接上篇《淺析海量使用者的分布式系統設計(1)》
分布式系統是一個由很多程序組成的整體,這個整體中每個成員部分,都會具備一些狀态,比如自己的負責子產品,自己的負載情況,對某些資料的掌握等等。而這些和其他程序相關的資料,在故障恢複、擴容縮容的時候變得非常重要。
簡單的分布式系統,可以通過靜态的配置檔案,來記錄這些資料:程序之間的連接配接對應關系,他們的IP位址和端口,等等。然而一個自動化程度高的分布式系統,必然要求這些狀态資料都是動态儲存的。這樣才能讓程式自己去做容災和負載均衡的工作。
一些程式員會專門自己編寫一個DIR服務(目錄服務),來記錄叢集中程序的運作狀态。叢集中程序會和這個DIR服務産生自動關聯,這樣在容災、擴容、負載均衡的時候,就可以自動根據這些DIR服務裡的資料,來調整請求的發送目地,進而達到繞開故障機器、或連接配接到新的伺服器的操作。
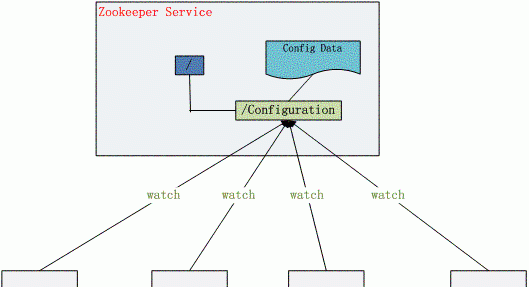
然而,如果我們隻是用一個程序來充當這個工作。那麼這個程序就成為了這個叢集的“單點”——意思就是,如果這個程序故障了,那麼整個叢集可能都無法運作的。是以存放叢集狀态的目錄服務,也需要是分布式的。幸好我們有ZooKeeper這個優秀的開源軟體,它正是一個分布式的目錄服務區。
ZooKeeper可以簡單啟動奇數個程序,來形成一個小的目錄服務叢集。這個叢集會提供給所有其他程序,進行讀寫其巨大的“配置樹”的能力。這些資料不僅僅會存放在一個ZooKeeper程序中,而是會根據一套非常安全的算法,讓多個程序來承載。這讓ZooKeeper成為一個優秀的分布式資料儲存系統。
由于ZooKeeper的資料存儲結構,是一個類似檔案目錄的樹狀系統,是以我們常常會利用它的功能,把每個程序都綁定到其中一個“分枝”上,然後通過檢查這些“分支”,來進行伺服器請求的轉發,就能簡單的解決請求路由(由誰去做)的問題。另外還可以在這些“分支”上标記程序的負載的狀态,這樣負載均衡也很容易做了。
目錄服務是分布式系統中最關鍵的元件之一。而ZooKeeper是一個很好的開源軟體,正好是用來完成這個任務。
兩個程序間如果要跨機器通訊,我們幾乎都會用TCP/UDP這些協定。但是直接使用網絡API去編寫跨程序通訊,是一件非常麻煩的事情。除了要編寫大量的底層socket代碼外,我們還要處理諸如:如何找到要互動資料的程序,如何保障資料包的完整性不至于丢失,如果通訊的對方程序挂掉了,或者程序需要重新開機應該怎樣等等這一系列問題。這些問題包含了容災擴容、負載均衡等一系列的需求。
為了解決分布式系統程序間通訊的問題,人們總結出了一個有效的模型,就是“消息隊列”模型。消息隊列模型,就是把程序間的互動,抽象成對一個個消息的處理,而對于這些消息,我們都有一些“隊列”,也就是管道,來對消息進行暫存。每個程序都可以通路一個或者多個隊列,從裡面讀取消息(消費)或寫入消息(生産)。由于有一個緩存的管道,我們可以放心的對程序狀态進行變化。當程序起來的時候,它會自動去消費消息就可以了。而消息本身的路由,也是由存放的隊列決定的,這樣就把複雜的路由問題,變成了如何管理靜态的隊列的問題。
一般的消息隊列服務,都是提供簡單的“投遞”和“收取”兩個接口,但是消息隊列本身的管理方式卻比較複雜,一般來說有兩種。一部分的消息隊列服務,提倡點對點的隊列管理方式:每對通信節點之間,都有一個單獨的消息隊列。這種做法的好處是不同來源的消息,可以互不影響,不會因為某個隊列的消息過多,擠占了其他隊列的消息緩存空間。而且處理消息的程式也可以自己來定義處理的優先級——先收取、多處理某個隊列,而少處理另外一些隊列。
但是這種點對點的消息隊列,會随着叢集的增長而增加大量的隊列,這對于記憶體占用和運維管理都是一個複雜的事情。是以更進階的消息隊列服務,開始可以讓不同的隊列共享記憶體空間,而消息隊列的位址資訊、建立和删除,都采用自動化的手段。——這些自動化往往需要依賴上文所述的“目錄服務”,來登記隊列的ID對應的實體IP和端口等資訊。比如很多開發者使用ZooKeeper來充當消息隊列服務的中央節點;而類似Jgropus這類軟體,則自己維護一個叢集狀态來存放各節點今昔。

另外一種消息隊列,則類似一個公共的郵箱。一個消息隊列服務就是一個程序,任何使用者都可以投遞或收取這個程序中的消息。這樣對于消息隊列的使用更簡便,運維管理也比較友善。不過這種用法下,任何一個消息從發出到處理,最少進過兩次程序間通信,其延遲是相對比較高的。并且由于沒有預定的投遞、收取限制,是以也比較容易出BUG。
不管使用那種消息隊列服務,在一個分布式伺服器端系統中,程序間通訊都是必須要解決的問題,是以作為伺服器端程式員,在編寫分布式系統代碼的時候,使用的最多的就是基于消息隊列驅動的代碼,這也直接導緻了EJB3.0把“消息驅動的Bean”加入到規範之中。
在分布式的系統中,事務是最難解決的技術問題之一。由于一個處理可能分布在不同的處理程序上,任何一個程序都可能出現故障,而這個故障問題則需要導緻一次復原。這種復原大部分又涉及多個其他的程序。這是一個擴散性的多程序通訊問題。要在分布式系統上解決事務問題,必須具備兩個核心工具:一個是穩定的狀态存儲系統;另外一個是友善可靠的廣播系統。
事務中任何一步的狀态,都必須在整個叢集中可見,并且還要有容災的能力。這個需求,一般還是由叢集的“目錄服務”來承擔。如果我們的目錄服務足夠健壯,那麼我們可以把每步事務的處理狀态,都同步寫到目錄服務上去。ZooKeeper再次在這個地方能發揮重要的作用。
如果事務發生了中斷,需要復原,那麼這個過程會涉及到多個已經執行過的步驟。也許這個復原隻需要在入口處復原即可(加入那裡有儲存復原所需的資料),也可能需要在各個處理節點上復原。如果是後者,那麼就需要叢集中出現異常的節點,向其他所有相關的節點廣播一個“復原!事務ID是XXXX”這樣的消息。這個廣播的底層一般會由消息隊列服務來承載,而類似Jgroups這樣的軟體,直接提供了廣播服務。
雖然現在我們在讨論事務系統,但實際上分布式系統經常所需的“分布式鎖”功能,也是這個系統可以同時完成的。所謂的“分布式鎖”,也就是一種能讓各個節點先檢查後執行的限制條件。如果我們有高效而單子操作的目錄服務,那麼這個鎖狀态實際上就是一種“單步事務”的狀态記錄,而復原操作則預設是“暫停操作,稍後再試”。這種“鎖”的方式,比事務的處理更簡單,是以可靠性更高,是以現在越來越多的開發人員,願意使用這種“鎖”服務,而不是去實作一個“事務系統”。
由于分布式系統最大的需求,是在運作時(有可能需要中斷服務)來進行服務容量的變更:擴容或者縮容。而在分布式系統中某些節點故障的時候,也需要新的節點來恢複工作。這些如果還是像老式的伺服器管理方式,通過填表、申報、進機房、裝伺服器、部署軟體……這一套做法,那效率肯定是不行。
在分布式系統的環境下,我們一般都是采用“池”的方式來管理服務。我們預先會申請一批機器,然後在某些機器上運作服務軟體,另外一些則作為備份。顯然我們這一批伺服器不可能隻為某一個業務服務,而是會提供多個不同的業務承載。那些備份的伺服器,則會成為多個業務的通用備份“池”。随着業務需求的變化,一些伺服器可能“退出”A服務而“加入”B服務。
這種頻繁的服務變化,依賴高度自動的軟體部署工具。我們的運維人員,應該掌握這開發人員提供的部署工具,而不是厚厚的手冊,來進行這類運維操作。一些比較有經驗的開發團隊,會統一所有的業務底層架構,以期大部分的部署、配置工具,都能用一套通用的系統來進行管理。而開源界,也有類似的嘗試,最廣為人知的莫過于RPM安裝包格式,然而RPM的打包方式還是太複雜,不太符合伺服器端程式的部署需求。是以後來又出現了Chef為代表的,可程式設計的通用部署系統。
在虛拟機技術出現之後,PaaS平台為自動部署提供了強大的支援:如果我們是按某個PaaS平台的規範來編寫的應用,可以完全把程式丢給平台去部署,其承載量計算、部署規劃,都自動完成了。這方面的佼佼者是Google的AppEngine:我們可以直接用Eclipse開發一個本地的Web應用,然後上傳到AppEngine裡面,所有的部署就完成了!AppEngine會自動的根據對這個Web應用的通路量,來進行擴容、縮容、故障恢複。
然而,真正有革命性的工具,是Docker的出現。雖然虛拟機、沙箱技術早就不是什麼新技術,但是真正使用這些技術來作為部署工具的時間卻不長。Linux高效的輕量級容器技術,提供了部署上巨大的便利性——我們可以在各種庫、各種協作軟體的環境下打包我們的應用程式,然後随意的部署在任何一個Linux系統上。
為了管理大量的分布式伺服器端程序,我們确實需要花很多功夫,其優化其部署管理的工作。統一伺服器端程序的運作規範,是實作自動化部署管理的基本條件。我們可以根據“作業系統”作為規範,采用Docker技術;也可以根據“Web應用”作為規範,采用某些PaaS平台技術;或者自己定義一些更具體的規範,自己開發完整的分布式計算平台。
伺服器端的日志,一直是一個既重要又容易被忽視的問題。很多團隊在剛開始的時候,僅僅把日志視為開發調試、排除BUG的輔助工具。但是很快會發現,在服務營運起來之後,日志幾乎是伺服器端系統,在運作時可以用來了解程式情況的唯一有效手段。
盡管我們有各種profile工具,但是這些工具大部分都不适合在正式營運的服務上開啟,因為會嚴重降低其運作性能。是以我們更多的時候需要根據日志來分析。盡管日志從本質上,就是一行行的文本資訊,但是由于其具有很大的靈活性,是以會很受開發和運維人員的重視。
日志本身從概念上,是一個很模糊的東西。你可以随便打開一個檔案,然後寫入一些資訊。但是現代的伺服器系統,一般都會對日志做一些标準化的需求規範:日志必須是一行一行的,這樣比較友善日後的統計分析;每行日志文本,都應該有一些統一的頭部,比如日期時間就是基本的需求;日志的輸出應該是分等級的,比如fatal/error/warning/info/debug/trace等等,程式可以在運作時調整輸出的等級,以便可以節省日志列印的消耗;日志的頭部一般還需要一些類似使用者ID或者IP位址之類的頭資訊,用于快速查找定位過濾某一批日志記錄,或者有一些其他的用于過濾縮小日志檢視範圍的字段,這叫做染色功能;日志檔案還需要有“復原”功能,也就是保持固定大小的多個檔案,避免長期運作後,把硬碟寫滿。
由于有上述的各種需求,是以開源界提供了很多遊戲的日志元件庫,比如大名鼎鼎的log4j,以及成員衆多的log4X家族庫,這些都是應用廣泛而飽受好評的工具。
不過對比日志的列印功能,日志的搜集和統計功能卻往往比較容易被忽視。作為分布式系統的程式員,肯定是希望能從一個集中節點,能搜集統計到整個叢集日志情況。而有一些日志的統計結果,甚至希望能在很短時間内反複擷取,用來監控整個叢集的健康情況。要做到這一點,就必須有一個分布式的檔案系統,用來存放源源不斷到達的日志(這些日志往往通過UDP協定發送過來)。而在這個檔案系統上,則需要有一個類似Map Reduce架構的統計系統,這樣才能對海量的日志資訊,進行快速的統計以及報警。有一些開發者會直接使用Hadoop系統,有一些則用Kafka來作為日志存儲系統,上面再搭建自己的統計程式。
日志服務是分布式運維的儀表盤、潛望鏡。如果沒有一個可靠的日志服務,整個系統的運作狀況可能會是失控的。是以無論你的分布式系統節點是多還是少,必須花費重要的精力和專門的開發時間,去建立一個對日志進行自動化統計分析的系統。
根據上文所述,分布式系統在業務需求的功能以為,還需要增加額外很多非功能的需求。這些非功能需求,往往都是為了一個多程序系統能穩定可靠運作而去設計和實作的。這些“額外”的工作,一般都會讓你的代碼更加複雜,如果沒有很好的工具,就會讓你的開發效率嚴重下降。
當我們在讨論伺服器端軟體分布的時候,服務程序之間的通信就難免了。然而服務程序間的通訊,并不是簡單的收發消息就能完成的。這裡還涉及了消息的路由、編碼解碼、服務狀态的讀寫等等。如果整個流程都由自己開發,那就太累人了。
是以業界很早就推出了各種分布式的伺服器端開發架構,最著名的就是“EJB”——企業JavaBean。但凡冠以“企業”的技術,往往都是分布式下所需的部分,而EJB這種技術,也是一種分布式對象調用的技術。我們如果需要讓多個程序合作完成任務,則需要把任務分解到多個“類”上,然後這些“類”的對象就會在各個程序容器中存活,進而協作提供服務。這個過程很“面向對象”。每個對象都是一個“微服務”,可以提供某些分布式的功能。
而另外一些系統,則走向學習網際網路的基本模型:HTTP。是以就有了各種的WebService架構,從開源的到商業軟體,都有各自的WebService實作。這種模型,把複雜的路由、編解碼等操作,簡化成常見的一次HTTP操作,是一種非常有效的抽象。開發人員開發和部署多個WebService到Web伺服器上,就完成了分布式系統的搭建。
不管我們是學習EJB還是WebService,實際上我們都需要簡化分布式調用的複雜程度。而分布式調用的複雜之處,就是因為需要把容災、擴容、負載均衡等功能,融合到跨程序調用裡。是以使用一套通用的代碼,來為所有的跨程序通訊(調用),統一的實作容災、擴容、負載均衡、過載保護、狀态緩存命中等等非功能性需求,能大大簡化整個分布式系統的複雜性。
一般我們的微服務架構,都會在路由階段,對整個叢集所有節點的狀态進行觀察,如哪些位址上運作了哪些服務的程序,這些服務程序的負載狀況如何,是否可用,然後對于有狀态的服務,還會使用類似一緻性哈希的算法,去盡量試圖提高緩存的命中率。當叢集中的節點狀态發生變化的時候,微服務架構下的所有節點,都能盡快的獲得這個變化的情況,從新根據目前狀态,重新規劃以後的服務路由方向,進而實作自動化的路由選擇,避開那些負載過高或者失效的節點。
有一些微服務架構,還提供了類似IDL轉換成“骨架”、“樁”代碼的工具,這樣在編寫遠端調用程式的時候,完全無需編寫那些複雜的網絡相關的代碼,所有的傳輸層、編碼層代碼都自動的編寫好了。這方面EJB、Facebook的Thrift,Google gRPC都具備這種能力。在具備代碼生成能力的架構下,我們編寫一個分布式下可用的功能子產品(可能是一個函數或者是一個類),就好像編寫一個本地的函數那樣簡單。這絕對是分布式系統下非常重要的效率提升。
在分布式系統中程式設計,你不可避免的會碰到大量的“回調”型API。因為分布式系統涉及非常多的網絡通信。任何一個業務指令,都可能被分解到多個程序,通過多次網絡通信來組合完成。由于異步非阻塞的程式設計模型大行其道,是以我們的代碼也往往動不動就要碰到“回調函數”。然而,回調這種異步程式設計模型,是一種非常不利于代碼閱讀的程式設計方法。因為你無法從頭到尾的閱讀代碼,去了解一個業務任務,是怎樣被逐漸的完成的。屬于一個業務任務的代碼,由于多次的非阻塞回調,進而被分割成很多個回調函數,在代碼的各處被串接起來。
更有甚者,我們有時候會選擇使用“觀察者模式”,我們會在一個地方注冊大量的“事件-響應函數”,然後在所有需要回調的地方,都發出一個事件。——這樣的代碼,比單純的注冊回調函數更難了解。因為事件對應的響應函數,通常在發出事件處是無法找到的。這些函數永遠都會放在另外的一些檔案裡,而且有時候這些函數還會在運作時改變。而事件名字本身,也往往是匪夷所思難以了解的,因為當你的程式需要成千上百的事件的時候,起一個容易了解名符其實的名字,幾乎是不可能的。
為了解決回調函數這種對于代碼可讀性的破壞作用,人們發明了很多不同的改進方法。其中最著名的是“協程”。我們以前常常習慣于用多線程來解決問題,是以非常熟悉以同步的方式去寫代碼。協程正是延續了我們的這一習慣,但不同于多線程的是,協程并不會“同時”運作,它隻是在需要阻塞的地方,用Yield()切換出去執行其他協程,然後當阻塞結束後,用Resume()回到剛剛切換的位置繼續往下執行。這相當于我們可以把回調函數的内容,接到Yield()調用的後面。這種編寫代碼的方法,非常類似于同步的寫法,讓代碼變得非常易讀。但是唯一的缺點是,Resume()的代碼還是需要在所謂“主線程”中運作。使用者必須自己從阻塞恢複的時候,去調用Resume()。協程另外一個缺點,是需要做棧儲存,在切換到其他協程之後,棧上的臨時變量,也都需要額外占用空間,這限制了協程代碼的寫法,讓開發者不能用太大的臨時變量。
而另外一種改善回調函數的寫法,往往叫做Future/Promise模型。這種寫法的基本思路,就是“一次性把所有回調寫到一起”。這是一個非常實用的程式設計模型,它沒有讓你去徹底幹掉回調,而是讓你可以把回調從分散各處,集中到一個地方。在同一段代碼中,你可以清晰的看到各個異步的步驟是如何串接、或者并行執行的。
最後說一下lamda模型,這種寫法流行于js語言的廣泛應用。由于在其他語言中,定一個回調函數是非常費事的:Java語言要設計一個接口然後做一個實作,簡直是五星級的費事程度;C/C++支援函數指針,算是比較簡單,但是也很容易導緻代碼看不懂;腳本語言相對好一些,也要定義個函數。而直接在調用回調的地方,寫回調函數的内容,是最友善開發,也比較利于閱讀的。更重要的,lamda一般意味着閉包,也就是說,這種回調函數的調用棧,是被分别儲存的,很多需要在異步操作中,需要建立一個類似“會話池”的狀态儲存變量,在這裡都是不需要的,而是可以自然生效的。這一點和協程有異曲同工之妙。
不管使用哪一種異步程式設計方式,其編碼的複雜度,都是一定比同步調用的代碼高的。是以我們在編寫分布式伺服器代碼的時候,一定要仔細規劃代碼結構,避免出現随意添加功能代碼,導緻代碼的可讀性被破壞的情況。不可讀的代碼,就是不可維護的代碼,而大量異步回調的伺服器端代碼,是更容易出現這種情況的。
雲服務模型:IaaS/PaaS/SaaS
在複雜的分布式系統開發和使用過程中,如何對大量伺服器和程序的運維,一直是一個貫穿其中的問題。不管是使用微服務架構、還是統一的部署工具、日志監控服務,都是因為大量的伺服器,要集中的管理,是非常不容易的。這裡背後的原因,主要是大量的硬體和網絡,把邏輯上的計算能力,切割成很多小塊。
随着計算機運算能力的提升,出現的虛拟化技術,卻能把被分割的計算單元,更智能的統一起來。其中最常見的就是IaaS技術:當我們可以用一個伺服器硬體,運作多個虛拟的伺服器作業系統的時候,我們需要維護的硬體數量就會成倍的下降。
而PaaS技術的流行,讓我們可以為某一種特定的程式設計模型,統一的進行系統運作環境的部署維護。而不需要再一台台伺服器的去裝作業系統、配置運作容器、上傳運作代碼和資料。在沒有統一的PaaS之前,安裝大量的MySQL資料庫,曾經是消耗大量時間和精力的工作。
當我們的業務模型,成熟到可以抽象為一些固定的軟體時,我們的分布式系統就會變得更加易用。我們的計算能力不再是代碼和庫,而是一個個通過網絡提供服務的雲——SaaS,這樣使用者根本來維護、部署的工作都不需要,隻要申請一個接口,填上預期的容量額度,就能直接使用了。這不僅節省了大量開發對應功能的事件,還等于把大量的運維工作,都交出去給SaaS的維護者——而他們做這樣的維護會更加專業。
在運維模型的進化上,從IaaS到PaaS到SaaS,其應用範圍也許是越來越窄,但使用的便利性卻成倍的提高。這也證明了,軟體勞動的工作,也是可以通過分工,向更專業化、更細分的方向去提高效率。