XGBoost 的全稱為 eXtreme Gradient Boosting,是GBDT的一種高效實作,XGBoost 中的基學習器除了可以是CART(gbtree)也可以是線性分類器(gblinear)。
歡迎大家前往騰訊雲技術社群,擷取更多騰訊海量技術實踐幹貨哦~
作者:張萌
序言
XGBoost效率很高,在Kaggle等諸多比賽中使用廣泛,并且取得了不少好成績。為了讓公司的算法工程師,可以更加友善的使用XGBoost,我們将XGBoost更好地與公司已有的存儲資源和計算平台進行內建,将資料預處理、模型訓練、模型預測、模型評估及可視化、模型收藏及分享等功能,在Tesla平台中形成閉環,同時,資料的流轉實作了與TDW完全打通,讓整個機器學習的流程一體化。
XGBoost介紹
XGBoost的全稱為eXtreme Gradient Boosting,是GBDT的一種高效實作,XGBoost中的基學習器除了可以是CART(gbtree)也可以是線性分類器(gblinear)。
什麼是GBDT?
- GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一種疊代的決策樹算法,該算法由多棵決策樹組成,所有樹的結論累加起來做最終答案。它在被提出之初就和SVM一起被認為是泛化能力(generalization)較強的算法。GBDT的核心在于,每一棵樹學的是之前所有樹結論和的殘差,這個殘差就是一個加預測值後能得真實值的累加量。與随機森林不同,随機森林采用多數投票輸出結果;而GBDT則是将所有結果累加起來,或者權重累加起來。
XGBoost對GBDT的改進
1 . 避免過拟合
目标函數之外加上了正則化項整體求最優解,用以權衡目标函數的下降和模型的複雜程度,避免過拟合。基學習為CART時,正則化項與樹的葉子節點的數量T和葉子節點的值有關。
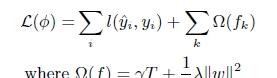
2 . 二階的泰勒展開,精度更高
不同于傳統的GBDT隻利用了一階的導數資訊的方式,XGBoost對損失函數做了二階的泰勒展開,精度更高。
第t次的損失函數:

對上式做二階泰勒展開( g為一階導數,h為二階導數):
3 . 樹節點分裂優化
選擇候選分割點針對GBDT進行了多個優化。正常的樹節點分裂時公式如下:
XGBoost樹節點分裂時,雖然也是通過計算分裂後的某種值減去分裂前的某種值,進而得到增益。但是相比GBDT,它做了如下改進:
- 通過添加門檻值gamma進行了剪枝來限制樹的生成
- 通過添加系數lambda對葉子節點的值做了平滑,防止過拟合。
- 在尋找最佳分割點時,考慮傳統的枚舉每個特征的所有可能分割點的貪心法效率太低,XGBoost實作了一種近似的算法,即:根據百分位法列舉幾個可能成為分割點的候選者,然後從候選者中根據上面求分割點的公式計算找出最佳的分割點。
- 特征列排序後以塊的形式存儲在記憶體中,在疊代中可以重複使用;雖然boosting算法疊代必須串行,但是在處理每個特征列時可以做到并行。
整體上,通過上述的3個優化,加上其易用性,不太需要程式設計,XGBoost目前是GBDT體系中最受歡迎的工具。但是值得留意的是,當資料量很大,尤其是次元很高的情況下,XGBoost的性能會下降較快,這時推進大家可以試試騰訊自己的Angel,其GBDT比XGBoost性能更好噢
TDW體系中的XGBoost介紹
XGBoost在TDW體系中以兩種形式存在
- 提供出了拖拽式的元件,來簡化使用者使用成本
- 提供出了maven依賴,來讓使用者享受Spark Pipeline的流暢
1. Tesla平台上的3個元件:
- XGBoost-spark-ppc元件(基于社群版0.7,以Spark作業形式運作在PowerPC機型的叢集上)
- XGBoost-spark-x86元件(基于社群版0.7,以Spark作業形式運作在x86機型的叢集上)
- XGBoost-yarn元件(基于社群版0.4,以Yarn作業形式運作在x86機型的叢集上)
目前來看,XGBoost的ppc版本,性能比x86的好,建議大家優先選擇。
2. 公司Maven庫中的3個依賴:
- XGBoost4j-ppc(封裝社群版0.7的API,在PowerPC機型上進行的編譯)
- XGBoost4j-x86(封裝社群版0.7的API,在x86機型上進行的編譯)
- XGBoost4j-toolkit(封裝HDFS IO、TDW IO、Model IO等功能)
Tesla中的XGBoost-on-spark元件介紹
Tesla中XGBoost-on-spark元件根據叢集的機型區分成:XGBoost-spark-ppc元件和XGBoost-spark-x86元件。将以前的XGBoost-yarn元件進行了更新,展現在了:
資料源之間的打通、作業調試更友好、IO方式更豐富、資料處理的上下遊延伸更廣、model支援線上服務等方面。
- 資料源之間的打通
- 消除了不同HDFS叢集上的權限問題
- 與TDW打通,資料流轉更順暢,開發成本更低
- 使用者可以不再編寫程式生成LibSVM格式的資料檔案,而是通過Hive或者Spark SQL生成TDW特征表,通過選擇TDW特征表的某些列(selected_cols=1-2,4,8-10),由XGBoost-on-spark元件背景生成libsvm類型的輸入
- 可以針對TDW分區表,借助Tesla作業定時排程機制,可以進行XGBoost作業的例行化排程運作
- 作業調試更友好
- 以Spark作業的形式,而非直接的Yarn作業的形式運作,使用者對作業的運作情況更清楚
- 可以檢視作業的進度
- 可以檢視各節點上的日志資訊
- 以Spark作業的形式,而非直接的Yarn作業的形式運作,使用者對作業的運作情況更清楚
- IO方式更豐富
- 輸入的資料集來源,可以為之前的HDFS上LibSVM格式的檔案形式。也可以為一張TDW表,使用者通過選擇TDW表中的某些列,由XGBoost-on-spark元件在背景生成LibSVM格式的輸入。
- 訓練階段增加了特征重要度(weight、gain、cover)的輸出、以及3種類型model的輸出:文本格式(使用者可以直接檢視)、LocalFile的二進制格式(使用者可以下載下傳到本地,利用python加載後線上預測)、HadoopFile的二進制格式(使用者可以在Tesla環境中,利用Spark加載後離線批量預測)
- 模型輸出的3種格式舉例
4 . 資料處理的上下遊延伸更廣
與Tesla平台深度整合
- 可以拖拽Tesla的元件:資料切分、模型評估,實作資料處理的上下遊功能
- 可以利用Tesla的功能:參數替換、并發設定,進行批量調參
5 . model支援線上服務
- 可以利用Tesla的模型服務,進行模型導出、模型部署、線上預測
總結
XGBoost是機器學習的利器,雖然小巧,但是功能強大,以其被實戰檢驗過的高效,吸引了很多使用者。我們針對使用者痛點進行了諸多改進,實作了使用者在Tesla平台中更加友善的使用,大大減少了使用者的開發成本,同時,我們也開放出了XGBoost API,讓邏輯複雜的業務可以在自身系統中嵌入xgBoost,更加直接的對接TDW系統。後續有進一步的需求,歡迎聯系Tesla團隊,我們将提供更好的機器學習和資料服務。
相關閱讀
當 AI 遇見體育
騰訊 AI Lab 副主任俞棟:過去兩年基于深度學習的聲學模型進展
基于騰訊開源 Angel 的 LDA* 入選國際頂級學術會議 VLDB
此文已由作者授權騰訊雲技術社群釋出,轉載請注明文章出處
原文連結:https://cloud.tencent.com/community/article/794649
海量技術實踐經驗,盡在雲加社群!
https://cloud.tencent.com/developer