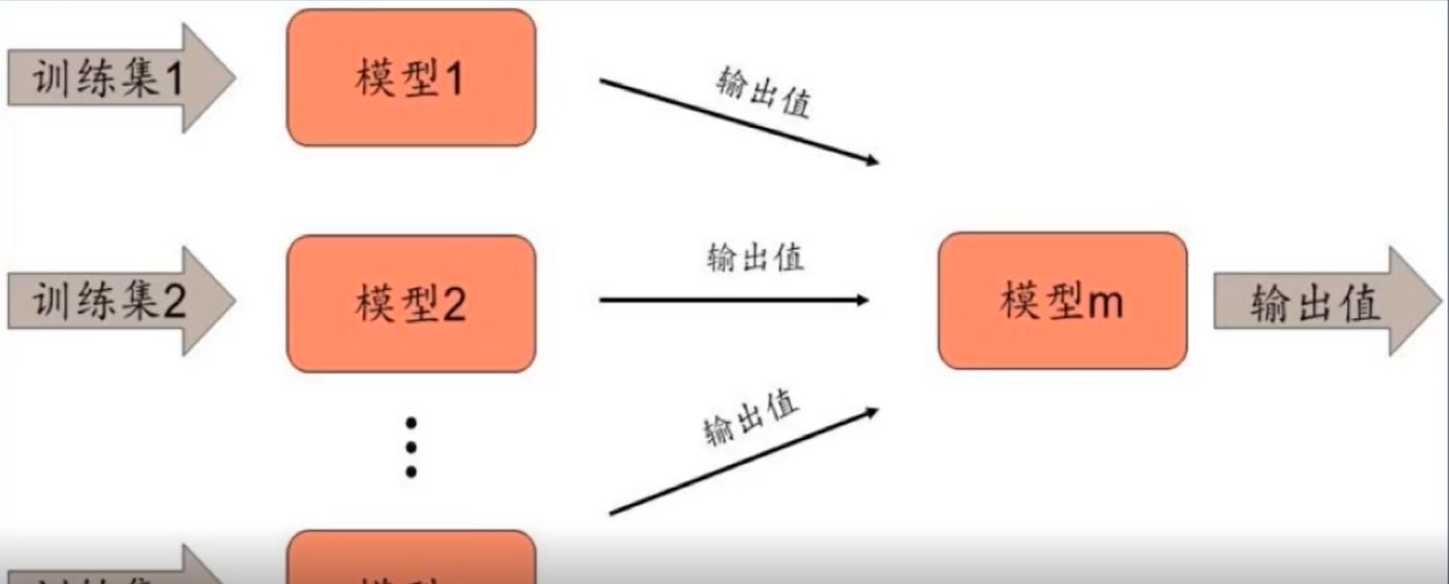
推薦系統版(模型融合):

內建學習:
Error = Bias + Variance
<code>Error:</code>反映的是整個模型的準确度,
<code>Bias:</code>反映的是模型在樣本上的輸出與真實值之間的誤差,即模型本身的精準度,
<code>Variance:</code>反映的是模型每一次輸出結果與模型輸出期望之間的誤差,即模型的穩定性。
bias: 描述的是根據樣本拟合出的模型的輸出預測結果的期望與樣本真實結果的差距,簡單
講,就是在樣本上拟合的好不好。要想在bias. 上表現好,low bias,就得複雜化模型,增加模型
的參數,但這樣容易過拟合(overfiting),過拟合對應上圖是high variance,點很分散。low
bias對應就是點都打在靶心附近,是以瞄的是準的,但手不一定穩。
varience: 描述的是樣本上訓練出來的模型在測試集_上的表現,要想在variance.上表現好,
low varience,就要簡化模型,減少模型的參數,但這樣容易欠拟合(unfitting),欠拟合對應上
圖是high bias,點偏離中心。low variance對應就是點都打的很集中,但不一定是靶心附近,手
很穩,但是瞄的不準。
方差在圖中顯示的就是聚集程度
偏差在圖中顯示的就是離目标的偏離程度
Bagging主要就是用來降低方差的,是以一般要選擇偏差小的模型,因為Bagging不怎麼降低bias
(是以還有Boosting的模型融合,這個就主要可以降低bias)
随機森林:在裡面的每棵樹中,抽取的資料集和選擇的特征量都會不同,是以很降低variance
殘差在數理統計中是指實際觀察值與估計值(拟合值)之間的差。“殘差”蘊含了有關模型基本假設的重要資訊。如果回歸模型正确的話, 我們可以将殘差看作誤差的觀測值。
難樣本再學習
經典案例:focus__loss
預測值如果加上原始值,會使模型更加穩定
5折交叉驗證:即把資料集分成5份,4份作為訓練,1份作為驗證(預測)
轉載于(推薦閱讀):
https://zhuanlan.zhihu.com/p/61705517
https://blog.csdn.net/u011630575/article/details/81302994
https://www.zhihu.com/question/27068705
偏差(Bias)和方差(Variance)——機器學習中的模型選擇
融合模型是提升機器學習的有效辦法,無論是學習、競賽、工作無處不在,應是算法學習者必會的知識技能。
常見的內建學習&模型融合方法包括:
Voting/Averaging(分别對于分類和回歸問題)
Stacking
Boosting
Bagging
Linear Blending
1.Voting/Averaging
2.Stacking–模型後面接模型,做殘差
3.Boosting
4.Bagging
5.Linear Blending
6.
7.
8.
9.
0.
在不改變模型的情況下,直接對各個不同的模型預測的結果,進行投票或者平均,這是一種簡單卻行之有效的融合方式。
比如對于分類問題,假設有三個互相獨立的模型,每個正确率都是70%,采用少數服從多數的方式進行投票。那麼最終的正确率将是:
即結果經過簡單的投票,使得正确率提升了8%。這是一個簡單的機率學問題——如果進行投票的模型越多,那麼顯然其結果将會更好。但是其前提條件是模型之間互相獨立,結果之間沒有相關性。越相近的模型進行融合,融合效果也會越差。
可見模型之間差異越大,融合所得的結果将會更好。//這種特性不會受融合方式的影響。
對于回歸問題,對各種模型的預測結果進行平均,所得到的結果通過能夠減少過拟合,并使得邊界更加平滑,單個模型的邊界可能很粗糙。這是很直覺的性質,如下圖。
在上述融合方法的基礎上,一個進行改良的方式是對各個投票者/平均者配置設定不同的權重以改變其對最終結果影響的大小。對于正确率低的模型給予更低的權重,而正确率更高的模型給予更高的權重。這也是可以直覺了解的——想要推翻專家模型(高正确率模型)的唯一方式,就是臭皮匠模型(低正确率模型)同時投出相同選項的反對票。具體的對于權重的指派,可以用正确率排名的正則化等。
這種方法看似簡單,但是卻是各種“進階”方法的基礎。
模型融合執行個體簡介