在大資料的浪潮下,時時刻刻都會産生大量的資料。比如社交媒體、部落格、電子商務等等,這些資料會以不同的類型存儲在不同的平台裡面。為了執行ETL(提取、轉換、加載)操作,需要一個消息中間件系統,該系統應該是異步和低耦合的,即來自各種存儲系統(如HDFS、Cassandra、RDBMS等)的資料可以同時轉存在一個地方,而所有這些資料源都是彼此獨立的。解決這個問題的方法之一是Kafka,它是一個開源的分布式消息處理平台。
Message:它基本上是一個鍵值對,在值部分包含有用的資料和記錄;
Topic:對于多租戶,可以建立多個主題,這隻是釋出和訂閱消息的名稱;
Partition:對于多線程任務,可以在一個Topic中,建立多個分區,提升生産者和消費者的性能;
Offset:消息以類似于送出日志的順序形式存儲,并且從0開始為每個消息提供順序ID(每個分區偏移量從0開始);
Broker:Kafka叢集由多個服務節點組成,這些服務節點隻是叢集中托管Zookeeper維護的無狀态伺服器的節點,英文這裡沒有主從概念,是以所有的Broker都是同級别的(每個Partition上會有Leader和Follower);
Consumer:用于消費Topic的應用程式;
ConsumerGroup:消費不同Topic所使用的相同GroupID;
Producer:用于生産Topic的應用程式。
Zookeeper是一個分布式叢集管理系統,它是一個為分布式應用提供一緻性服務的軟體,提供的功能包含:配置維護、域名服務、分布式服務等。它目标就是封裝好複雜易出錯的關鍵服務,将簡單易用的接口和性能高效、功能穩定的提供提供給使用者。而在Kafka中,它提供了以下功能:
控制器選舉:對于特定主題,分區中的所有讀寫操作都是通過複制副本的資料來完成的,每當Leader當機,Zookeeper就會選舉出新的Leader來提供服務;
配置Topic:與某個Topic相關的中繼資料,即某個特定Topic是否位于Broker中,有多少個Partition等存儲在Zookeeper中,并在生産消息時持續同步;
ACL:Topic的權限控制均在Zookeeper中進行維護。
Kafka的一些關鍵特性,使得它更加受到喜愛,針對傳統消息系統的不同:
高吞吐量:吞吐量表示每秒可以處理的消息數(消息速率)。由于我們可以将Topic分布到不同的Broker上,是以我們可以實作每條數以千次的讀寫操作;
分布式:分布式系統是一個被分割成多台運作的機器的系統,所有這些機器在一個叢集中協同工作,在最終使用者看來是一個單一的節點。Kafka是分布式的,因為它存儲、讀取和寫入多個節點上的資料,這些節點被稱為Broker,它與Zookeeper一起共同建立了一個稱為Kafka叢集的生态系統;
持久性:消息隊列完全儲存在磁盤上,而不是儲存在記憶體中,同一資料的多個副本(ISR)可以跨不同的節點存儲。是以,不存在由于故障轉移場景而導緻資料丢失的可能性,并使其具有持久性;
可伸縮性:任何系統都可以水準或垂直伸縮,縱向可伸縮性意味着向相同的節點添加更多的資源,如CPU、記憶體,并且會産生很高的操作成本。水準可伸縮性可以通過簡單的在叢集中添加幾個節點來實作,這增加了容量需求。Kafka水準擴充意味着當我們的容量用完時,我們可以在叢集中添加一個新的節點。
生産者首先擷取Topic中的中繼資料,以便知道需要使用消息更新哪個Broker。中繼資料也存儲在Broker中,并與Zookeeper保持連續同步。是以,若有多個生産者都希望連接配接到Zookeeper來通路中繼資料,會導緻性能降低。當生産者擷取了Topic和中繼資料資訊,它就會在Leader所在的Broker節點的日志中寫入消息,而之後Follower(ISR)會将其複制進行同步。
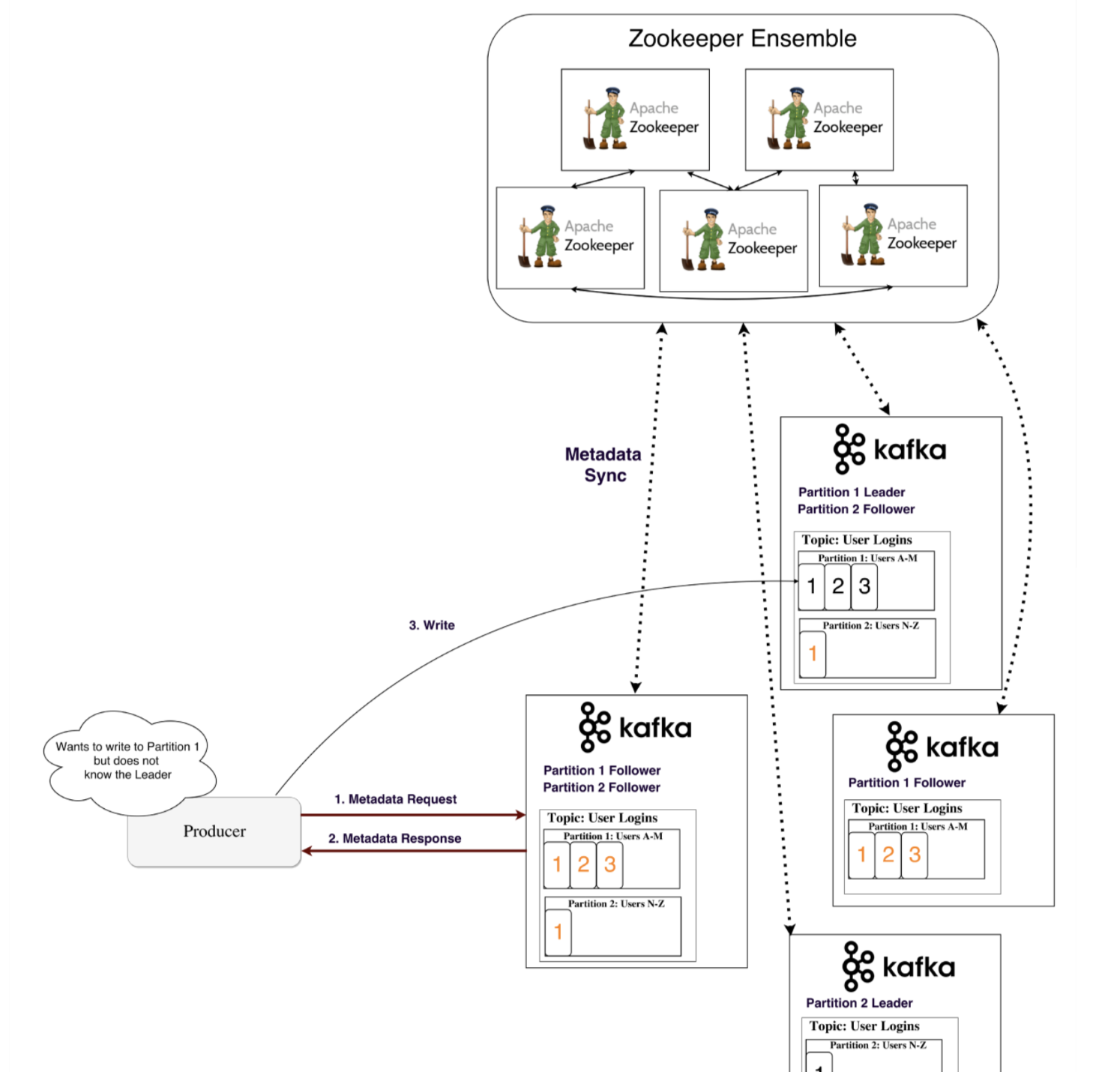
在寫入操作可以是同步的,即僅當Follower還在其日志中同步消息時,或者異步,即隻有Leader更新資訊消息,狀态發生給生産者。磁盤上的消息可以保留特定的持續時間,在此期限後,将自動清除舊消息,并且不再可供使用。預設情況下,設定為7天。可以通過三種政策将消息寫到Topic。
send(key,value,topic,partition):專門提供需要進行寫操作的分區。不建議使用該方式,因為它可能會導緻分區大小不均衡;
send(key,value,topic):在這裡,預設的HashPartitioner用于确定要寫入消息的分區,方式查找key的Hash并進行取模,該Topic的分區,也可以編寫我們自己定義的分區程式;
send(null,value,topic):在這種情況下,消息以循環方式存儲在所有分區中。
Java生産者示例代碼如下:
由于Kafka的速度非常快并且可以擷取實時消息,是以單個消費者肯定會在Topic中讀取很大一部分消息時出現延遲。為了克服這類問題,可以建立一個消費者組,該消費者組由多個具有相同GroupID的消費者組成。每個使用者都連接配接有一個唯一的分區,該分區所在所有使用者之間平均配置設定。将分區配置設定給特定使用者是消費者組協調器的責任,協調器由Broker被提名擔任該角色。為了管理活躍的消費者,消費者組中的所有成員會将它們的心跳發送到組協調器。
關于消費分區與消費線程的對應關系,理論上消費線程數應該小于等于分區數。之前是有這樣一種觀點,一個消費線程對應一個分區,當消費線程等于分區數是最大化線程的使用率。直接使用KafkaConsumer Client執行個體,這樣使用确實沒有什麼問題。但是,如果我們有富裕的CPU,其實還可以使用大于分區數的線程,來提升消費能力,這就需要我們對KafkaConsumer Client執行個體進行改造,實作消費政策預計算,利用額外的CPU開啟更多的線程,來實作消費任務分片。
在0.10.x以後的版本中,Kafka底層架構發生了變化,将消費者的資訊由Zookeeper存儲遷移到Topic(__consumer_offsets)中進行存儲。消費的偏移量Key(groupid, topic, partition)以及Value(Offset, ...)

Java消費者示例代碼如下:
由于Kafka遵循了一定的政策,這也是它設計的一部分,以使得它性能更好、更快。
沒有随機磁盤通路:它使用稱為不可變隊列的順序資料結構,其中讀寫操作始終為恒定時間O(1)。它在末尾附加消息,并從頭開始或者從特定偏移量讀取;
順序IO:現代作業系統将其大不部分可用的記憶體配置設定給磁盤緩存,并且更快的用于存儲和檢索順序資料;
零拷貝:由于根本沒有修改資料,是以将磁盤中的資料不必要的加載到應用程式記憶體中,是以,它沒有将其加載到應用程式中,而是通過Socket位元組,緩沖區以及網絡從context緩存區發送了相同的資料;
消息批處理:為了避免多次網絡互動,将多個消息分組在一起;
消息壓縮:在通過網絡傳輸消息之前,使用gzip、snappy等壓縮算法對消息進行壓縮,然後在Consumer中使用API将其解壓。
在打開Kafka伺服器之前,Broker中的所有消息都存儲在配置檔案中的配置的日志目錄中,在該目錄内,可以找到包含特定Topic分區的檔案夾,其格式topic_name-partition_number,例如topic1-0。另外,__consumer_offsets這個Topic也存儲在同一日志目錄中。
在特定Topic的分區目錄中,可以找到Kafka的Segment檔案xxx.log,索引檔案xxx.index和時間索引xxx.timeindex。當達到舊的Segment大小或者時間限制時,會在建立新的Segment檔案時将屬于該分區的所有資料寫入活躍的Segment中。索引将每個偏移量映射到其消息在日志中的位置,由于偏移量時順序的,是以将二進制搜尋應用于在特定偏移量的日志檔案中查找資料索引。
任何保持在日志頭部以内的使用者都将看到所寫的每條消息,這些消息将具有順序偏移量。可以使用Topic的min.compaction.lag.ms屬性來保證消息在被壓縮之前必須經過的最短時間。也就是說,它為每個消息在(未壓縮)頭部停留的時間提供了一個下限。可以使用Topic的max.compaction.lag.ms屬性來保證從編寫消息到消息符合壓縮條件之間的最大延時
消息始終保持順序,壓縮永遠不會重新排序消息,隻是删除一些而已
消息的偏移量永遠不會改變,它是日志中位置的永久辨別符
從日志開始的任何使用者将至少看到所有記錄的最終狀态,按記錄的順序寫入。另外,如果使用者在比Topic的log.cleaner.delete.retention.ms短的時間内到達日志的頭部,則會看到已删除記錄的所有delete标記。保留時間預設是24小時。
詳情分析可閱讀《Kafka日志壓縮剖析》。
以上就是筆者給大家簡要的彙總了Kafka的各個知識點,包含常見的術語、Consumer & Producer的使用方式、存儲流程等
另外,筆者開源的一款Kafka監控關系系統Kafka-Eagle,喜歡的同學可以Star一下,進行關注。
Kafka Eagle源代碼位址:https://github.com/smartloli/kafka-eagle
這篇部落格就和大家分享到這裡,如果大家在研究學習的過程當中有什麼問題,可以加群進行讨論或發送郵件給我,我會盡我所能為您解答,與君共勉!
另外,部落客出書了《Kafka并不難學》和《Hadoop大資料挖掘從入門到進階實戰》,喜歡的朋友或同學, 可以在公告欄那裡點選購買連結購買部落客的書進行學習,在此感謝大家的支援。關注下面公衆号,根據提示,可免費擷取書籍的教學視訊。
<b></b><b></b><b></b><b></b>
聯系方式:
Twitter:https://twitter.com/smartloli
QQ群(Hadoop - 交流社群1):424769183
QQ群(Kafka并不難學): 825943084
溫馨提示:請大家加群的時候寫上加群理由(姓名+公司/學校),友善管理者稽核,謝謝!