今天用遞歸寫了個抓取知乎所有使用者資訊的爬蟲,源代碼放在了github上,有興趣的同學可以上去下載下傳一下看看,這裡介紹一下代碼邏輯以及分頁分析,首先看網頁,這裡本人随便選了一個大V作為入口,然後點開他的關注清單,如圖
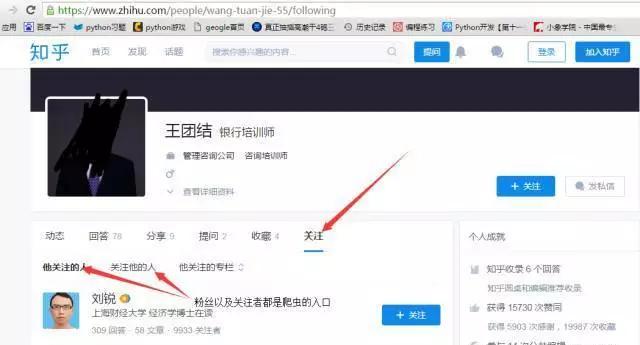
注意,本人爬蟲的全稱都是處于非登入狀态的。這裡的粉絲清單以及關注者清單都是背景ajax請求得到的資料(沒有聽過ajax的童鞋别慌,ajax請求跟普通浏覽器的請求沒有差別,它主要就是在我們 浏覽網頁時候偷偷給伺服器發送的請求,就是為了節省流量以及減少請求數,不然每次看點新資料都全部重新整理網頁,伺服器壓力很大的,是以有了這玩意),然後我們找到粉絲清單以及關注者清單的URL,這個很簡單,在chrome浏覽器下面點選一下頁數切換就可以找到,如圖

找到關注者以及粉絲的URL就好辦理,下面看一看這些資料,這裡以粉絲的資料舉例,如圖,是一段json
這裡找到了粉絲的資料,不過這裡不是使用者的詳細資訊,隻有部分資料,不過他提供了一個token_url,我們就可以擷取這個ID通路使用者的詳細資訊了,我們看看每個使用者的詳細資訊怎麼提取。這裡樓主發現,在觀看粉絲或者關注清單的時候,網頁是會自動觸發該使用者詳細資訊的請求,如圖
這次獲得的是使用者詳細資訊查詢的URL,這裡看一看這個詳細資訊的URL,如圖
上面介紹了網頁的基礎分析,下面說一下代碼的思路,這次爬蟲用到了遞歸,本次用的scrapy抓取以及mogodb資料庫存儲的。
首先本人是用了一個大V作為爬蟲第一個網頁,然後分三步,第一步是爬了該大V的詳細資訊然後存入資料庫,第二步是爬取了該大V的粉絲,第三是爬取了該大V 的關注者(其實就是爬取粉絲或者關注者的token_url),完成之後,利用爬取的粉絲以及關注者的資料構造他們每個人詳細資訊的url,然後挖取詳細 資訊存入資料庫。到這裡遞歸第一步算是完成了,然後爬蟲會從每一個粉絲和關注者入手,分别爬取他們的粉絲以及關注者的詳細資料,不斷遞歸
在代碼裡面還有加入了一些自動翻頁的功能,有興趣可以看看。下面是我們item裡面定義要抓取的資料:
代碼一共不足80行,運作了一分鐘就抓了知乎一千多個使用者的資訊,這裡上張結果圖
最近忙完别的事了,終于可以天天寫爬蟲了,不知道大家這篇有什麼問題不,可以随便向我提
最後提一提,爬取一定要僞裝好headers,裡面有些東西伺服器每次都會檢查。
原文釋出時間為:2017-04-09
本文作者:蝸牛仔