官網:https://prometheus.io/
下載下傳位址:https://prometheus.io/download/
Prometheus基于Golang編寫,編譯後的軟體包不依賴于任何第三方依賴。隻需要下載下傳對應平台的二進制包,解壓并添加基本的配置即可正常啟動Prometheus Server。
下載下傳安裝包:
wget https://github.com/prometheus/prometheus/releases/download/v2.30.0/prometheus-2.30.0.linux-amd64.tar.gz
解壓:
tar -zxvf prometheus-2.30.0.linux-amd64.tar.gz
修改配置檔案prometheus.yml,添加PushGateway與Node Exporter的監控配置:
prometheus.yml配置檔案說明:
1. global配置塊:控制Prometheus伺服器的全局配置
a) scrape_interval:配置拉取資料的時間間隔,預設為1分鐘
b) evaluation_interval:規則驗證(Evaluate rules,例如生成alert)的時間間隔,預設為1分鐘
2. rule_files配置塊:規則配置檔案
3. scrape_config 配置塊:配置采集目标相關,prometheus監視的目标。Prometheus自身的運作資訊可以通過HTTP通路,是以Prometheus可以監控自己的運作資料。
a) job_name:監控作業的名稱
b) static_configs:表示靜态目标配置,就是固定從某個target拉取資料
c) targets:指定監控的目标,其實就是從哪拉資料。Prometheus會從http://10.0.3.197:9090/metrics 上拉取資料。這個節點為EMR主節點。
Prometheus可以在運作中自動加載配置。啟動時需添加:--web.enable-lifecycle
Prometheus在正常情況下是采用Pull的模式,從産生metric的作業或者exporter(例如專門監控主機的NodeExporter)拉取監控資料。但是我們要監控的是Flink on YARN作業,
想要讓Prometheus自動發現作業的送出、結束以及自動拉取資料顯然是比較困難的。
PushGateway就是一個中轉元件,通過配置Flink on YARN作業将metric推到PushGateway,Prometheus再從PushGateway拉取即可。
下載下傳 pushgateway:
wget https://github.com/prometheus/pushgateway/releases/download/v1.4.1/pushgateway-1.4.1.linux-amd64.tar.gz
tar -zxvf pushgateway-1.4.1.linux-amd64.tar.gz
内容很簡單,隻有一個二進制檔案pushgateway:
wget https://github.com/prometheus/alertmanager/releases/download/v0.23.0/alertmanager-0.23.0.linux-amd64.tar.gz
tar -zxvf alertmanager-0.23.0.linux-amd64.tar.gz
wget https://github.com/prometheus/node_exporter/releases/download/v1.2.2/node_exporter-1.2.2.linux-amd64.tar.gz
tar -zxvf node_exporter-1.2.2.linux-amd64.tar.gz
在Prometheus的架構設計中,Prometheus Server主要負責資料的收集、存儲、并且對外提供資料查詢支援。而實際的監控樣本資料的收集則由Exporter完成。
是以,為了能夠監控到某些東西,例如主機的CPU使用率,我們需要使用到Exporter。Prometheus周期性的從Exporter暴露的HTTP位址(通常是/metrics)拉取監控樣本資料。
Exporter是一個相對開放的概念,其可以是一個獨立運作的程式,獨立于監控目标。也可以是直接内置在監控目标中。隻要能夠向Prometheus提供标準格式的監控樣本資料即可。
為了能夠采集到主機的名額如CPU、記憶體、磁盤等資訊。我們可以使用Node Exporter。Node Exporter 同樣采用Golang編寫,并且不存在任何的第三方依賴。隻需要下載下傳,解壓即可運作。
啟動:./node_exporter
然後即可在執行個體9100端口通路到node export 擷取的目前主機的所有監控資料。例如:
http://10.0.3.197:9100/metrics
此步驟可以通過 bootstrap來完成。
修改 Prometheus配置檔案prometheus.yml,并添加以下配置(前面已添加):
在所有機器上設定為開機啟動:
啟動服務(所有節點):
啟動Prometheus Server:
啟動Pushgateway:
啟動Alertmanager:
檢視web頁面:http://10.0.3.197:9090/
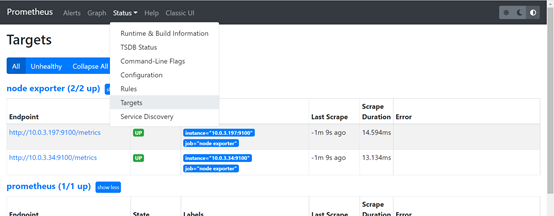
可以看到各個服務都是UP狀态。
Prometheus通過名額名稱(metrics name)以及對應的一組标簽(labelset)唯一定義一條時間序列。名額名稱反映了監控樣本的基本辨別,而label則在這個基本特征上為采集到的資料提供了多種特征次元。使用者可以基于這些特征次元過濾、聚合、統計進而産生新的計算後的一條時間序列。
PromQL是Prometheus内置的資料查詢語言,其提供對時間序列資料豐富的查詢、聚合以及邏輯運算能力的支援。并且被廣泛應用在Prometheus的日常應用中,包括對資料查詢、可視化、告警進行中。
當Prometheus通過Exporter采集到相應的監控名額樣本資料後,我們就可以通過PromQL對監控樣本資料進行查詢。
當我們直接使用監控名額名稱查詢時,可以查詢該名額下的所有時間序列,例如:
prometheus_http_requests_total
其等同于:prometheus_http_requests_total{}

在花括号裡可以加過濾條件,例如:prometheus_http_requests_total{code="302"}
PromQL還支援使用者根據時間序列的标簽比對模式來對時間序列進行過濾,目前主要支援2種比對模式:完全比對和正則比對。
PromQL支援使用 = 和 != 兩種完全比對模式:
通過使用label=value可以選擇那些标簽滿足表達式定義的時間序列
反之使用label != value則可以根據标簽比對排除時間序列
例如,我們隻需要查詢所有prometheus_http_requests_total時間序列種滿足标簽instance為10.0.3.197:9090的時間序列:
prometheus_http_requests_total{instance="10.0.3.197:9090"}
反之使用:prometheus_http_requests_total{instance!="10.0.3.197:9090"}
PromQL還支援正規表達式作為比對條件,多個表達式之間使用 | 進行分離:
使用label=~regx 表示選擇那些标簽符合正規表達式定義的時間序列
反之使用label!~regx進行排除
例如,如果想查詢多個環節下的時間序列,可以使用如下表達式:
排除用法:
直接通過類似于PromQL表達式httprequesttotal查詢時間序列傳回時,傳回值中隻會包含該時間序列中的最新的一個樣本值,這樣的傳回結果我們稱之為瞬時向量。而相應的這樣的表達式稱之為瞬時向量表達式。
而如果我們想查詢過去一段時間範圍内的樣本資料時,需要使用區間向量表達式。區間向量表達式和瞬時向量表達式之間的差異在于:區間向量表達式中我們需要定義時間選擇的範圍,時間範圍通過時間範圍選擇器[]進行定義。例如,通過以下表達式可以選擇最近1分鐘内的所有樣本資料:
prometheus_http_requests_total{}[1m]
該表達式傳回查詢到的時間序列中最近1分鐘的所有樣本資料:
通過區間向量表達式查詢得到的結果稱為區間向量。除了使用m表示分鐘外,PromQL的時間範圍選擇器支援其他時間機關:
s – 秒
m – 分鐘
h – 小時
d – 天
w – 周
y – 年
在瞬時向量表達式或者區間向量表達式中,都是以目前的時間為基準:
prometheus_http_requests_total{} # 瞬時向量表達式,選擇目前最新的資料
prometheus_http_requests_total{}[1m] # 區間向量表達式,選擇以目前時間為基準,1分鐘内的資料
若是想查詢1分鐘前的瞬時樣本資料,或者昨天一天的區間内的樣本資料。此時可以使用位移操作,關鍵字為offset:
一般來說,如果描述該樣本特征的标簽(label)并非唯一的情況下,通過PromQL查詢資料時,會傳回多條滿足這些特征次元的時間序列。而PromQL提供的聚合操作可以用來對這些時間序列進行處理,形成一條新的時間序列:
除了使用瞬時向量表達式和區間向量表達式以外,PromQL還支援使用者使用标量(Scalar)和字元串(String)。
1. 标量(Scalar):一個浮點型的數字值
标量隻有一個數字,沒有時序。例如:10
需要注意的是,當使用表達式count( prometheus_http_requests_total),傳回的資料類型,依然是瞬時向量。使用者可以通過内置函數scalar()将單個瞬時向量轉換為标量。
2. 字元串(String):一個簡單的字元串值
直接使用字元串,作為PromQL表達式,則會直接傳回字元串。
所有的PromQL表達式都必須至少包含一個名額名稱(例如http_request_total),或者一個不會比對到空字元串的标簽過濾器(例如{code=”200”})。
是以以下2種方式,均為合法的表達式:
如下表達式不合法:
同時,除了使用{label=value} 的形式外,還可以使用内置的 __name__ 标簽來指定監控名額名稱:
使用PromQL除了能夠友善的按照查詢和過濾時間序列外,PromQL還支援豐富的操作符,使用者可以使用這些操作符,進一步對時間序列進行二次加工。這些操作符包括:數學運算符、邏輯運算符、布爾運算符等。
PromQL支援的所有數學運算符包括:+、-、*、/、%、^
Prometheus支援的布爾運算符包括:==(相等)、!=(不相等)、>、<、>=、<=
使用bool修飾符改變布爾運算的行為
布爾運算符的預設行為是對時序資料進行過濾。而在其他的情況下我們可能需要的是真正的布爾結果。例如,隻需要知道目前子產品的HTTP請求量是否 >=1000,如果大于等于1000則傳回1(true)否則傳回0(false)。這是可以使用bool修飾符改變布爾運算的預設行為。例如:
使用bool修飾符後,布爾運算不會對時間序列進行過濾,而是直接依次對瞬時向量種的各個樣本資料與标量進行比較,得到結果0或1。進而形成一條新的時間序列。
同時需要注意的是,如果是在2個标量之間使用布爾運算,則必須使用bool修飾符:
使用瞬時向量表達式能夠擷取到一個包含多個時間序列的集合,我們稱為瞬時向量。通過集合運算,可以在2個瞬時向量之間進行相應的集合操作。
目前,Prometheus支援以下集合運算符:
l and(并且)
l or(或者)
l unless(排除)
vector1 and vector2 會産生一個由vector1的元素組成的新的向量。該向量包含vector1種完全比對vector2種的元素組成。
vector1 or vector2 會産生一個新的向量,該向量包含vector1中所有的樣本資料,以及vector2中沒有與 vector1比對到的樣本資料。
vector1 unless vector2 會産生一個新的向量,新向量中的元素由vector1中沒有與vector2比對的元素組成。
對于複雜類型的表達式,需要了解運算操作的運作優先級。例如,查詢主機的CPU使用率,可以使用表達式:
其中irate是PromQL中的内置函數,用于計算區間向量中時間序列每秒的即時增長率。在PromQL操作符中優先級由高到低依次為:
l ^
l *, /, %
l +, -
l ==, !=, <=, =>
l and, unless
l or
Prometheus還提供了下列内置的聚合操作符,這些操作符作用于瞬時向量。可以将瞬時表達式傳回的樣本資料進行聚合,形成一個新的時間序列。
l sum
l min
l max
l avg
l stddev
l stdvar
l count
l count_values
l bottomk(後n條時序)
l topk
l quantile
使用聚合操作的文法如下:
其中隻有count_values, quantile, topk, bottom 支援參數(parameter)。
without用于從計算結果中移除列舉的标簽,而保留其他标簽。by 則正好相反,結果向量中隻保留列出的标簽,其餘标簽則移除。通過without和by可以按照樣本的問題對資料進行聚合。
例如:
count_values用于時間序列中每一個樣本值出現的次數。count_values會為每一個唯一的樣本值輸出一個時間序列,并且每一個時間序列包含一個額外的标簽。例如:
topk和bottomk則用于對樣本值進行排序,傳回目前樣本值前n位,或者後n位的時間序列。
擷取HTTP請求數前5的時序樣本資料,可以使用表達式:
quantile用于計算目前樣本資料值的分布情況quantile(φ, express) 其中 0≤φ≤1。
例如,當φ為0.5時,即表示找到目前樣本資料中的中位數:
Flink提供的Metrics可以在Flink内部收集一些名額,通過這些名額,可以讓開發者更好地了解作業或叢集的狀态。由于叢集運作後很難發現内部的實際狀況,例如是否執行緩慢、是否異常等。開發人員無法實時檢視所有的Task日志。例如作業很大或者有很多作業的情況下,該如何處理?此時Metrics可以幫助開發人員了解作業的目前狀況。
Flink官方支援了Prometheus,并且提供了對接Prometheus的jar包,內建起來很友善。
下載下傳flink-metrics-prometheus.jar 包:
wget https://repo1.maven.org/maven2/org/apache/flink/flink-metrics-prometheus_2.11/1.12.1/flink-metrics-prometheus_2.11-1.12.1.jar
将此jar包拷貝到<flink_home>/lib 目錄下:
sudo cp flink-metrics-prometheus_2.11-1.12.1.jar /usr/lib/flink/lib/
修改flink-conf.yaml檔案,增加以下配置:
送出1個flink job:
flink run -c com.tang.wc.StreamWordCount -m yarn-cluster Flink.jar 10.0.3.197
然後即可在 Prometheus中查詢到Flink的各項名額,例如:flink_jobmanager_Status_JVM_Memory_Heap_Used