上文已經分析了如何啟動/接受反向傳播,如何進入分布式autograd 引擎,本文和下文就看看如何分布式引擎如何運作。通過本文的學習,讀者可以對 dist.autograd 引擎基本靜态架構和總體執行邏輯有所了解。
目錄
[源碼解析] PyTorch 分布式 Autograd (5) ---- 引擎(上)
0x00 摘要
0x01 支撐系統
1.1 引擎入口
1.2 SendRpcBackward
1.2.1 剖析
1.2.2 定義
1.2.3 建構
1.2.4 grads_
0x02 定義
2.1 定義
2.2 單例
2.3 重要注釋
2.3.1 成員變量
2.3.2 建構
2.3.3 GPU to CPU continuations
2.3.4 析構
2.3.5 插入隊列
2.3.6 工作線程
0x03 總體執行
0x04 驗證節點和邊
4.1 gradient_edge
4.2 validate_outputs
4.3 VS 普通 engine
0x05 計算依賴
5.1 總體過程
5.2 第一部分 準備工作
5.2.1 實作
5.2.2 相關
5.2.2.1 sendFunctions
5.2.2.2 outstanding_tasks_
GraphTask
vania engine
dist engine
5.3 第二部分 計算依賴
5.3.1 實作
5.3.2 葉子節點的種類
5.4 第三部分 得到Functions
5.4.1 算法
5.4.2 實作
5.5 小結
0xFF 參考
PyTorch分布式其他文章如下:
深度學習利器之自動微分(1)
深度學習利器之自動微分(2)
[源碼解析]深度學習利器之自動微分(3) --- 示例解讀
[源碼解析]PyTorch如何實作前向傳播(1) --- 基礎類(上)
[源碼解析]PyTorch如何實作前向傳播(2) --- 基礎類(下)
[源碼解析] PyTorch如何實作前向傳播(3) --- 具體實作
[源碼解析] Pytorch 如何實作後向傳播 (1)---- 調用引擎
[源碼解析] Pytorch 如何實作後向傳播 (2)---- 引擎靜态結構
[源碼解析] Pytorch 如何實作後向傳播 (3)---- 引擎動态邏輯
[源碼解析] PyTorch 如何實作後向傳播 (4)---- 具體算法
[源碼解析] PyTorch 分布式(1)------曆史和概述
[源碼解析] PyTorch 分布式(2) ----- DataParallel(上)
[源碼解析] PyTorch 分布式(3) ----- DataParallel(下)
[源碼解析] PyTorch 分布式(4)------分布式應用基礎概念
[源碼解析] PyTorch分布式(5) ------ DistributedDataParallel 總述&如何使用
[源碼解析] PyTorch分布式(6) ---DistributedDataParallel -- 初始化&store
[源碼解析] PyTorch 分布式(7) ----- DistributedDataParallel 之程序組
[源碼解析] PyTorch 分布式(8) -------- DistributedDataParallel之論文篇
[源碼解析] PyTorch 分布式(9) ----- DistributedDataParallel 之初始化
[源碼解析] PyTorch 分布式(10)------DistributedDataParallel 之 Reducer靜态架構
[源碼解析] PyTorch 分布式(11) ----- DistributedDataParallel 之 建構Reducer和Join操作
[源碼解析] PyTorch 分布式(12) ----- DistributedDataParallel 之 前向傳播
[源碼解析] PyTorch 分布式(13) ----- DistributedDataParallel 之 反向傳播
[源碼解析] PyTorch 分布式 Autograd (1) ---- 設計
[源碼解析] PyTorch 分布式 Autograd (2) ---- RPC基礎
[源碼解析] PyTorch 分布式 Autograd (3) ---- 上下文相關
[源碼解析] PyTorch 分布式 Autograd (4) ---- 如何切入引擎
為了更好的說明,本文代碼會依據具體情況來進行相應精簡。
我們首先看看一些引擎内部支撐系統。
引擎入口在 backward 函數中有調用,從 DistEngine::getInstance().execute 進入到引擎,由前文可知,這裡是主動調用引擎。
被動調用引擎是從 SendRpcBackward 開始的。SendRpcBackward 是前向傳播之中發送行為對應的反向傳播算子。DistAutogradContext 存儲在一個worker之上的每一個分布式autograd的相關資訊,其在分布式 autograd 之中封裝前向和後向傳播,累積梯度,這避免了多個worker在彼此的梯度上互相影響。在上下文 DistAutogradContext 之中有個成員變量,記錄了本 worker 所有發送行為對應的反向傳播算子。
sendAutogradFunctions_ 中的内容都是SendRpcBackward。
SendRpcBackward 作為分布式autograd實作的一部分,每當我們将RPC從一個節點發送到另一個節點時,我們都會向autograd圖添加一個"SendRpcBackward"autograd function。這是一個占位符函數,用于在向後傳播時啟動目前worker的autograd引擎。此autograd function的邊是RPC方法的輸入。
在向後傳播過程中,此函數将在autograd引擎中排隊等待執行,該引擎最終将運作autograd圖的其餘部分。
SendRpcBackward實際上是本地節點上autograd圖的根。我們給出之前的示意圖如下:
SendRpcBackward不會接收任何 "輸入",而是RPC架構将梯度傳遞給該函數以啟動局部autograd計算。
SendRpcBackward的input邊是RPC方法的輸入,就是梯度。
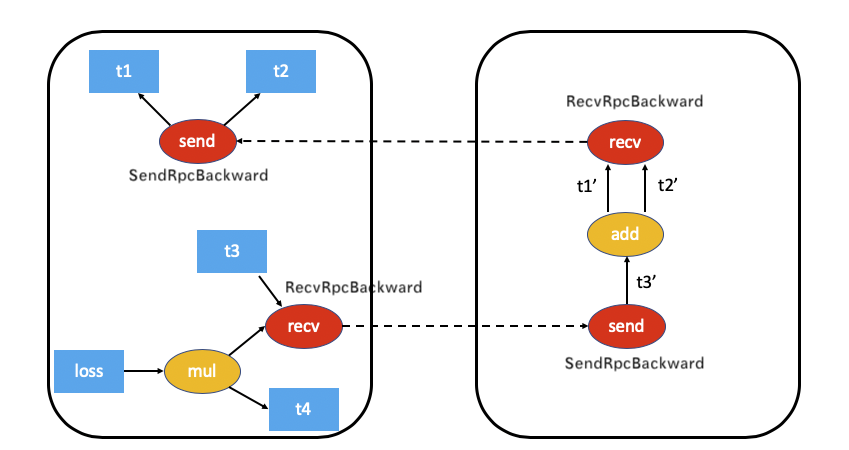
SendRpcBackward 是 Node 的派生類,因為是 Node,是以有 next_edges,可以看到其新增成員變量是 grads_。
在前向傳播過程之中,addSendRpcBackward 會建構一個SendRpcBackward,會把其前向傳播輸入邊作為反向傳播的輸出邊設定在 SendRpcBackward 之中。
之前看到,SendRpcBackward新增成員變量是 <code>grads_</code>,我們看看 <code>grads_</code> 如何設定和使用?
SendRpcBackward 提供了 set, get 操作。
何時會使用?在 torch/csrc/distributed/rpc/request_callback_no_python.cpp 之中有 processBackwardAutogradReq。processBackwardAutogradReq 會:
使用 sendFunction->setGrads(gradientsCall.getGrads()) 來設定遠端傳遞來的梯度。
調用 DistEngine::getInstance().executeSendFunctionAsync 來執行引擎開始本地後向計算。
對應了設計中如下文字,也就是被動進入引擎的起點:
SendRpcBackward實際上是本地節點上autograd圖的根。是以,它不會接收任何"輸入",而是RPC架構将梯度傳遞給該函數以啟動局部autograd計算。
具體代碼如下:
executeSendFunctionAsync 就會用 sendFunction->getGrads() 提取梯度,進行操作。
具體如下圖:

DistEngine 的定義如下,為了更好講解,下面删除了部分代碼:
引擎使用了單例模式,這樣每個 worker 之中就隻有一個單例在運作。
PyTorch 源碼之中有大量詳盡的注釋,我們挑選一些來看看。
代碼中定義了兩個 CPU 全局相關成員變量,具體如下,均注明需要看 [GPU to CPU continuations] 這個注釋。
這兩個成員變量具體初始化位置是在建構函數之中。
以下是 GPU to CPU continuations 的翻譯和了解。
Continuations 最初應該是在schema語言裡面接觸過的,後來也看過不少語言用到,這個概念沒有找到一個很好的延續概念,暫時使用"延續"這個翻譯。
為了執行GPU任務的延續(continuations),是以需要初始化一個單獨的CPU線程來處理。分布式引擎的多線程結構僅适用于CPU任務。如果我們有CPU->GPU->CPU這樣的任務順序,分布式 autograd 就沒有線程來執行最後一個CPU任務。為了解決這個問題,我們引入了一個全局CPU線程來處理這種情況,它将負責執行這些CPU任務。
CPU線程有自己的就緒隊列(ready_queue),它用作DistEngine的所有GraphTask的CPU就緒隊列(cpu_ready_queue)。這確定所有GPU到CPU的延續(continuations)都在此線程上排隊。全局CPU線程隻需将任務從全局隊列中取出,并在JIT線程上調用"execute_graph_task_until_ready_queue_empty",以執行相應的任務。
析構函數之中有如下,就是為了引擎結束而做對這兩個成員變量做了相關操作。
在哪裡往 global_cpu_ready_queue_ 插入?在 DistEngine::computeDependencies 裡面會有插入。首先,每個 GraphTask 都把 global_cpu_ready_queue_ 設定為 cpu_ready_queue。GraphTask構造函數這裡參數在調用時候傳入的是 global_cpu_ready_queue_。
是以,如果 GraphTask 最後傳回需要 CPU 運作時候,就統一用這個。
globalCpuThread 是工作線程,其就是從 ready queue 裡面彈出 NodeTask,然後執行。
總體執行是在 DistEngine::execute 之中完成,具體分為如下步驟:
使用 contextId 得到前向的上下文。
使用 validateRootsAndRetrieveEdges 進行驗證。
構造一個GraphRoot,用它來驅動後向傳播,可以認為是一個虛拟根。
使用 computeDependencies 計算依賴。
使用 runEngineAndAccumulateGradients 進行反向傳播計算。
使用 clearAndWaitForOutstandingRpcsAsync 等待 RPC 完成。
可以看到,與普通引擎相比較,分布式多了一個計算root邊和生成邊上梯度資訊的過程。因為在普通前向傳播過程之中,這些是已經配置好的,但是在分布式計算之中,前向傳播是沒有計算這些,是以需要在反向傳播之前計算出來。
我們接下來看看如何做驗證工作。
validateRootsAndRetrieveEdges 被用來驗證節點和邊的有效性,具體邏輯是:
驗證根節點的有效性,擷取根節點的邊。
看看根節點是否為空。
根節點是否需要計算梯度。
根節點是否有梯度函數。
計算梯度的邊,生成相應的梯度。
調用 validate_outputs 來驗證輸出。
gradient_edge 在本文下面會用到,就是利用一個Variable的梯度和前向傳播的輸出來建構一個Edge。
其定義在 torch/csrc/autograd/engine.cpp,原生引擎和分布式引擎都會調用。validate_outputs 之中包含了大量的驗證代碼。
如果梯度數量與邊數目不同,則退出。
周遊梯度,對于每個梯度:
擷取對應的邊,如果邊無效,則去下一個梯度。
使用input_metadata 擷取輸入資訊。
如果梯度沒有定義,也去下一個梯度。
如果梯度尺寸與輸入形狀不同,則退出。
對梯度的裝置,中繼資料的裝置進行一系列判斷。
我們和普通引擎進行對比一下校驗部分。
普通Engine 之中隻調用了 validate_outputs。
是以,對于校驗部分,DistEngine 可以總結為:
做校驗。
根據 roots 來計算root對應的邊和生成對應梯度。
再用validate_outputs驗證輸出。
我們回憶一下設計文檔中的 FAST模式算法。該算法的關鍵假設是:當我們運作反向傳播時,每個<code>send</code>函數的依賴為 1。換句話說,我們假設我們會從另一個節點通過 RPC 接收梯度。算法如下:
我們從具有反向傳播根的worker開始(所有根都必須是本地的)。
查找目前Distributed Autograd Context 的所有<code>send</code>函數 。
從提供的根和我們檢索到的所有<code>send</code>函數開始,我們在本地計算依賴項 。
計算依賴項後,使用提供的根來啟動本地 autograd 引擎。
當 autograd 引擎執行該<code>recv</code>函數時,該<code>recv</code> 函數通過 RPC 将輸入梯度發送到适當的worker。每個<code>recv</code>函數都知道目标 worker id,因為它被記錄為前向傳播的一部分。通過<code>autograd_context_id</code>和 <code>autograd_message_id</code> 該<code>recv</code>函數被發送到遠端主機。
當遠端主機收到這個請求時,我們使用 <code>autograd_context_id</code>和<code>autograd_message_id</code>來查找适當的<code>send</code>函數。
如果這是worker第一次收到對給定 <code>autograd_context_id</code>的請求,它将按照上面的第 1-3 點所述在本地計算依賴項。
然後将在第6點接受到的<code>send</code>方法插入隊列,以便在該worker的本地 autograd 引擎上執行。
最後,我們不是在 Tensor的<code>.grad</code>之上累積梯度,而是在每個Distributed Autograd Context之上分别累積梯度 。梯度存儲在<code>Dict[Tensor, Tensor]</code>之中 ,<code>Dict[Tensor, Tensor]</code>基本上是從 Tensor 到其關聯梯度的映射,并且可以使用 get_gradients() API檢索該映射 。
本章就是對應了算法的前三項,這部分是和普通引擎最大差別之一。
計算依賴分為兩大部分,第一部分是做準備工作,第二部分是計算依賴關系,第三部分是根據依賴關系來得到需要計算哪些函數。
我們先給出總體代碼和注釋,後續會仔細分析。
因為這裡是計算本地的依賴關系,是以周遊需要從 root 和 本地的 SendRpcBackward 開始計算。我們先要先做一些準備工作:
首先生成一個GraphTask,但是不需要給 GraphTask 傳一個cpu_ready_queue,因為我們後面使用execute_graph_task_until_ready_queue_empty,在那裡會給每一個調用 建立一個獨立的ReadyQueue。
其次用 seen 來記錄已經通路過的節點。
建構一個 Node 類型的 queue,把根節點插入到queue。
然後從上下文之中拿到出邊Functions,放入到 sendFunctions 之中。
sendFunctions就是出邊,之前在 addSendFunction之中被添加。
普通狀态下,root節點内在反向傳播時候,已經有了next edges,但是分布式模式下,出邊是在sendFunctions之中。
周遊出邊 sendFunctions,建構出邊清單,對于 sendFunctions 中的每一項:
GraphTask 出邊數目增加 graphTask->outstanding_tasks_++。
在 queue 之中插入 sendFunctions 中的 SendRpcBackward。
最後,queue 裡面是 root 和 若幹 SendRpcBackward。
實作之中,使用了部分函數或者成員變量,我們選取重點進行介紹。
sendFunctions 是擷取了上下文的sendAutogradFunctions_,這是一個 std::unordered_map<int64_t, std::shared_ptr>。
sendFunctions就是出邊,之前在 addSendFunction之中被添加,addSendRpcBackward 會調用 addSendFunction。
利用 graphTask->outstanding_tasks_++ 把GraphTask 出邊數目增加。
outstanding_tasks_ 是 GraphTask 的成員變量。
outstanding_tasks_ :用來記錄目前任務數目,如果數目為0,則說明任務結束了。 如果這個數量不為0,則此GraphTask依然需要運作。
在 vania engine 之中就有 outstanding_tasks_。
是待處理 NodeTask的數量,用來判斷該GrapTask是否還需要執行,如果數目為0,則說明任務結束了。
當 GraphTask 被建立出來時候,此數值為0。
如果有一個NodeTask被送入到 ReadyQueue,則outstanding_tasks_ 增加 1。
如果在工作線程作執行一次 evaluate_function(task)後,outstanding_tasks的值減1。
如果這個數量不為0,則此GraphTask依然需要運作。
NodeTask任務增加時候 outstanding_tasks_ 就加一。
在計算依賴時候,周遊 sendFunctions,上下文有幾個SendRpcBackward,就把 outstanding_tasks_ 就加幾,每多一條出邊,就意味着多了一個計算過程。
而執行時候,void DistEngine::execute_graph_task_until_ready_queue_empty 和 Engine::thread_main 都會減少 outstanding_tasks_。
第二部分是周遊圖,計算依賴關系。
此時 queue 裡面是 root 和 若幹 SendRpcBackward,是以接下來就是從 queue 之中不停彈出Node 進行計算。具體邏輯是:
周遊所有發送邊(從 queue 之中不停彈出Node ),對于每個Node,周遊Node(根節點或者SendRpcBackward)的next_edges:
如果可以得到一個邊,則:
對應的節點依賴度加一。
如果之前沒有通路過,就插入到queue。
如果這個邊本身沒有輸出邊,說明是葉子節點,葉子節點有兩種:AccumulateGrad 或者 RecvRpcBackward。
對于 recvBackwardEdges.emplace_back(edge) 做特殊處理。
插入到最終輸出邊 outputEdges,注意,RecvRpcBackward 也插入到這裡。
這之後,局部變量 recvBackwardEdges 裡面是RecvRpcBackward,outputEdges 裡面是 AccumulateGrad 和 RecvRpcBackward。
有兩種葉子節點,是以需要分開處理。
AccumulateGrad : 普通葉子節點,就是本地葉子節點。
RecvRpcBackward : 在正向圖中,是RPC接收節點。
從設計文檔之中,有如下對應:"
我們發現了一個葉節點,它應該是AccumulateGrad或RecvRpcBackward。我們記錄函數以確定我們不執行它,而是在autograd上下文中累積梯度。這些函數将作為"輸出"參數傳入到vanilla autograd引擎。 我們沒有在RecvRpcBackward上下文積累任何梯度。RecvRpcBackward被添加為輸出邊,以訓示它是葉節點,這有助于正确計算本地autograd graph的依賴關系。将RecvRpcBackward放在"outputEdges"中意味着需要執行此函數(與我們對快速模式的假設一緻,即所有send/recv函數在向後傳播中都有效),是以也需要執行其所有祖先函數。
比如,對于 work 1, recv 就是葉子節點,是一個RecvRpcBackward,它需要把梯度傳遞給 worker 0。對于 worker 0,上面的子圖,t1, t2 也是葉子節點,都是AccumulateGrad。
這部分根據依賴關系找到需要計算那些functions。
現在讓我們計算需要執行哪些函數。算法如下:
建立一個虛拟GraphRoot,它指向此上下文和原始GraphRoot的所有"發送"函數。使用outputEdges和虛拟GraphRoot來運作"init_to_execute"。這確定我們根據需要标記适當的函數:如果它們隻能從本地特定的"發送"函數通路,而不需要從提供的根通路。
對于"outputEdges"中指向"RecvRpcBackward"的所有邊,根據執行需要标記這些函數。原因是"init_to_execute"會将這些标記為不需要。但"RecvRpcBackward"的獨特之處在于,我們将其用作圖中的葉節點來準确計算所需的執行操作,但與AccumageGrad不同,我們确實需要執行此函數。
具體就是:
RecvRpcBackward 需要執行。
AccumulateGrad 需要累積梯度。
此時,recvBackwardEdges 裡面是RecvRpcBackward,outputEdges 裡面是 AccumulateGrad 和 RecvRpcBackward。我們需要根據這些資訊來辨別後續如何執行。具體實作是:
先計算 AccumulateGrad,如果 outputEdges 不為空,則把 outputEdges 的資訊插入到 GraphTask.exec_info_ 之中:
建構一個 edge_list edges,就是出邊清單。
周遊 sendFunctions,得到輸出清單,加入到 edges。
root也加入出邊清單。
建立一個虛拟Root。
如果出邊不為空,則會調用 init_to_execute 對GraphTask進行初始化。
周遊 GraphTask 的 exec_info,exec_info_ 的資料結構是std::unordered_map<Node*, ExecInfo> 。
看看此張量是否在所求梯度的張量路徑上。
如果不在路徑之上,就跳到下一個張量。
拿到 exec_info_ 的 Node。
如果 Node 是葉子節點。
周遊張量路徑上的節點。
給張量插入Hook。這裡是關鍵,就是 AccumulateGrad 對應的張量加上了 Hook,用來後續累積梯度。
周遊 recvBackwardEdges,對于每個 recvBackward,在 GraphTask.exec_info_ 之中對應項之上設止為 "需要執行"。
至此,依賴項處理完畢,所有需要計算的函數資訊都位于 GraphTask.exec_info_ 之上,我們在下一篇來看看如何執行。
我們總結一下計算依賴的邏輯:
computeDependencies 開始計算依賴。
從 DistAutogradContext 之中擷取 sendAutogradFunctions_,把 SendRpcBackward 都放入到 sendFunctions。普通狀态下,root節點内在反向傳播時候,已經有了next edges,但是分布式模式下,出邊是在sendFunctions之中,是以要提取出來,放入下面的 queue。
周遊 sendFunctions,把 Node 加入到 queue,此時 queue 之中是 root 和 一些 SendRpcBackward。
周遊 Queue 進行處理,處理結果是兩個局部變量 edge_list。 recvBackwardEdges 裡面是RecvRpcBackward,outputEdges 裡面是 AccumulateGrad 和 RecvRpcBackward,我們需要根據這些資訊來辨別後續如何執行。
周遊 recvBackwardEdges 和 outputEdges,把相關資訊加入到<code>GraphTask.exec_info_</code>,至此,依賴項處理完畢,所有需要計算的函數資訊都位于 GraphTask.exec_info_ 之上。
AccumulateGrad 被加入了 Hook,用來後續累積梯度。
RecvRpcBackward 被設定了需要執行。
Distributed Autograd Design
Remote Reference Protocol
PyTorch 源碼解讀之分布式訓練了解一下?
https://pytorch.org/docs/stable/distributed.html
https://pytorch.apachecn.org/docs/1.7/59.html
https://pytorch.org/docs/stable/distributed.html#module-torch.distributed
https://pytorch.org/docs/master/notes/autograd.html
https://pytorch.org/docs/master/rpc/distributed_autograd.html
https://pytorch.org/docs/master/rpc/rpc.html
https://www.w3cschool.cn/pytorch/pytorch-cdva3buf.html
PyTorch 分布式 Autograd 設計
Getting started with Distributed RPC Framework
Implementing a Parameter Server using Distributed RPC Framework
Combining Distributed DataParallel with Distributed RPC Framework
Profiling RPC-based Workloads
Implementing batch RPC processing
Distributed Pipeline Parallel