"當系統的每一部分都由最優解或相對優解組成,那麼系統最終也将是最完美的。"
這句話是在參加莫技術分享會上聽到的,這句話吸引我占在人群後面聽完了她的分享,确實受益良多。
本文也旨在描述自己在項目演變中對一處公共處理邏輯優化的過程,周期略長最近有時間整理如下。
業務系統資料傳遞過程中,會抽取一些公共的屬性和方法封裝為特定基類以便于後續開發進行繼承。
這些被抽象出來的擁有公共屬性的基類,在業務流轉過程中的指派也應當進行統一妥善的處理。
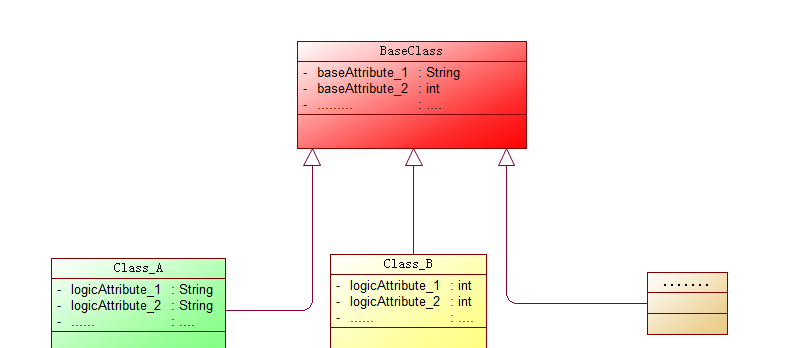
看到這裡的小夥伴們可能心中有點疑惑,在業務組織 Class_A/Class_B/...将基類中基本屬性順勢填充不就可以了嗎?
實際業務中 BaseClass 中的屬性需要根據各種不同的場景進行演變和推算,你确定将這些公共推算方式放入業務邏輯中合适嗎??
随着系統擴充繼承 BaseClass 的子類會膨脹,所有的子類都需要進行父類基本屬性指派,代碼看起來是不是有點重複?
當公共屬性推算方式發生變化,修改所有子類計算方式和修改公共方法,工作量孰重孰輕?
抽取成公共方法這點毋庸置疑的,但怎樣高效和優雅的書寫代碼呢?
本文試結合執行個體,簡述在業務流轉中對擁有公共屬性基類指派的方法以及後續持續優化。
例子将省略公共屬性的判斷推算過程,實際項目中的公共屬性和業務對象過于複雜,自己簡單抽象對象如下(關注點為公共屬性的指派)。
BaseStudentVO 為抽取公共屬性的基類,業務中使用的為 PrimaryScholar,業務開始流轉時需要将基類的公共屬性填充進去。
起初編寫函數時采用反射方式,由子類反射擷取超類并疊代超類公共方法,擷取特定 set 方法進行調用,代碼思路如下:
起初這種方式大概是最差的,需要強轉類型/随屬性增多的的判斷/疊代超類的所有的公共方法....簡直不忍直視。
後面空閑時間采用 java 内省重新編碼了函數, java 内省通俗來說是 jdk 提供給程式員一種更優雅的方式擷取 java-bean 的 getter/setter 方法。
内省和反射是兩碼事請差別對待,但毋容置疑内省是由反射實作,隻不過代碼實作由 sun 公司的 java 團隊,并經過很嚴格測試。
采用内省後比 assembleBaseAtrByReflect 反射時的代碼是不是清爽了很多,而且擯棄了很多難堪的地方,比如 強制類型轉換/随屬性增多的判斷。
當後來偶然瞥見 apache.beanutil 中幾個有意思的 API 時,我覺得是時候優化下原項目中對應函數的編碼。
代碼是不是簡單明快了很多?看起來一目了然,而且進行了精準打擊,沒有多餘疊代判斷。
如果你反編譯 BeanUtil 中的對應方法,你還是會找到 内省的影子。
最近瞅見了分層中對泛型的抽象使用,難免讓人浮想聯翩,忍不住使用泛型調整了該函數的實作。
泛型中的邊界限定很切合了該業務場景,使入參泛型 t 能順暢的使用基類中的 set 方法,徹底擺脫了反射。
反射的執行效率偏低,早已成為不争的事實,使用泛型重寫後出現了類型強轉的問題,但這已經是最優解了。
從開始的反射到後面的内省到最終的泛型,想法都是在翻看其他人的分享或撸一段實作時突然蹦出來。
本文轉自zsdnr 51CTO部落格,原文連結:http://blog.51cto.com/12942149/1949814,如需轉載請自行聯系原作者
![Java小案例——随機數猜測随機數猜測[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)