首先先談一下程式計數器(Program Counter),計算機中提供要從存儲器中取出的下一個指令位址的寄存器,通常情況下,每一個指令取出後寄存器就自動增加一步就如《微機原理》當中的 PC = PC + 1 ,在 x86 體系裡是這樣。x86 系統中自增的是 IP,用 CS:IP 組合表示正在執行的指令位址,此時 PC 隻是一個概念上的說法。在 ARM 體系中 R15 就是 PC,當然 ARM 和 IA-32、x64 都支援進階記憶體管理,是以「PC」的内容未必是目前指令在記憶體中的絕對位置。
CPU 上下文 可以了解成 CPU寄存器狀态以及程式計數器PC , 這些都是記錄CPU目前任務的狀态。CPU 上下文切換 會把目前的cpu的上下文儲存下來,然後加載新任務的對應上下文,而這些儲存下來的上下文,會存儲在系統核心中,并在任務重新排程執行時再次加載進來。這樣就能保證任務原來的狀态不受影響,讓任務看起來還是連續運作。
任務一般包括:
1.程序
2.線程
3.中斷上下文
CPU 上下文的切換會因特權模式切換、程序上下文切換、線程上下文切換以及中斷上下文切換 産生。
特權模式切換
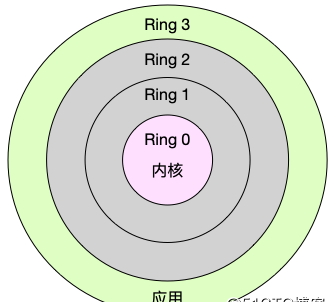
Linux 按照特權等級,把程序的運作空間分為核心空間和使用者空間,分别對應着下圖中, CPU 特權等級的 Ring 0 和 Ring 3。核心空間(Ring 0)具有最高權限,可以直接通路所有資源;使用者空間(Ring 3)隻能通路受限資源,不能直接通路記憶體等硬體裝置,必須通過系統調用陷入到核心中,才能通路這些特權資源。
程序可以在使用者空間運作,也可以在核心空間運作。 當調用open()、read()、write()、close()系統函數,CPU會儲存原來使用者态的指令位置,然後更新CPU寄存器核心态指令的新位置。最後執行核心态函數。當系統調用結束後,CPU恢複原來的使用者态,切換回使用者空間繼續執行程序。
可以看到 使用者态->核心态, 核心态->使用者态 這兩個過程總共是産生了兩次CPU上下文切換。不過,需要注意的是,系統調用過程中,并不會涉及到虛拟記憶體等程序使用者态的資源
程序上下文切換
程序上下文不僅包括了虛拟記憶體、棧、全局變量等使用者空間的資源,還包括了核心堆棧、寄存器等核心空間的狀态,與系統調用相比程序間的切換還需要把内容儲存下來。
程序上下文切換數量多,容易導緻CPU花費更多的時間在寄存器、虛拟記憶體、核心棧等資源的儲存和恢複上,減少了程序運作時間,緻使平均負載升高。Linux 通過 TLB(Translation Lookaside Buffer)來管理虛拟記憶體到實體記憶體的映射關系。當虛拟記憶體更新後,TLB 也需要重新整理,記憶體的通路也會随之變慢。特别是在多處理器系統上,緩存是被多個處理器共享的,重新整理緩存不僅會影響目前處理器的程序,還會影響共享緩存的其他處理器的程序。

程序上下文切換發生在程序排程的過程。
主要在以下場景觸發:
CPU時間是被劃分成各個時間片,目前程序的時間片被耗盡之後會被系統挂起,切換到其他正在等待CPU的程序來運作。
程序在系統資源不足(比如記憶體不足)時,要等到資源滿足後才可以運作,這個時候程序也會被挂起,并由系統排程其他程序運作。
當程序通過睡眠函數 sleep 或者 sched_yield 這樣的方法将自己主動挂起時,自然也會重新排程。
當有優先級更高的程序運作時,為了保證高優先級程序的運作,目前程序會被挂起,由高優先級程序來運作。
發生硬體中斷時,CPU 上的程序會被中斷挂起,轉而執行核心中的中斷服務程式。
線程上下文切換
線程與程序最大的差別在于,線程是排程的基本機關,而程序則是資源擁有的基本機關。linux核心中的任務排程,實際上的排程對象是線程;而程序隻是給線程提供了虛拟記憶體、全局變量等資源。程序中隻有一個線程,程序等于線程。因為同一程序下線程是共享虛拟記憶體,相關間的切換隻需儲存其私有資料、寄存器等,是以程序内的線程切換比程序間的切換消耗更少資源。
中斷上下文切換
為了快速響應硬體的事件,中斷處理會打斷程序的正常排程和執行,轉而調用中斷處理程式,響應裝置事件。而在打斷其他程序時,就需要将程序目前的狀态儲存下來,這樣在中斷結束後,程序仍然可以從原來的狀态恢複運作。跟程序上下文不同,中斷上下文切換并不涉及到程序的使用者态。是以,即便中斷過程打斷了一個正處在使用者态的程序,也不需要儲存和恢複這個程序的虛拟記憶體、全局變量等使用者态資源。中斷上下文,其實隻包括核心态中斷服務程式執行所必需的狀态,包括 CPU 寄存器、核心堆棧、硬體中斷參數等。對同一個 CPU 來說,中斷處理比程序擁有更高的優先級,是以中斷上下文切換并不會與程序上下文切換同時發生。同樣道理,由于中斷會打斷正常程序的排程和執行,是以大部分中斷處理程式都短小精悍,以便盡可能快的執行結束。另外,跟程序上下文切換一樣,中斷上下文切換也需要消耗 CPU,切換次數過多也會耗費大量的 CPU,甚至嚴重降低系統的整體性能。是以,當你發現中斷次數過多時,就需要注意去排查它是否會給你的系統帶來嚴重的性能問題。
CPU上下文切分析
vmstat 是一個常用的系統性能分析工具,主要用來分析系統的記憶體使用情況,也常用來分析 CPU 上下文切換和中斷的次數。
root@ECSab169d:~# vmstat 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 90720 3960176 1036 3014980 0 0 35 85 0 1 1 0 98 0 0
0 0 90720 3959928 1036 3015004 0 0 0 24 240 358 0 0 99 0 0
0 1 90720 3959356 1036 3015068 0 0 0 34 260 390 1 0 99 0 0
0 0 90720 3959204 1036 3015088 0 0 0 23 234 340 0 0 99 0 0
0 0 90720 3960708 1036 3015088 0 0 0 609 297 429 0 0 99 0 0
0 0 90720 3960772 1036 3015112 0 0 0 140 295 410 0 0 99 0 0
0 0 90720 3960688 1036 3015164 0 0 0 36 269 406 0 0 99 0 0 r 是就緒隊列的長度,也就是正在運作和等待 CPU 的程序數。
b 則是處于不可中斷睡眠狀态的程序數
swpd 交換分區大小,一般在記憶體不足的情況會使用swap進行擴充。
free 空閑的實體記憶體的大小,我的機器記憶體總共8G,剩餘3415M。
buff Linux/Unix系統是用來存儲,目錄裡面有什麼内容,權限等的緩存,我本機大概占用300多M
cache cache直接用來記憶我們打開的檔案,給檔案做緩沖,我本機大概占用300多M(這裡是Linux/Unix的聰明之處,把空閑的實體記憶體的一部分拿來做檔案和目錄的緩存,是為了提高 程式執行的性能,當程式使用記憶體時,buffer/cached會很快地被使用。)
si 每秒從磁盤讀入虛拟記憶體的大小,如果這個值大于0,表示實體記憶體不夠用或者記憶體洩露了,要查找耗記憶體程序解決掉。我的機器記憶體充裕,一切正常。
so 每秒虛拟記憶體寫入磁盤的大小,如果這個值大于0,同上。
bi 塊裝置每秒接收的塊數量,這裡的塊裝置是指系統上所有的磁盤和其他塊裝置,預設塊大小是1024byte,我本機上沒什麼IO操作,是以一直是0,但是我曾在處理拷貝大量資料(2-3T)的機器上看過可以達到140000/s,磁盤寫入速度差不多140M每秒
bo 塊裝置每秒發送的塊數量,例如我們讀取檔案,bo就要大于0。bi和bo一般都要接近0,不然就是IO過于頻繁,需要調整。
in 每秒CPU的中斷次數,包括時間中斷
cs 每秒上下文切換次數
可以看到,這個例子中的上下文切換次數 cs 是 33 次,而系統中斷次數 in 則是 25 次,而就緒隊列長度 r 和不可中斷狀态程序數 b 都是 0。
vmstat 隻給出了系統總體的上下文切換情況,要想檢視每個程序的詳細情況,就需要使用我們前面提到過的 pidstat 了。給它加上 -w 選項,你就可以檢視每個程序上下文切換的情況了。
root@xxxxx:~# pidstat -w 5
Linux 4.15.0-66-generic (xxxxx) 01/25/2021 _x86_64_ (4 CPU)
05:30:32 PM UID PID cswch/s nvcswch/s Command
05:30:37 PM 0 8 18.16 0.00 rcu_sched
05:30:37 PM 0 11 0.20 0.00 watchdog/0
05:30:37 PM 0 183 4.59 0.00 kworker/3:1H
05:30:37 PM 0 388 2.40 0.00 kworker/0:1H
05:30:37 PM 0 546 0.20 0.00 irqbalance
05:30:37 PM 0 621 9.98 0.00 qemu-ga
05:30:37 PM 109 663 0.40 0.00 uml_switch
05:30:37 PM 0 1275 0.40 0.00 master
05:30:37 PM 110 1277 0.20 0.00 qmgr
05:30:37 PM 0 5896 7.39 0.00 kworker/0:0
05:30:37 PM 0 13579 8.18 0.00 sshd
05:30:37 PM 0 13766 0.20 0.00 vmstat
05:30:37 PM 0 26398 5.19 0.00 kworker/u8:1
05:30:37 PM 0 28341 6.19 0.00 kworker/u8:2
05:30:37 PM 0 28898 5.99 1.40 bash 這個結果中有兩列内容是我們的重點關注對象。一個是 cswch ,表示每秒自願上下文切換(voluntary context switches)的次數,另一個則是 nvcswch ,表示每秒非自願上下文切換(non voluntary context switches)的次數。
謂自願上下文切換: 是指程序無法擷取所需資源,導緻的上下文切換。比如說, I/O、記憶體等系統資源不足時,就會發生自願上下文切換。
非自願上下文切換: 則是指程序由于時間片已到等原因,被系統強制排程,進而發生的上下文切換。比如說,大量程序都在争搶 CPU 時,就容易發生非自願上下文切換。
總結