通過上一篇文章的扯淡,我們應該已經明白了存儲器的層次結構,技術細節很複雜,但是思想卻不難了解,因為就是很簡單的緩存思想。那麼本文我們開始讨論關于記憶體的另一個話題.虛拟記憶體。其實思想也是很容易了解的。
我不知道有多少人聽過虛拟記憶體這個概念,但是虛拟記憶體是計算機系統最重要的概念之一,并且它成功的主要原因就是它一直在沉默的,自動的工作,換句話說,我們這些做應用的程式員根本不需要幹涉它的工作過程,但是一個沒追求的碼農不是好的搬磚民工,是以作為一個有理想有抱負的程式員,我們還是要去了解虛拟記憶體,甚至可以這樣說,如果不了解虛拟記憶體,你根本不可能了解程式的深層次運作原理。也不可能去了解彙編器,連結器,加載器,共享對象,檔案和程序等概念。
上篇文章中提出了幾個讓大家思考的問題:
不管什麼程式,最後的直接/間接的編譯結果都是0和1,(我們直接了解為彙編)。(這點不知道的,歡迎閱讀我的另一篇文章關于跨平台的一些認識),比如這句彙編代碼:<code>mov eax,0x123456;</code>它的意思是将記憶體<code>0x123456</code>處的内容送往<code>eax</code>這個寄存器。各個應用的資料共同存在記憶體中的。假設有一個音樂播放器應用的彙編代碼中,引用了<code>0x123456</code>這個記憶體位址。但是同時運作的應用有很多,那其他應用也完全有可能引用 <code>0x123456</code>這個位址。那為什麼竟然沒起沖突和錯誤呢?
程序是計算機領域最重要的概念之一,什麼是程序?程序是關于某次資料集合的一次運作活動, 是運作在它自己位址空間的一段自包容程式, 解釋的通俗的點, 一個程式在運作時,我們會得到一個假象,該程序好像是獨占地使用CPU和記憶體,CPU是沒有間斷地一條接一條的執行該程式的指令,所有的記憶體空間都是供該程序的代碼和資料配置設定使用的。(這點不嚴謹,其實記憶體還有一部分要分給<code>核心kernel</code>)。說起來,這個程式就好像得到了全世界一樣。,CPU是我的,記憶體也全部我的,妹子們還是我的。當然這是假象而已。但是這些假象又是怎麼做到的呢?
程式中都會引用庫API,比如每個C程式都要引用<code>stdio.h</code>庫的<code>printf()</code>,在程式運作時,庫代碼也要被加入到記憶體,這麼多程式都引用了這個庫,難道我記憶體中需要加很多份嗎?這自然不可能,那麼庫代碼又是怎麼被所有程序共享的呢?
這些讓我們細思恐極的疑問,都将通過這篇文章來給大家解答。
在通路者看來,主存就是一個有M個位元組大小的單元組成的數組,每位元組都有一個唯一的實體位址(Physical Address, PA)。 它的通路位址和數組一樣,第一個位址為0,後面位址依次為<code>1,2,3-----M-2, M-1</code>;這叫做線性位址空間。這種自然的通路記憶體的方式我們稱之為實體尋址(physical addressing)。
注意:在通路記憶體時,對于任意一個位址,(不管是第0個還是第M-1個),通路該位址的時間總是相同的。
在各種資料結構中,我們都說hash表是最快的,比紅黑樹之類的都要快,那hash表為什麼最快?那是因為hash表内部本質上是使用了數組。是以還是數組最快,那數組為什麼最快?這是因為我們知道數組的起始位址以及某個元素的序号,就可以得到該元素在記憶體中的位址,而對于記憶體,通路任意一個位址,通路時間總是相同的。而類似連結清單,樹等結構,卻隻能靠周遊了。(不過好的hash算法還是很難設計的,這是另外一個話題了)。
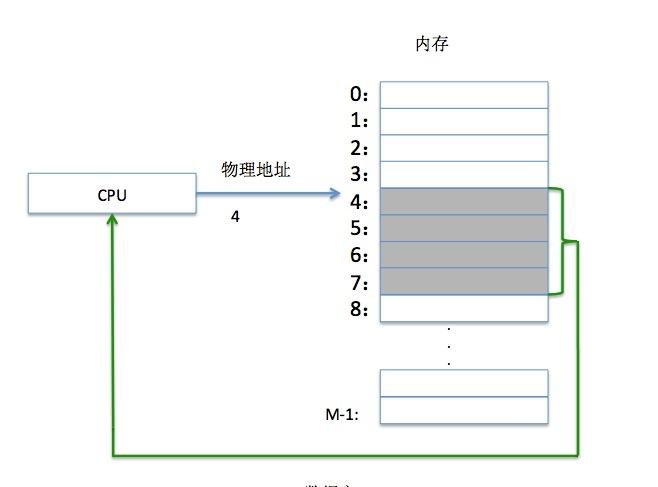
圖10:一個使用實體尋址的系統
上圖是一個實體尋址的示例,這是一條加載指令,它讀取從實體位址4開始的4個位元組,CPU通過記憶體總線,将指令和位址傳遞給主存,主存讀取從實體位址4處開始的4個位元組,傳回給CPU。
因為這篇文章主要讨論 虛拟記憶體,是關于L4級主存和磁盤之間的互動問題,為行文友善,文章中有時候直接說記憶體代指主存。是以這些不要誤以為是指L1,L2之類的緩存。如果看不懂這段話啥意思,務必看看我的上一篇文章什麼是記憶體(一):存儲器層次結構,然後再來看這篇文章。
早期計算機使用實體尋址方式,但是到了現在的多任務計算機時代,普遍使用的是虛拟尋址(virtual addressing)。如下圖所示:

圖11:一個使用虛拟尋址的系統
CPU 通過一個虛拟位址(virtual address,VA)來通路主存,這個虛拟位址在被送到主存之前會先轉換成一個實體位址。将虛拟位址轉換成實體位址的任務叫做位址翻譯(address translation)。
位址翻譯需要 CPU 硬體和作業系統之間的配合。 CPU 晶片上叫做記憶體管理單元(Menory Management Unit, MMU)的專用硬體,利用存放在主存中的查詢表來動态翻譯虛拟位址,該表的内容由作業系統管理。
有少數現代計算機系統依舊在使用實體尋址方式,比如DSP,嵌入式系統,超級計算機系統。這些系統的主要任務是執行單一任務,不像通用性計算機那樣需要執行多任務。可以想象到,實體尋址方式更快。這個道理和關于跨平台的一些認識文章中,理論上java比C++慢的道理是一樣的。
前面解釋完虛拟位址,那麼關于文章開頭時提的那些疑問,可能有些人心裡面都有數了。因為那些位址都是虛拟位址,并非真實的實體記憶體當中的位址。基本思想已經懂了,那麼剩下的我們就更具體的讨論細節。
圖12:程序位址空間
上圖是一個64位的程序位址空間,編譯器在編譯程式時,将結果編譯成32/64位的位址空間。虛拟尋址方式簡化了編譯器,連結器的工作。同樣也因為虛拟記憶體,每個程序才能有很大的,一緻的,私有的的位址空間。這友善了記憶體管理,保護了每個程序的位址空間不被其他程序破壞。同時也友善了共享庫。
虛拟記憶體将主存看成是一個磁盤的高速緩存,主存中隻儲存活動區域,并根據需要在磁盤和主存之間來回傳送資料。
從概念上來說,虛拟記憶體被組織成為一個由存放在磁盤上的 N 個連續的位元組大小的單元組成的數組,也就是位元組數組。每個位元組都有一個唯一的虛拟位址作為數組的索引。虛拟記憶體的位址和磁盤的位址之間建立影射關系。磁盤上活動的數組内容被緩存在主存中。在存儲器層次結構中,磁盤(較低層L5,參見我們上篇文章圖4)的資料被分割成塊(block),這些塊作為和主存(較高層,L4)之間的傳輸單元。主存作為虛拟記憶體(或者說磁盤)的緩存。
虛拟記憶體(VM)系統将虛拟記憶體分割成稱為大小固定的虛拟頁(Virtual Page,VP),每個虛拟頁的大小為固定位元組。同樣的,實體記憶體被分割為實體頁(Physical Page,PP),大小也為固定位元組(實體頁也稱作頁幀,page frame)。
在任意時刻,虛拟頁面都分為三個不相交的部分:
未配置設定的(Unallocated):VM 系統還未配置設定(或者建立)的頁,未配置設定的頁沒有任何資料和它們關聯,是以不占用任何記憶體/磁盤空間。
緩存的(Cached):目前已緩存在實體記憶體中的已配置設定頁。
未緩存的(UnCached):該頁已經映射到磁盤上了,但是還沒緩存在實體記憶體中。
其中未配置設定的VP不占用任何的實際實體空間,這點要了解。32位程式位址空間就有4G,至于64G的程式它的位址空間是一個非常大的天文數字(貌似是16777216T),而目前我們的電腦高配的也就2T磁盤,16G記憶體。如果64位程式每個VP都映射着實際的PP。無論如何也對應不上的。并且也完全沒必要一一映射,"圖12:程序位址空間"中可以看到,位址空間内有大量的空白。畢竟程式不可能實際使用那麼大的位址空間。
圖13:VM使用主存來作為緩存
上圖展示了在一個有 8 個頁面的虛拟記憶體中,虛拟頁 0 和 3 還沒有被配置設定,是以在磁盤上不存在。虛拟頁 1,4,6 被緩存在實體記憶體中。虛拟頁 2,5,7 已經被映射配置設定了,但是還沒有緩存在主存中。
當然,那個圖上标注的不對,VP 部分, <code>n-p</code>和<code>N-1</code>應該分别标注為<code>3</code>和<code>7</code>,不過我們找不到更合适的圖了,(這種圖自己畫壓力太大了)。是以大家知道我們假設共有8個VP就好了。
系統必須得有辦法判定某個虛拟頁是否緩存在主存的某個地方。這具體可分為兩種情況。
已經在主存中,就需要判斷出該虛拟頁存在于哪個實體頁中。
不在主存中,那麼系統必須判斷虛拟頁存放在磁盤的哪個位置,并且在實體主存中選擇一個犧牲頁,并将該虛拟頁從磁盤複制到 主存,替換這個犧牲頁。
這些功能由軟硬體聯合提供,包括作業系統,CPU中的記憶體管理單元(Memory Management Unit,MMU)和一個存放在實體記憶體中叫頁表(page table)的資料結構,頁表将虛拟頁映射到實體頁。每次位址翻譯硬體将一個虛拟位址轉換成實體位址時都會讀取頁表。
圖14:頁表
上圖展示了一個頁表的基本結構,頁表就是一個頁表條目(Page Table Entry,PTE)的數組。虛拟位址的每個頁在頁表中都有一個對應的PTE。在這裡我們假設每個 PTE 是由一個有效位(Valid bit)和一個 n 位位址字段組成的。有效位表明了該虛拟頁目前是否被緩存在 主存 中。
有效位為 1,則主存緩存了該虛拟頁。位址字段就表示主存中相應的實體頁的起始位置。
有效位為 0,則位址字段的null表示這個虛拟頁還未被配置設定,否則該位址就指向該虛拟頁在磁盤上的起始位置。
我們在上篇文章什麼是記憶體(一):存儲器層次結構中說過緩存命中與不命中的問題,都是緩存思想,在這裡肯定也會存在同樣的問題。并且磁盤與主存之間的緩存不命中代價肯定大的多。因為L0-L4之間,每級緩存的速度大約相差10倍左右,但是L4主存與L5磁盤之間,它們的速度相差約十萬倍。是以主存與磁盤之間交換的頁容量是最大的,盡可能的增加命中率。相應的替換政策,作業系統也使用了更加複雜精密的算法。
在上篇文章什麼是記憶體(一):存儲器層次結構,每次替換的區域,我們用了塊(block),而這裡我們卻在說頁(page), 其實同一個意思。隻是因為曆史原因,叫法不同罷了。
當CPU想要讀取包含在某個虛拟頁的内容時,如果該頁已經緩存在主存中,也就是頁命中。perfect,很完美。但是如果該頁沒有緩存在主存中,則我們稱之為缺頁(page fault)
圖15:對VP3中的字的應用會引起不命中
如上圖所示,CPU 引用了 VP3 中的内容, VP3 并未緩存在主存中。系統從記憶體中讀取 PTE3,得知 VP3 未被緩存,這會觸發了一個缺頁異常。缺頁異常會調用kernel的缺頁異常處理程式,該程式會選擇一個犧牲頁。如下圖所示,犧牲頁選擇了存放在 PP3 中的 VP4。
圖16:VP4被犧牲了
此時如果 VP4 的内容被修改了,kernel會将它複制回磁盤。接下來,kernel從磁盤指派 VP3 到記憶體中的 PP3并更新 PTE3。随後傳回使用者程序。當異常處理程式傳回時,它會重新開機執行導緻缺頁的指令,當重新執行這條指令時,因為 VP3 已經在主存中了,此時就是頁命中了。
圖17:VP3被緩存到PP3
根據習慣性的叫法,我們在磁盤和記憶體之間傳送頁的活動叫做交換(swapping)或者頁面排程(paging)。這種交換活動,隻有當不命中發生時才會發生,(也就說,系統并不會将磁盤内容預存到記憶體中)。這種政策被稱之為按需頁面排程(demand paging)。
我們剛才說,缺頁錯誤是一種異常,但是實際上,在計算機系統中,被0除,讀寫檔案,還有上篇文章中我們所說的中斷(interrupt),甚至包括我們代碼中寫的<code>try catch</code>,都是一種異常。 比如被0除是intel 的CPU規定的的第0号故障(fault)類型的異常。而讀寫檔案,分别是linux規定的第0号和第1号陷阱(trap)類型的異常。多任務的上下文切換,程序的建立回收等,等與系統中這種異常流的處理密切相關。當然,這是另外一個話題了。我們在這裡不做累述。
理所當然的,每個程序都有一個獨立的頁表和一個獨立的虛拟位址空間
回到文章開頭的問題,比如每個C程式都要調用的 <code>stdio</code>這個庫,不可能為每個程序都添加一份庫,記憶體中隻有一份<code>stdio</code>庫的内容,供每個使用該庫的程序共享。
圖18:共享頁面
如上圖所示: 第一個程序的的頁表将 VP2 映射到 某個實體頁面。而第二個程序同樣将它的 VP2 映射到 該實體頁面。是以該實體頁面都被兩個程序共享了。
此時,大家再看一下"圖:12 程序位址空間",就會發現在位址空間當中,"共享庫的記憶體映射區域"對于每個程序起始位址都是相同的。再想想程序之間共享記憶體的通信方式, 是以說虛拟記憶體簡化了共享機制
大家知道,C語言中存在指針,可以直接進行記憶體操作。因為有了虛拟記憶體,是以我們的指針操作也不會通路到其他程序的區域,但是哪怕是對于自己的位址空間,很多記憶體區域也應該是禁止通路的,這不僅包括kernel的區域,也包括自己的隻讀代碼段。那麼虛拟記憶體就提供了這樣的一種記憶體保護工具。
位址翻譯機制可以使用一種自然的方式來提供記憶體的通路控制。PTE 上添加一些額外的控制位來添權重限。每次 CPU 生成一個位址時,位址翻譯硬體都會讀一個 PTE 。
圖19:虛拟記憶體提供記憶體保護
在上圖中,每個 PTE 額外添加了三個控制位, SUP 位表示程序是否必須運作核心模式,READ和WRITE位分别控制頁面的讀寫權限。如果有指令違反了這些控制權限,那麼 CPU 會觸發一個故障,并将控制傳遞給核心中的異常處理程式。該種異常一般稱為段錯誤(segmentation fault)。
我們明白了頁,頁是作業系統為了管理主存友善而劃分的,對使用者不可見。但是思考這種情況,假設一個頁的大小是1M。但是某個程式資料加起來也就0.5M,是以在記憶體和磁盤進行頁交換明顯的浪費記憶體了。是以還一種劃分方式是分段。上面那個例子,我将該段劃分為0.5M,在記憶體和磁盤之間交換,這樣就避免了浪費。
段是資訊的邏輯單元,是根據使用者需求而靈活劃分的,是以大小不固定,對使用者是可見的,提供的是二維位址空間。
對于段,我沒找到比較好的資料,是以也沒有了解的更清楚,網上的很多文章都互相抄襲。據我所了解,彙程式設計式員是可以直接操作段的,但是我們寫進階語言的程式員有相應的API能進行段操作嗎?是以對于段的相關知識,真心不了解,也希望了解的同學可以在留言區指點批評,或者留言相關的文章連結。我回頭會再補充這篇部落格。謝謝
熟悉linux的同學,應該知道linux有一個swap分區。Swap空間的作用可簡單描述為:當系統的實體記憶體不夠用的時候,就需要将實體記憶體中的一部分空間釋放出來,以供目前運作的程式使用。那些被釋放的空間可能來自一些很長時間沒有什麼操作的程式,這些被釋放的空間中的資訊被臨時儲存到Swap空間中,等到那些程式要運作時,再從Swap中恢複儲存的資料到記憶體中。系統總是在實體記憶體不夠時,才進行Swap交換。
你電腦打開了一個音樂播放器,但是也沒播放歌曲,然後你幾天不關機,也一直沒關閉這個音樂播放器,随着運作的程式越來越多,記憶體快不夠用了,是以作業系統就選擇将這個音樂播放器的記憶體狀态(包括堆棧狀态等)都寫到磁盤上的swap區進行儲存。這樣就騰出來一部分記憶體供其他需要運作的程式使用。你啥時候想聽歌了,就找到了這個音樂播放器程式操作。此時, 系統會從磁盤中的swap區重新讀取該音樂播放器的相關資訊,送回記憶體接着運作。
在window下也有類作用的硬碟空間,屬于對使用者不可見的匿名磁盤空間(在C槽)。
硬碟上的swap交換區,其實就相當于承擔了記憶體的作用(隻是速度很慢罷了)。swap交換區起到了擴大記憶體的作用。是以從某些意義上來講,swap區也可以叫做虛拟記憶體,但是這個虛拟記憶體是字面意思。和我們本文當中站在計算機系統的角度來解釋的虛拟記憶體不是一個概念。是以特别注意這一點。因為有些人了解的虛拟記憶體,就是swap互動區。此虛拟記憶體非彼虛拟記憶體,是以明白各自的概念和作用。不然和其他人讨論虛拟記憶體,可能出現驢頭不對馬嘴的情況。
linux環境下叫做swap分區,window下這塊區域沒叫做swap分區,就直接按照字面意思叫做"虛拟記憶體"了。是以兩個含義不同的虛拟記憶體,讀者一定要搞清楚了。
關于虛拟記憶體,看了百度百科的内容,有些地方解釋的比較混亂,有些地方是對的,但是有些地方解釋的是關于swap分區的内容。如果光從字面意思來看,swap交換區的确可以稱為虛拟記憶體,但是此虛拟記憶體非彼虛拟記憶體。百度百科關于這點的介紹比較混亂,百度百科的内容比較多,但是沒厘清這一點,隻會越來越混亂。我又查了維基百科的内容,該詞條内容不長,但是下面這段話很重要。
注意:虛拟記憶體不隻是“用磁盤空間來擴充實體記憶體”的意思——這隻是擴充記憶體級别以使其包含硬碟驅動器而已。把記憶體擴充到磁盤隻是使用虛拟記憶體技術的一個結果,它的作用也可以通過覆寫或者把處于不活動狀态的程式以及它們的資料全部交換到磁盤上等方式來實作。對虛拟記憶體的定義是基于對位址空間的重定義的,即把位址空間定義為“連續的虛拟記憶體位址”,以借此“欺騙”程式,使它們以為自己正在使用一大塊的“連續”位址。
是以我認為百度百科的解釋是混亂的,而維基百科上的應該才是正确的。
兩篇關于記憶體的文章都寫完了。因為本人才疏學淺,若有了解錯誤或解釋不清楚的地方,希望各位讀者打臉批評。
作者:
www.yaoxiaowen.com
部落格位址:
www.cnblogs.com/yaoxiaowen/
github:
https://github.com/yaowen369
歡迎對于本人的部落格内容批評指點,如果問題,可評論或郵件([email protected])聯系