最近Kafka官網釋出了2.8版本,在該版本中引入了KRaft模式。鑒于新版本和新特性的引入,相關使用資料較少,那邊本篇部落格筆者将為大家介紹Kafka2.8的安裝和使用。
從Kafka2.8版本開始,可以不用Apache Zookeeper來作為Kafka的依賴元件了,官網把這種稱之為KRaft模式。目前,Kafka使用Zookeeper來存儲有關分區和Broker的中繼資料,并選擇一個Broker作為Kafka的Controller。現在官網打算删除對Zookeeper的依賴,讓Kafka能夠以更具擴充性和更加強大的方式管理中繼資料,進而支援更多分區。
我們經常會讨論将狀态作為一系列事件進行管理的好處。單個數字(偏移量)描述了Consumer在Stream中的位置。隻需要重播所有比其目前偏移量新的事件,多個Consumer就可以迅速趕上最新的狀态。該日志在事件之間建立了清晰的順序,并確定使用者始終沿着單個時間軸移動。
但是,這些好處Kafka卻沒有享受到,對中繼資料的更改視為互相之間沒有關系的孤立更改。當Controller向叢集中的其他Broker推送狀态更改通知(例如LeaderAndIsrRequest)時,Broker可能會擷取部分更改,但不是全部。盡管Controller重試了幾次,但最終還是放棄了。這樣會使Broker處理分歧狀态,更壞的是,盡管Zookeeper是記錄的存儲,但是Zookeeper中的狀态通常與Controller記憶體中儲存的狀态不比對。例如,當分區Leader在Zookeeper中更改了其ISR時,Controller通常在幾秒鐘内不了解這些更改。Controller沒有通用的方法來遵循Zookeeper事件日志。盡管Controller可以設定一次Watch,但是由于性能原因,Watch的數量受到限制。監視觸發時,它不會告訴Controller目前狀态,而隻是告訴狀态已更改。到Controller重新讀取znode并設定新的Watch時,狀态可能已經與Watch最初觸發時的狀态有所變化。如果沒有Watch,則Controller可能根本不了解該變化。
某些情況下,中繼資料應該存儲在Kafka中,而不是存儲在單獨的系統中。這将避免與Controller狀态和Zookeeper狀态之間的差異相關的所有問題。Broker不應将通知發送給Broker,而應僅使用事件日志中的中繼資料事件。這樣可以確定中繼資料更改始終以相同的順序到達。Broker将能夠在檔案中本地存儲中繼資料。當它們啟動時,它們隻需要從Controller讀取已更改的内容,而無需讀取完整狀态。這将使我們以更少的CPU消耗支援更多的分區。
Zookeeper是一個單獨的系統,具有自己的配置檔案文法,管理工具和部署模式。這意味着系統管理者需要學習如何管理和部署兩個獨立的分布式系統才能部署Kafka。對于管理者來說,這可能是一項艱巨的任務,特别是如果他們對部署Java服務不是很熟悉的話。統一該系統将大大改善運作Kafka的首次體驗,并有助于擴大其應用範圍。
由于Kafka和Zookeeper配置是分開的,是以很容易出錯。例如,管理者可能在Kafka上設定了SASL,并且錯誤的認為它們已經保護了通過網絡傳輸的所有資料。實際上,這樣做還必須在單獨的在Zookeeper系統中部署配置安全性。
KIP-500提出了可擴充的Zookeeper Kafka後的總體構想,為了展示整體情況,忽略了諸如RPC格式、磁盤格式等詳細資訊。如下圖所示:
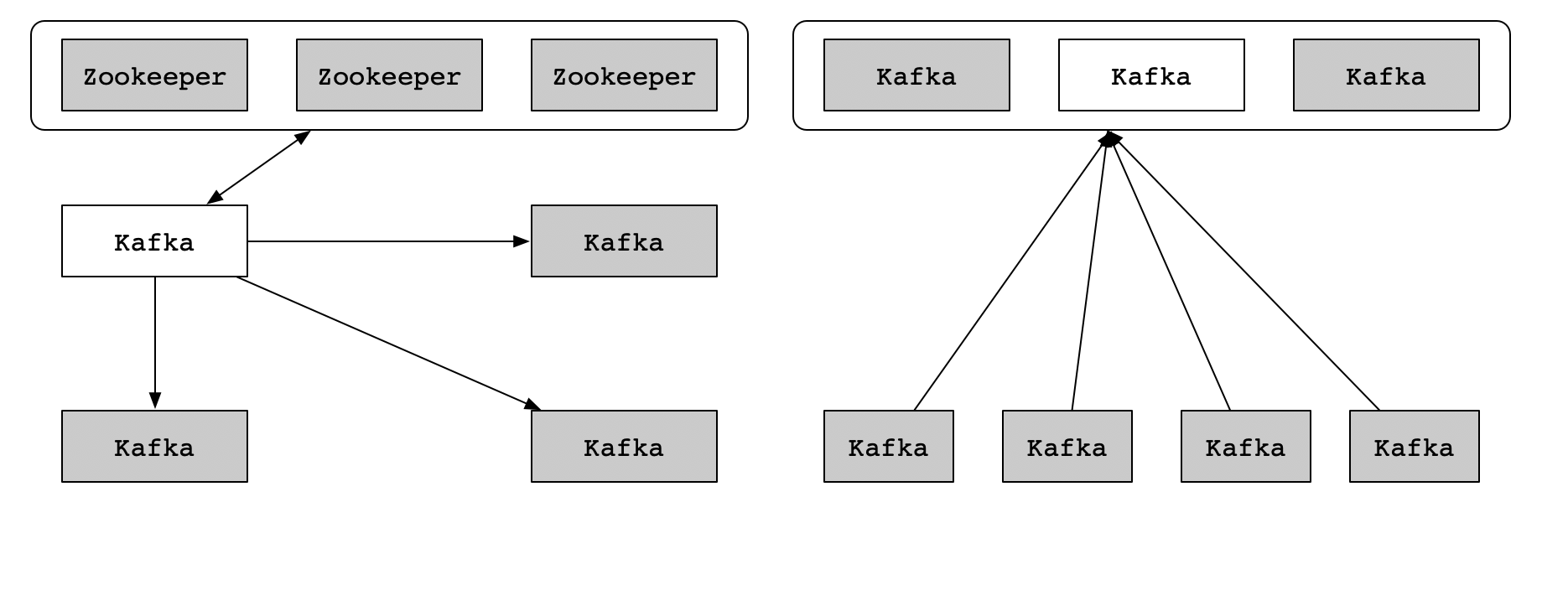
目前,Kafka叢集包含了幾個Broker節點,以及Zookeeper節點的外部選舉。在此圖中,我們描繪了4個Broker節點和3個Zookeeper節點。這是小型叢集的典型規劃。Controller(用白色表示)在標明後從Zookeeper Leader中加載其狀态。從Controller延伸到Broker中其他節點的箭頭指向表示Controller推送的更新,例如LeadAndIsr和UpdateMetaData消息。
需要注意的是,除了Controller之外的其他Broker可以并且确實與Zookeeper能夠進行通信。是以,實際上,應該從每個Broker到Zookeeper進行劃清界限。另外,外部指令行工具和應用程式可以在Zookeeper中修改狀态,而無需Controller的參與。如前所述,這些問題使得很難知道Controller上的記憶體中的狀态是否真正反映了Zookeeper中的持久狀态。
在提出的體系結構中,三個Controller節點替代了三個Zookeeper節點。Controller節點和Broker節點在單獨的JVM中運作。Controller節點為中繼資料分區選擇單個Leader,以白色表示。Broker不是從Controller向Broker釋出更新,而是從該Leader提取中繼資料更新。這就是為什麼箭頭指向Controller而不是Broker的原因。
請注意,盡管Controller程序在邏輯上與Broker程序是分開的,但是它們在實體上并不需要分開。在某些情況下,将某些或者所有Controller程序與Broker程序部署在同一節點上可能是有意義的。這類似于Zookeeper程序可以與較小規模的叢集中的Kafka Broker部署在相同的節點上。
Controller節點包括一個Raft選舉,用于管理中繼資料日志。該日志包含有關叢集中繼資料的每次更改的資訊。目前存儲在Zookeeper中的所有内容,例如Topic,分區,ISR,配置等,都将存儲在此日志中。
使用Raft算法,Controller節點将在不依賴任何外部系統的情況下從他們當中選出一個Leader。中繼資料日志的Leader稱之為Active Controller。Active Controller處理由Broker生成的所有RPC,Follower Controller複制寫入資料到Active Controller,并在Active Controller出現故障時用作熱備用伺服器(HA)。由于Controller現在都将跟蹤最新狀态,是以Controller故障轉移将不需要很長的重新加載時間,在此期間我們将所有狀态都轉移到新的Controller。
就像Zookeeper一樣,Raft需要大多數節點才能繼續運作。是以,三個節點Controller叢集可以承受一次故障。五個節點Controller叢集可以承受兩次故障,依此類推。Controller定期将中繼資料的快照寫到磁盤上,盡管從概念上講這與壓縮類似,但是代碼路徑會有所不同,因為我們可以簡單的從記憶體中讀取狀态,而不是從磁盤中重新讀取日志。
這些Broker将通過新的MetadataFetch API從Active Controller中擷取更新,而不是Controller将更新推送給其他Broker。MetadataFetch與fetch請求類似,就像fetch請求一樣,Broker将跟蹤其擷取的最後更新的偏移量(offset),并且僅從Active Controller中請求更新。
Broker将把提取到磁盤的中繼資料持久化。即使存在成千上萬甚至數百萬個分區,這也可以使Broker快速啟動。(請注意,由于這種持久性是一種優化,是以如果使開發更容易,可以将其儲存在第一個版本之外)。
在大多數情況下,Broker隻需要擷取增量,而無需擷取完整狀态。但是,如果Broker與Active Controller的距離太遠(落後Active Controller太遠),或者Broker完全沒有緩存的中繼資料,則Controller将發送完整的中繼資料鏡像,而不是一系列增量。

Broker将定期向Active Controller請求中繼資料更新,該請求作為心跳,讓Controller知道Broker處理活躍狀态。
目前,Broker在啟動後立即向Zookeeper注冊,該注冊完整了兩件事:它使Broker知道了它是否已經被選舉為Controller,并且它使其他節點知道如何聯系它。
目前,如果Broker丢失了其Zookeeper會話,則Controller會将其從叢集中繼資料中删除。在以後Zookeeper時代,如果Active Controller在足夠長的時間内未發送MetadataFetch心跳,則Active Controller将從叢集中繼資料中删除Broker。
在目前情況下,可以聯系Zookeeper從Controller進行分區的Broker将繼續滿足使用者的請求,但是不會接收任何中繼資料更新。這可能會導緻一些令人困惑和困難的情況。例如,使用acks=1的生産者可能會繼續生産實際上不再是該Leader的Leader,但是無法接收到Controller的LeaderAndIsrRequest來遷移Leader。
在以後Zookeeper的世界中,叢集成員身份與中繼資料更新內建在一起,如果Broker無法接收中繼資料更新,則他們将無法繼續成為叢集的成員。盡管仍然可以從特定Client對Broker進行分區,但是如果從Controller進行了分區,則Broker将從叢集中删除。
Offline:當Broker程序處理脫機狀态時,它要麼根本不運作,要麼不執行啟動所需要的單節點任務,例如初始化JVM或執行日志恢複;
Fenced:當Broker處理Fenced狀态時,它将不會響應來自Client的RPC。當啟動并嘗試擷取最新的中繼資料時,Broker将處理受保護狀态。如果無法聯系Active Controller,它将重新進入隔離狀态。發送給Client的中繼資料中應省略受保護的Broker;
Online:當Broker線上時,它準備響應Client的請求;
Stopping:Broker收到SIGINT時便進入停止狀态,這表明系統管理者要關閉Broker。當Broker停止時,它仍在運作,但是我們正在嘗試将分區Leader移除該Broker。最終,Active Controller将通過MetadataFetchResponse中傳回特殊的結果代碼來要求Broker最終脫機。或者,如果Leader不能在預定時間内移動,則Broker将關閉。
另外,以前直接寫給Zookeeper的需要操作将變為Controller操作。例如,更改配置,更改預設授權者存儲的ACL等。Client的新版本應将這些操作直接發送到Active Controller,它将與新舊叢集一起使用。為了保持與将這些操作發送給随機Broker的舊Client的相容性,Broker會将這些請求轉發到Active Controller。
在某些情況下,需要建立一個新的API來替換以前通過Zookeeper完成的操作,這樣的一個示例是,當分區的管理者想要修改同步副本集時,它目前直接就該Zookeeper。在以後Zookeeper中,管理者将改為向Active Controller進行RPC。
目前,某些工具和腳本直接與Zookeeper聯系,在以後的Zookeeper中,這些工具必須改用為Kafka API。
KRaft目前在Kafka2.8版本是一個測試版本,KRaft模式不推薦使用到生産環境。當Kafka叢集處理KRaft模式時,它不會将其中繼資料存儲在Zookeeper中,實際上根本不需要運作Zookeeper,因為它将中繼資料存儲在Controller節點中。
目前官網退出的KRaft模式僅用于測試,不推薦使用到生産環境,因為官方還不支援将現有的基于Zookeeper的Kafka叢集更新到KRaft模式。實際上,當Kafka3.0釋出時,無法将Kafka叢集從2.8更新到3.0,目前該模式會有些BUG,如果嘗試KRaft使用到生産環境,會存在資料丢失的風險。
步驟1:生成叢集ID
先生成叢集ID,需要使用kafka-storage工具,指令如下:
步驟2:格式化存儲目錄
接下來的步驟是格式化存儲目錄,如果你是運作單節點模式,你可以執行如下指令:
如果,你使用的多節點安裝,你需要在每個節點上執行格式化指令,并確定每個節點使用的叢集ID是相同的。
步驟3:啟動Kafka服務
最後,你可以在每個節點上啟動Kafka服務,指令如下:
之後,我們可以使用jps指令檢視Kafka程序是否已經成功啟動。
在啟動Kafka程序後,我們可以和之前Zookeeper+Kafka的模式一樣,通過連接配接9092端口來操作Topic,Consumer和Producer。例如,建立一個分區為1,副本1的Topic,指令如下:
在KRaft模式下,隻有一小部分特别標明的伺服器可以充當Controller(與基于Zookeeper的模式不同,在這種模式下,任何伺服器都可以成為Controller)。特别標明的Controller伺服器将參與中繼資料的管理,每個Controller伺服器要麼是Active,要麼是Standby。
我們通常會為此角色選擇3台或者5台伺服器,具體取決于成本和系統應承受的并發故障數等因素。就像Zookeeper一樣,為了保持可用性,必須保持大多數Controller處理線上狀态,如果你有3個Controller,可以容忍1次故障,使用5個Controller,可以容忍2次故障。
每個Kafka服務現在有了一個新的配置,它被稱為“process.roles”,它有如下可選值:
broker:它在KRaft模式中扮演一個Broker角色;
controller:它在KRaft模式中扮演一個Controller角色;
broker,controller:它在KRaft模式中同時扮演Broker和Controller角色;
如果沒有設定,則假定我們處于ZooKeeper模式。如前所述,如果不重新格式化,目前無法在ZooKeeper模式和KRaft模式之間來回轉換。
充當Broker和Controller的節點稱為“combined”節點,該節點對簡單用例操作更簡單,并且允許避免與JVM相關的一些固定記憶體開銷。關鍵的缺點是Controller與系統的其餘部分隔離較少。例如,如果Broker上發生OOM,伺服器的Controller部分不會與該OOM隔離。
系統中的所有節點都必須設定“controller.quorum.votters”配置,這辨別應使用的是選舉Controller的伺服器,必須枚舉所有的Controller。這類似在使用Zookeeper時,“zookeeper.connect”配置必須包含所有的Zookeeper伺服器。但是,與Zookeeper配置不同的是,“controller.quorum.configures”還有每個節點ID,格式為id1@host1:port1,id2@host:port2等。
是以,如果你有10個Broker和3和Controller命名為controller1,controller2,controller3,你可以按照如下進行配置:
每個Broker和Controller必須設定“controller.quorum.votters”。請注意,“controller.quorum.votters”配置中提供的節點ID必須與提供給伺服器的節點ID比對。
是以在Controller1上,node.id必須設定為1,依此類推。這裡不要求Controller的ID從0或者1開始。然而,最簡單和最容易混淆的配置設定方法節點ID可能隻是給每個伺服器一個數字ID,從0開始。
需要注意的是,Client端不需要配置“controller.quorum.votters”,隻有伺服器端才需要配置。
這裡我們可以通過kafka-dump-log.sh工具來檢視metadata日志資訊,指令如下所示:
執行結果如下圖所示:
可以通過kafka-metadata-shell.sh來檢視中繼資料資訊,這個和Zookeeper Client操作很類似,指令如下:
然後,進入到一個指令行操作界面,操作步驟如下所示:
目前Kafka2.8中的KRaft處于測試階段,大家如果是學習可以嘗試安裝部署了解和認識這個KRaft模式,生産環境暫時建議不推薦使用。Kafka2.8的主線版本還是以依賴Zookeeper為主,部落客開發的Kafka-Eagle監控工具仍然可以正常監控Kafka2.8,當然KRaft模式的相容,部落客在Kafka-Eagle的測試分支中在進行開發,當Kafka官網将KRaft切換為主線版本時,Kafka-Eagle也會及時切換KRaft作為主線版本來監控Kafka。最後,歡迎大家使用Kafka-Eagle監控工具。
這篇部落格就和大家分享到這裡,如果大家在研究學習的過程當中有什麼問題,可以加群進行讨論或發送郵件給我,我會盡我所能為您解答,與君共勉!
另外,部落客出書了《Kafka并不難學》和《Hadoop大資料挖掘從入門到進階實戰》,喜歡的朋友或同學, 可以在公告欄那裡點選購買連結購買部落客的書進行學習,在此感謝大家的支援。關注下面公衆号,根據提示,可免費擷取書籍的教學視訊。
<b></b><b></b><b></b><b></b>
聯系方式:
Twitter:https://twitter.com/smartloli
QQ群(Hadoop - 交流社群1):424769183
QQ群(Kafka并不難學): 825943084
溫馨提示:請大家加群的時候寫上加群理由(姓名+公司/學校),友善管理者稽核,謝謝!