聽到<code>謂詞下推</code>這個詞,是不是覺得很高大上,找點資料看了半天才能搞懂概念和思想,借這個機會好好學習一下吧。
引用範欣欣大佬的部落格中寫道,以前經常滿大街聽到謂詞下推,然而對謂詞下推卻總感覺懵懵懂懂,并不明白的很真切。這裡拿出來和大家交流交流。個人認為謂詞下推有兩個層面的了解:
其一是邏輯執行計劃優化層面的說法,比如SQL語句:select * from order ,item where item.id = order.item_id and item.category = ‘book’,正常情況文法解析之後應該是先執行Join操作,再執行Filter操作。通過謂詞下推,可以将Filter操作下推到Join操作之前執行。即将where item.category = ‘book’下推到 item.id = order.item_id之前先行執行。
其二是真正實作層面的說法,謂詞下推是将過濾條件從計算程序下推到存儲程序先行執行,注意這裡有兩種類型程序:計算程序以及存儲程序。計算與存儲分離思想,這在大資料領域相當常見,比如最常見的計算程序有SparkSQL、Hive、impala等,負責SQL解析優化、資料計算聚合等,存儲程序有HDFS(DataNode)、Kudu、HBase,負責資料存儲。正常情況下應該是将所有資料從存儲程序加載到計算程序,再進行過濾計算。謂詞下推是說将一些過濾條件下推到存儲程序,直接讓存儲程序将資料過濾掉。這樣的好處顯而易見,過濾的越早,資料量越少,序列化開銷、網絡開銷、計算開銷這一系列都會減少,性能自然會提高。
謂詞下推 <code>Predicate Pushdown(PPD)</code>:簡而言之,就是在不影響結果的情況下,盡量将過濾條件提前執行。謂詞下推後,過濾條件在map端執行,減少了map端的輸出,降低了資料在叢集上傳輸的量,節約了叢集的資源,也提升了任務的性能。
PPD 配置
PPD控制參數:<code>hive.optimize.ppd</code>,預設值:<code>true</code>
PPD規則:
Preserved Row tables
Null Supplying tables
Join Predicate
Case J1: Not Pushed
Case J2: Pushed
Where Predicate
Case W1: Pushed
Case W2: Not Pushed
<code>Push</code>:謂詞下推,可以了解為被優化
<code>Not Push</code>:謂詞沒有下推,可以了解為沒有被優化
實驗結果清單形式:
Pushed or Not
SQL
Pushed
select ename,dept_name from E join D on ( E.dept_id = D.dept_id and E.eid='HZ001');
select ename,dept_name from E join D on E.dept_id = D.dept_id where E.eid='HZ001';
select ename,dept_name from E join D on ( E.dept_id = D.dept_id and D.dept_id='D001');
select ename,dept_name from E join D on E.dept_id = D.dept_id where D.dept_id='D001';
Not Pushed
select ename,dept_name from E left outer join D on ( E.dept_id = D.dept_id and E.eid='HZ001');
select ename,dept_name from E left outer join D on E.dept_id = D.dept_id where E.eid='HZ001';
select ename,dept_name from E left outer join D on ( E.dept_id = D.dept_id and D.dept_id='D001');
select ename,dept_name from E left outer join D on E.dept_id = D.dept_id where D.dept_id='D001';
select ename,dept_name from E right outer join D on ( E.dept_id = D.dept_id and E.eid='HZ001');
select ename,dept_name from E right outer join D on E.dept_id = D.dept_id where E.eid='HZ001';
select ename,dept_name from E right outer join D on ( E.dept_id = D.dept_id and D.dept_id='D001');
select ename,dept_name from E right outer join D on E.dept_id = D.dept_id where D.dept_id='D001';
select ename,dept_name from E full outer join D on ( E.dept_id = D.dept_id and E.eid='HZ001');
select ename,dept_name from E full outer join D on E.dept_id = D.dept_id where E.eid='HZ001';
select ename,dept_name from E full outer join D on ( E.dept_id = D.dept_id and D.dept_id='D001');
select ename,dept_name from E full outer join D on E.dept_id = D.dept_id where D.dept_id='D001';
實驗結果表格形式:
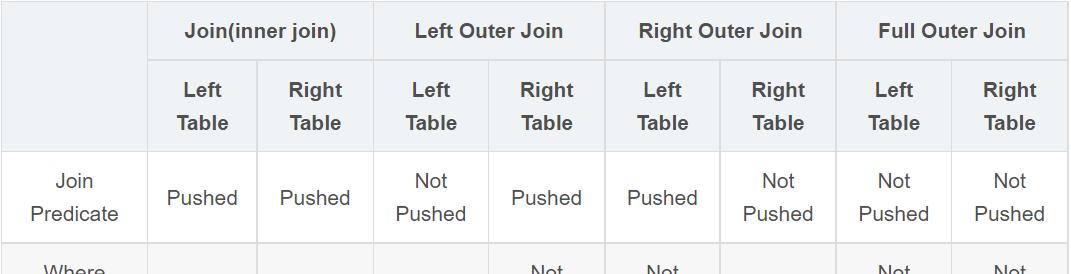
此表實際上就是上述PPD規則表。
1、對于Join(Inner Join)、Full outer Join,條件寫在on後面,還是where後面,性能上面沒有差別;
2、對于Left outer Join ,右側的表寫在on後面、左側的表寫在where後面,性能上有提高;
3、對于Right outer Join,左側的表寫在on後面、右側的表寫在where後面,性能上有提高;
4、當條件分散在兩個表時,謂詞下推可按上述結論2和3自由組合,情況如下:
過濾時機
<code>select ename,dept_name from E left outer join D on ( E.dept_id = D.dept_id and E.eid='HZ001' and D.dept_id = 'D001');</code>
dept_id在map端過濾,eid在reduce端過濾
<code>select ename,dept_name from E left outer join D on ( E.dept_id = D.dept_id and D.dept_id = 'D001') where E.eid='HZ001';</code>
dept_id,eid都在map端過濾
<code>select ename,dept_name from E left outer join D on ( E.dept_id = D.dept_id and E.eid='HZ001') where D.dept_id = 'D001';</code>
dept_id,eid都在reduce端過濾
<code>select ename,dept_name from E left outer join D on ( E.dept_id = D.dept_id ) where E.eid='HZ001' and D.dept_id = 'D001';</code>
dept_id在reduce端過濾,eid在map端過濾
注意:如果在表達式中含有不确定函數,整個表達式的謂詞将不會被pushed,例如
因為<code>unix_timestamp</code>是不确定函數,在編譯的時候無法得知,是以,整個表達式不會被pushed,即ds='2019-10-09'也不會被提前過濾。類似的不确定函數還有rand()等。
參考文獻:
[1] https://cwiki.apache.org/confluence/display/Hive/OuterJoinBehavior
引用:https://blog.csdn.net/strongyoung88/article/details/81156271
猜你喜歡
Hive計算最大連續登陸天數
Hadoop 資料遷移用法詳解
Hbase修複工具Hbck
數倉模組化分層理論
一文搞懂Hive的資料存儲與壓縮
大資料元件重點學習這幾個
![Hive中内部表、外部表、分區、分桶以及SQL的執行順序[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)