我們已經知道 dist.autograd 如何發送和接受消息,本文再來看看如何其他支撐部分,就是如何把發送接受兩個動作協調起來,如何确定每個發送/接受節點,如何确定每一個消息互動Session。
目錄
[源碼解析] PyTorch 分布式 Autograd (3) ---- 上下文相關
0x00 摘要
0x01 設計脈絡
1.1 前文回顧
1.2 總體思路
0x02 AutogradMetadata
2.1 定義
2.2 autogradMessageId
0x03 DistAutogradContainer
3.1 定義
3.2 建構
0x04 DistAutogradContext
4.1 定義
4.2 消息
4.3 建構
4.3.1 getOrCreateContext
4.3.2 newContext
4.3.2.1 Python
4.3.2.2 C++
4.4 如何共享上下文
4.4.1 發送方
4.4.2 接受方
0x05 前向傳播互動過程
5.1 發送
5.1.1 發送邏輯
5.1.2 設定上下文
5.2 接受
5.2.1 接收消息 ---> 接收方
5.2.2 處理消息
5.2.3 上下文互動
0xFF 參考
通過本文大家可以了解:AutogradMetadata 用來在不同節點間傳遞 autograd 元資訊,DistAutogradContext 代表一個分布式autograd 相關資訊,DistAutogradContainer 負責在一個worker之上存儲 DistAutogradContext。
PyTorch分布式其他文章如下:
深度學習利器之自動微分(1)
深度學習利器之自動微分(2)
[源碼解析]深度學習利器之自動微分(3) --- 示例解讀
[源碼解析]PyTorch如何實作前向傳播(1) --- 基礎類(上)
[源碼解析]PyTorch如何實作前向傳播(2) --- 基礎類(下)
[源碼解析] PyTorch如何實作前向傳播(3) --- 具體實作
[源碼解析] Pytorch 如何實作後向傳播 (1)---- 調用引擎
[源碼解析] Pytorch 如何實作後向傳播 (2)---- 引擎靜态結構
[源碼解析] Pytorch 如何實作後向傳播 (3)---- 引擎動态邏輯
[源碼解析] PyTorch 如何實作後向傳播 (4)---- 具體算法
[源碼解析] PyTorch 分布式(1)------曆史和概述
[源碼解析] PyTorch 分布式(2) ----- DataParallel(上)
[源碼解析] PyTorch 分布式(3) ----- DataParallel(下)
[源碼解析] PyTorch 分布式(4)------分布式應用基礎概念
[源碼解析] PyTorch分布式(5) ------ DistributedDataParallel 總述&如何使用
[源碼解析] PyTorch分布式(6) ---DistributedDataParallel -- 初始化&store
[源碼解析] PyTorch 分布式(7) ----- DistributedDataParallel 之程序組
[源碼解析] PyTorch 分布式(8) -------- DistributedDataParallel之論文篇
[源碼解析] PyTorch 分布式(9) ----- DistributedDataParallel 之初始化
[源碼解析] PyTorch 分布式(10)------DistributedDataParallel 之 Reducer靜态架構
[源碼解析] PyTorch 分布式(11) ----- DistributedDataParallel 之 建構Reducer和Join操作
[源碼解析] PyTorch 分布式(12) ----- DistributedDataParallel 之 前向傳播
[源碼解析] PyTorch 分布式(13) ----- DistributedDataParallel 之 反向傳播
[源碼解析] PyTorch 分布式 Autograd (1) ---- 設計
[源碼解析] PyTorch 分布式 Autograd (2) ---- RPC基礎
為了更好的說明,本文代碼會依據具體情況來進行相應精簡。
在前文之中當發送消息時候,我們在 sendMessageWithAutograd 通過 getMessageWithAutograd 來獲得了 FORWARD_AUTOGRAD_REQ 類型的消息。
而 getMessageWithAutograd 會與上下文互動,其代碼位于 torch/csrc/distributed/autograd/utils.cpp。
是以,就引出了AutogradMetadata,DistAutogradContainer 和 DistAutogradContext 等一系列基礎類,我們接下來就仔細分析一下。
我們概括一下總體思路。
先看看問題:假如一套系統包括 a,b,c 三個節點,每個節點運作一個 worker,那麼當運作一個傳播操作,我們涉及到在這三個節點之間互相傳播。是以我們需要一個機制,來在這三個節點之中唯一标示這個傳播過程,在這個傳播過程之中,也要在每一個節點之上把每一個send/recv都标示出來,這樣才能讓節點可以支援多個操作并行。
再看看解決方案:
使用上下文來唯一标示一個傳播過程。DistAutogradContext 存儲在一個worker之上的每一個分布式autograd的相關資訊,其在分布式 autograd 之中封裝前向和後向傳播,累積梯度,這避免了多個worker在彼此的梯度上互相影響。每個自動微分過程被賦予一個唯一的 autograd_context_id,在容器中,這個微分過程的上下文(DistAutogradContext) 依據這個autograd_context_id 來唯一确認。
使用autogradMessageId 來表示一對 send/recv autograd 函數。每<code>send-recv</code>對被配置設定一個全局唯一的<code>autograd_message_id</code> 以唯一地辨別該<code>send-recv</code>對。這對于在向後傳播期間查找遠端節點上的相應函數很有用。
最後,每個worker需要有一個地方來保持上下文和messageid,是以有了DistAutogradContainer這個類。每個worker擁有唯一一個單例DistAutogradContainer,其負責:
對于每一個自動微分過程存儲其分布式上下文。
一旦這個自動微分過程結束,就清除其資料。
這樣,在前向傳播期間,Pytorch 在上下文中存儲每個 autograd 傳播的<code>send</code>和<code>recv</code>函數。這確定我們在 autograd 圖中儲存對适當節點的引用以使其保持活動狀态。除此之外,這也使得在向後傳播期間很容易查找到對應的<code>send</code>和<code>recv</code>函數。
AutogradMetadata 這個類是用來在不同節點之間傳遞 autograd 的元資訊,就是把上下文等資訊封裝了一下。即,發送方通知接收方自己的上下文資訊,接收方會依據收到的這些上下文資訊作相應處理。
我們提前劇透,接收方會使用 autogradContextId 和 autogradMessageId 分别作為 上下文 和 消息 的唯一标示。從注釋之中可以知道。
autogradContextId 是全局唯一整數,用來表示一個唯一的分布式 autograd 傳播過程(包括前向傳播和後向傳播)。一個傳播過程會包括在反向傳播鍊條上的多對send/recv autograd 函數。
autogradMessageId 是全局唯一整數,用來表示一對 send/recv autograd 函數。每<code>send-recv</code>對被配置設定一個全局唯一的<code>autograd_message_id</code> 以唯一地辨別該<code>send-recv</code>對。這對于在向後傳播期間查找遠端節點上的相應函數很有用。
那麼問題來了,autogradContextId 和 autogradMessageId 分别怎麼做到全局(包括多個節點)唯一呢?
我們先概括一下:autogradMessageId 是由 rank 間接生成的,然後在内部進行遞增,是以可以保證全局唯一。
我們從後往前推導。
先看 newAutogradMessageId 是如何生成消息 id,原來是在 DistAutogradContainer 之中的成員變量 next_autograd_message_id_ 遞增得到。
然後看如何初始化 <code>next_autograd_message_id_</code>?從 DistAutogradContainer 的 init 函數中可以知道,原來是依據 worker_id 來生成 next_autograd_message_id_。work_id 是 init 函數所得到的參數。
我們再推導,看看如何設定 worker id,找到了如下,看來需要看看 python 世界的 _init 方法。
來到 python 世界,可以看到,使用了 rank 來作為參數,而 rank 是每個 worker 唯一的,這樣就保證了 worker ID 唯一,進而 消息 id 唯一。
我們把這些邏輯關系總結下來:
然後 next_autograd_message_id_ 内部遞增。
是以,AutogradMessageId 是全局唯一的。我們用圖例來看看:
為了看看 autogradContextId 為什麼可以保證唯一,我們需要先分析 DistAutogradContainer 和 DistAutogradContext。
每個worker擁有唯一一個單例DistAutogradContainer,其負責:
每個自動微分過程被賦予一個唯一的 autograd_context_id。在每個容器中,這個微分過程的上下文(DistAutogradContext) 依據這個autograd_context_id 來唯一确認。autograd_context_id 是一個 64 bit 的全局唯一id,前 16 bis 是 worker_id,後 48 位是在每個worker内部自動遞增id。是以可見,一個Container 之中,是有多個Context的。
此容器還負責維護全局唯一的消息id,用來關聯發送/接收自動微分函數對。格式類似于autograd_context_id,是一個64位整數,前16位是工作者id,後48位是worker内部自動遞增的。
因為消息 id 和 上下文 id 的前16 位是 worker_id,也就是 rank id,再加上後48位内部自增,是以可以保證 消息 id 和 上下文 id 全局唯一。
DistAutogradContainer 定義如下,其中:
worker_id_ : 本 worker 的 ID,其實就是本 worker 的 rank。
next_context_id_ :自增的上下文ID,用來給每個自動微分過程賦予一個唯一的autograd_context_id。在一個傳播鍊條上,其實隻有第一個節點的 DistAutogradContainer 用到了 next_context_id_ 來生成 Context,後續節點的 DistAutogradContainer 都是依據第一個 DistAutogradContainer 的 context id 資訊來在本地生成對應 context id 的 Context。
next_autograd_message_id_ :維護全局唯一的消息id,用來關聯 發送/接收 自動微分函數對。此變量是在本節點發送時候會使用到。
Init 方法建構了 DistAutogradContainer,主要就是利用 worker_id 對本地成員變量進行相關指派。
DistAutogradContext 存儲在一個worker之上的每一個分布式autograd的相關資訊,其在分布式 autograd 之中封裝前向和後向傳播,累積梯度,這避免了多個worker在彼此的梯度上互相影響。
由前面可知道,contextId_ 是全局唯一。
這裡僅僅給出 DistAutogradContext 成員變量,忽略其成員函數。其中成員變量最主要的有三個:
contextId_ 是上下文 id。
sendAutogradFunctions_ 是一個 map 類型變量,會收集所有發送請求對應的反向傳播算子 SendRpcBackward。
recvAutogradFunctions_ 是一個 map 類型變量,會收集所有接受送請求對應的反向傳播算子 RecvRpcBackward。
關于 SendRpcBackward 和 RecvRpcBackward,我們後續會結合引擎進行分析。
上下文主要包括幾種消息類型,比如:
我們首先看看如何建構上下文。
getOrCreateContext 函數是用來得到上下文,如果已經有,就直接擷取,如果沒有,就新建構一個。這是一個被動調用,recv 端會用到這個。
這裡是主動調用,send 端會調用這個方法。
當分布式調用時候,python世界會生成一個context。
當生成時,<code>__enter__</code> 會調用 _new_context() 在C++生成一個context。
具體通過如下映射,我們可以看到 C++ 世界之中對應的方法,調用到了 DistAutogradContainer::getInstance().newContext()。
我們來到了C++世界。每一個線程都有一個autograd_context_id。
newContext 就是生成了一個DistAutogradContext,其中通過 Container 的成員變量 next_context_id_ 的遞增來指定下一個上下文的id。
具體使用中,在<code>with</code>語句中生成的<code>context_id</code>可以用作在所有 worker 之上唯一辨別一個分布式後向傳播(包括前向傳播和後向傳播)。每個worker存儲與此 <code>context_id</code>關聯的中繼資料,這是正确執行分布式自動加載過程所必需的。
因為需要在多個 worker 之中都存儲這個 <code>context_id</code>關聯的中繼資料,是以就需要一個 封裝/發送/接受的機制來在 worker 之間傳遞這個中繼資料,封裝機制就是我們前面提到的 AutogradMetadata。我們接下來看看如何發送/接受上下文元資訊。
當發送消息時候,getMessageWithAutograd 會使用 autogradContainer.currentContext() 擷取目前上下文,進行發送。
我們之前的圖現在可以拓展,加入了上下文ID。
addSendRpcBackward 就被傳入目前上下文之中,後續反向傳播時候,會取出這個 addSendRpcBackward。
在 addRecvRpcBackward 之中,會依據傳遞過來的 autogradMetadata.autogradContextId 來建構一個上下文。
這樣,發送方和接收方就共享了一個上下文,而且這個上下文的id是全局唯一的。
具體邏輯如下,上方是發送端,下方是接收端。
發送端
利用本地 context_id 建構了 AutogradMetadata,AutogradMetadata含有 ctx_id, msg_id。
利用 AutogradMetadata 建構了 Message。
利用 agent.send 發送了 Message。
接收端:
收到了 Message。
從 Message 之中解析出 AutogradMetadata。
從 AutogradMetadata 提取出 context_id。
利用 context_id 建構了本地的 DistAutogradContext。
發送方和接收方就共享了一個上下文(這個上下文的id是全局唯一的)。
前面的分享過程還是簡略,我們接下來把完整的發送/接受過程詳細分析一下。
這裡對應設計中的如下文字:
在前向傳播期間,我們在上下文中存儲每個 autograd 傳播的<code>send</code>和<code>recv</code>函數。這確定我們在 autograd 圖中儲存對适當節點的引用以使其保持活動狀态。除此之外,這也使得在後向傳播期間很容易查找到對應的<code>send</code>和<code>recv</code>函數。
代碼邏輯如下:
生成一個 grad_fn,其類型是 SendRpcBackward。
調用 collect_next_edges 和 set_next_edges 為 SendRpcBackward 添加後續邊,這些函數我們在前面系列中有分析。
調用 add_input_metadata 添加輸入中繼資料。
調用 addSendFunction 往上下文添加 grad_fn。
我們再回憶一下DistAutogradContext 定義,這裡僅僅給出其部分成員變量。
addSendFunction 就是往 sendAutogradFunctions_ 之中添加SendRpcBackward,後續可以按照 message id 來得到這個 SendRpcBackward。
前面是從上下文建構的角度看,本次從上下文内容來看。
此時發送端邏輯如下:
我們略過 agent 的發送内部處理,轉而看看 FORWARD_AUTOGRAD_REQ 的業務流程。
生成 TensorPipeAgent 時候,把 RequestCallbackImpl 配置為回調函數。這是 agent 的統一響應函數。
前面關于代理接收邏輯時候,我們也提到了,會進入以下函數,其中可以看到有對 processForwardAutogradReq 的處理邏輯。
processForwardAutogradReq 負責具體處理消息,其處理邏輯如下:
雖然是收到了前向傳播請求,但因為此處是接收端,後續需要進行反向傳播,是以對deviceMap進行轉置。
使用 addRecvRpcBackward 将 rpc 消息 加入上下文。
可能會有nested指令的可能,是以需要再調用一次processRpc。
設定最原始的消息為處理完畢,進行相關操作。
torch/csrc/distributed/autograd/utils.cpp 之中,addRecvRpcBackward 函數會對上下文進行處理。
這裡對應設計中的:
在前向傳播期間,我們在上下文中存儲每個 autograd 傳播的<code>send</code>和<code>recv</code>函數。這確定我們在 autograd 圖中儲存對适當節點的引用以使其保持活動狀态。除此之外,這也使得在向後傳播期間很容易查找到對應的<code>send</code>和<code>recv</code>函數。
其具體邏輯是:
根據 rpc資訊中的 autogradContextId 拿到本地的上下文。
生成一個 RecvRpcBackward。
用 rpc 資訊中的張量來對 RecvRpcBackward 進行配置,包括torch::autograd::set_history(tensor, grad_fn)。
調用 addRecvFunction 把 RecvRpcBackward 加入到上下文。
addRecvFunction 的添加操作如下,就是看看 recvAutogradFunctions_之中是否已經存在這個 message id 對應的算子,如果沒有就添加 。
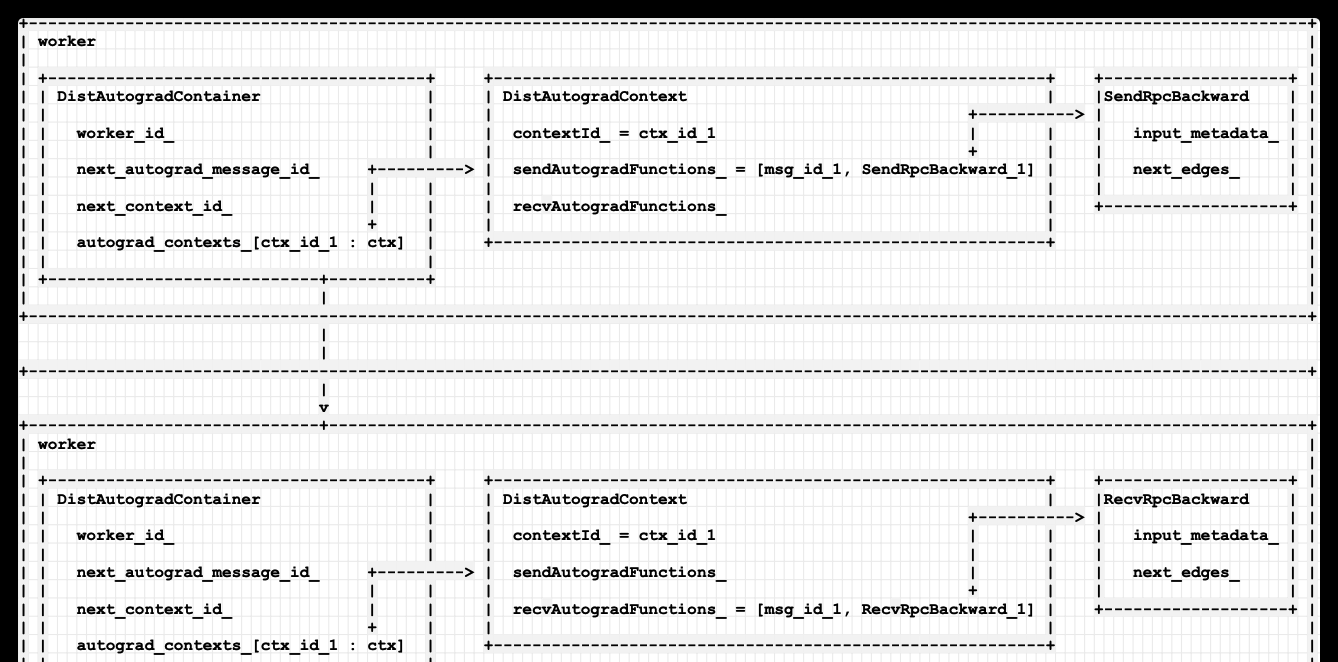
至此,邏輯拓展如下,在發送端和接收端都有一個 DistAutogradContext,其 id 都是 context_id_1。
在 每個 DistAutogradContext 之内,均以 msg_id_1 作為key,一個是 SendRpcBackward,一個建立了 RecvRpcBackward。
這就對應了設計之中提到的:
每個自動微分過程被賦予一個唯一的 autograd_context_id,在容器中,這個微分過程的上下文(DistAutogradContext) 依據這個autograd_context_id 來唯一确認。autograd_context_id 是一個 64 bit 的全局唯一id,前 16 bis 是 worker_id,後 48 位是在每個worker内部自動遞增id。是以可見,一個Container 之中,是有多個Context的。
我們加入 Container,再拓展一下目前邏輯如下:
每個worker 包括一個DistAutogradContainer。
每個 DistAutogradContainer 包括若幹個 DistAutogradContext,依據 context id 提取 DistAutogradContext。
每個 DistAutogradContext 包括 sendAutogradFunctions_ 和 recvAutogradFunctions_,利用 msg id 來擷取 SendRpcBackward 或者 RecvRpcBackward。
這樣這個反向傳播鍊條就建構了出來。
手機如下:
至此,我們初步分析了上下文相關的類,下文我們把目前已經分析的内容結合起來,系統看看業務邏輯。