1)shuffle産生海量的小檔案在磁盤上,此時會産生大量耗時的、低效的IO操作;
2)容易導緻記憶體不夠用,由于記憶體需要儲存海量的檔案操作句柄和臨時緩存資訊,如果資料處理規模比較大的話,容易出現OOM;
3)容易出現資料傾斜,導緻OOM。
1)conslidate為了解決Hash Shuffle同時打開過多檔案導緻Writer handler記憶體使用過大以及産生過多檔案導緻大量的随機讀寫帶來的低效磁盤IO;
2)conslidate根據CPU的個數來決定每個task shuffle map端産生多少個檔案,假設原來有10個task,100個reduce,每個CPU有10個CPU,那麼
使用hash shuffle會産生10100=1000個檔案,conslidate産生1010=100個檔案
注意:conslidate部分減少了檔案和檔案句柄,并行讀很高的情況下(task很多時)還是會很多檔案。
1)參數用于設定每個stage的預設task數量。這個參數極為重要,如果不設定可能會直接影響你的Spark作業性能;
2)很多人都不會設定這個參數,會使得叢集非常低效,你的cpu,記憶體再多,如果task始終為1,那也是浪費,
spark官網建議task個數為CPU的核數*executor的個數的2~3倍。
1)spark.shuffle.memoryFraction是shuffle調優中 重要參數,shuffle從上一個task拉去資料過來,要在Executor進行聚合操作,
聚合操作時使用Executor記憶體的比例由該參數決定,預設是20%如果聚合時資料超過了該大小,那麼就會spill到磁盤,極大降低性能;
2)如果Spark作業中的RDD持久化操作較少,shuffle操作較多時,建議降低持久化操作的記憶體占比,提高shuffle操作的記憶體占比比例,
避免shuffle過程中資料過多時記憶體不夠用,必須溢寫到磁盤上,降低了性能。此外,如果發現作業由于頻繁的gc導緻運作緩慢,意味着task執行使用者代碼的記憶體不夠用,
那麼同樣建議調低這個參數的值。
1)特點:
(1)standalone是master/slave架構,叢集由Master與Worker節點組成,程式通過與Master節點互動申請資源,Worker節點啟動Executor運作;
(2)standalone排程模式使用FIFO排程方式;
(3)無依賴任何其他資源管理系統,Master負責管理叢集資源。
2)優點:
(1)部署簡單;
(2)不依賴其他資源管理系統。
3)缺點:
(1)預設每個應用程式會獨占所有可用節點的資源,當然可以通過spark.cores.max來決定一個應用可以申請的CPU cores個數;
(2)可能有單點故障,需要自己配置master HA。
基本原理:按照先後順序決定資源的使用,資源優先滿足最先來的job。第一個job優先擷取所有可用的資源,接下來第二個job再擷取剩餘資源。
以此類推,如果第一個job沒有占用所有的資源,那麼第二個job還可以繼續擷取剩餘資源,這樣多個job可以并行運作,如果第一個job很大,占用所有資源,
則第二job就需要等待,等到第一個job釋放所有資源。
優點和缺點:
1)适合長作業,不适合短作業;
2)适合CPU繁忙型作業(計算時間長,相當于長作業),不利于IO繁忙型作業(計算時間短,相當于短作業)。
所有的任務擁有大緻相當的優先級來共享叢集資源,spark多以輪訓的方式為任務配置設定資源,不管長任務還是端任務都可以獲得資源,并且獲得不錯的響應時間,
對于短任務,不會像FIFO那樣等待較長時間了,通過參數spark.scheduler.mode 為FAIR指定。
1)原理:
計算能力排程器支援多個隊列,每個隊列可配置一定的資源量,每個隊列采用 FIFO 排程政策,為了防止同一個使用者的作業獨占隊列中的資源,該排程器會對
同一使用者送出的作業所占資源量進行限定。排程時,首先按以下政策選擇一個合适隊列:計算每個隊列中正在運作的任務數與其應該分得的計算資源之間的
比值(即比較空閑的隊列),選擇一個該比值最小的隊列;然後按以下政策選擇該隊列中一個作業:按照作業優先級和送出時間順序選擇,
同時考慮使用者資源量限制和記憶體限制
(1)計算能力保證。支援多個隊列,某個作業可被送出到某一個隊列中。每個隊列會配置一定比例的計算資源,且所有送出到隊列中的作業
共享該隊列中的資源;
(2)靈活性。空閑資源會被配置設定給那些未達到資源使用上限的隊列,當某個未達到資源的隊列需要資源時,一旦出現空閑資源資源,便會配置設定給他們;
(3)支援優先級。隊列支援作業優先級排程(預設是FIFO);
(4)多重租賃。綜合考慮多種限制防止單個作業、使用者或者隊列獨占隊列或者叢集中的資源;
(5)基于資源的排程。 支援資源密集型作業,允許作業使用的資源量高于預設值,進而可容納不同資源需求的作業。不過,目前僅支援記憶體資源的排程。
1)資料壓縮,大片連續區域進行資料存儲并且存儲區域中資料重複性高的狀況下,可以使用适當的壓縮算法。數組,對象序列化後都可以使用壓縮,數更緊湊,
減少空間開銷。常見的壓縮方式有snappy,LZO,gz等
2)Hadoop生産環境常用的是snappy壓縮方式(使用壓縮,實際上是CPU換IO吞吐量和磁盤空間,是以如果CPU使用率不高,不忙的情況下,
可以大大提升叢集處理效率)。snappy壓縮比一般20%~30%之間,并且壓縮和解壓縮效率也非常高(參考資料如下):
(1)GZIP的壓縮率最高,但是其實CPU密集型的,對CPU的消耗比其他算法要多,壓縮和解壓速度也慢;
(2)LZO的壓縮率居中,比GZIP要低一些,但是壓縮和解壓速度明顯要比GZIP快很多,其中解壓速度快的更多;
(3)Zippy/Snappy的壓縮率最低,而壓縮和解壓速度要稍微比LZO要快一些。
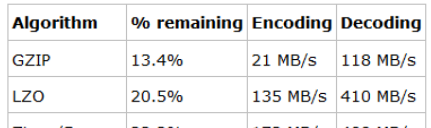
提升了多少效率可以從2方面回答:1)資料存儲節約多少存儲,2)任務執行消耗時間節約了多少,可以舉個實際例子展開描述。
val conf = new SparkConf()
val sc = new SparkContext(conf)
val line = sc.textFile("xxxx.txt") line.flatMap(.split(" ")).map((,1)).reduceByKey(+). collect().foreach(println) sc.stop()
1)mr2隻有2個階段,資料需要大量通路磁盤,資料來源相對單一 ,spark RDD ,可以無數個階段進行疊代計算,資料來源非常豐富,資料落地媒體也
非常豐富spark計算基于記憶體;
2)MapReduce2需要頻繁操作磁盤IO,需要大家明确的是如果是SparkRDD的話,你要知道每一種資料來源對應的是什麼,RDD從資料源加載資料,
将資料放到不同的partition針對這些partition中的資料進行疊代式計算計算完成之後,落地到不同的媒體當中。
Spark更加快的主要原因有幾點:
1)基于記憶體計算,減少低效的磁盤互動;
2)高效的排程算法,基于DAG;
3)容錯機制Lingage,主要是DAG和Lianage,即使spark不使用記憶體技術,也大大快于mapreduce。
計算引擎不一樣,一個是spark計算模型,一個是mapreudce計算模型。
一個RDD對象,包含如下5個核心屬性。
1)一個分區清單,每個分區裡是RDD的部分資料(或稱資料塊)。
2)一個依賴清單,存儲依賴的其他RDD。
3)一個名為compute的計算函數,用于計算RDD各分區的值。
4)分區器(可選),用于鍵/值類型的RDD,比如某個RDD是按散列來分區。
5)計算各分區時優先的位置清單(可選),比如從HDFS上的檔案生成RDD時,RDD分區的位置優先選擇資料所在的節點,這樣可以避免資料移動帶來的開銷。
頻繁建立額外對象,容易oom。
hadoop生态主要分為三大類型,1)分布式檔案系統,2)分布式計算引擎,3)周邊工具
1)分布式系統:HDFS,hbase
2)分布式計算引擎:Spark,MapReduce
3)周邊工具:如zookeeper,pig,hive,oozie,sqoop,ranger,kafka等
region超過了hbase.hregion.max.filesize這個參數配置的大小就會自動裂分,預設值是1G。
預設情況下,hbase有多少個region,Spark讀取時就會有多少個partition 。
![pyspark學習(一)—pyspark的安裝與基礎文法一 Pysaprk的安裝二:pyspark的簡單文法END[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)