前段時間看了 周志明的那本 《深入了解java虛拟機》。對于平台無關性問題,有了一些新的認識。是以特寫一篇部落格來進行總結。
這是我的第一篇不針對具體技術,而隻針對計算機系統和原理的部落格文章,而這種話題,總是比較寬泛,而我本人的水準有限,是以我也隻能泛泛的寫寫,思考的不對的地方,還望讀者不吝批評。
咱們先來讨論一下,C語言的執行過程,進而搞清楚為什麼C語言不能跨平台。
以上就是廣大人民群衆 都知道的<code>hello world</code>程式。最終執行的結果 就是在console上輸出一行字元串, <code>hello world!</code>。
大學時,譚浩強的C語言教材,<code>main</code>方法的傳回值是<code>void</code>,但這是錯誤的。實質上應該傳回<code>int</code>來告訴作業系統執行結果。(當然,後來學習的深入了,才知道譚的教材有不少錯誤的地方,但是我對這本教材依舊印象很好,因為那是我程式設計的啟蒙教材)。
我們知道,計算機隻認識0和1(就是二進制),換句話說,不管我們在計算機上幹了什麼事情,運作了多麼複雜的程式,從ps繪圖,到qq聊天,再到聽音樂,最終到了CPU的執行層面,其實就是 一串串的0和1組成的指令罷了。 當然,到了硬體層面,那就是與或非門的領域了。但是,上面的那個 <code>hello world</code>程式是怎麼轉換為0和1的呢。
一般情況下,對于我們使用的是 IDE,比如 Visual Studio, CodeBlocks之類的,就是點選個運作按鈕那麼簡單,或者你就是使用了gcc指令行來進行編譯,也可以一行指令 <code>gcc -o hello hello.c</code>,就 輸出了最後的編譯結果。但是實際上,<code>hello world</code>的編譯過程是這樣的:
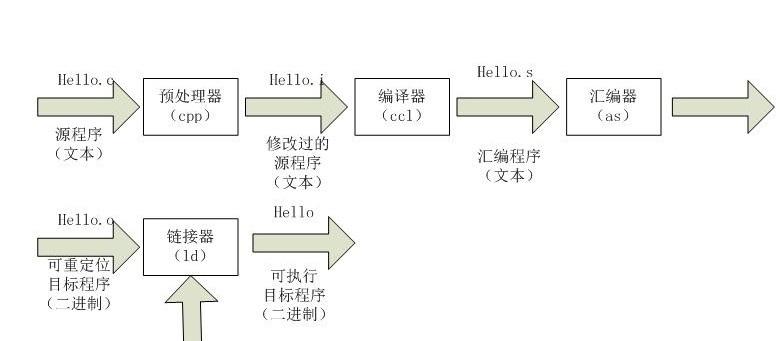
我們分階段來讨論:
預處理階段。預處理器(cpp)來把 代碼中<code>#</code>開頭的行進行展開, 比如頭檔案,宏等内容,修改最初的C檔案。
編譯階段。編譯器(ccl)将修改後的C檔案,翻譯成了 另一文本檔案,<code>hello.s</code>,這就是我們所說的彙程式設計式了。 打開這個文本檔案内容 類似下面的格式:
當然,不同CPU和平台環境,編譯輸出的彙編代碼也不同,我們這裡僅作為示例。
彙編階段。彙編器(as)将<code>hello.s</code>翻譯成機器語言指令。 把這些指令打包成一種叫做可重定位目标程式(relocatable object program)的格式,此時的輸出格式就是<code>hello.o</code>了。這其實就是二進制檔案了。
連結階段。編譯過程最後還有一個連結階段(程式調用了 <code>printf</code>函數),最後的輸出結果還是和上一步類似,都是直接二進制檔案。
了解了 <code>hello world</code>程式的編譯過程,我們就來讨論一下,什麼是<code>彙程式設計式</code>。我們先來看一下維基百科上的定義。(那個維基百科的連結,沒fan牆的同學應該是打不開的)。
彙編語言(英語:assembly language)是一種用于電子計算機、微處理器、微控制器,或其他可程式設計器件的低級語言。在不同的裝置中,彙編語言對應着不同的機器語言指令集。一種彙編語言專用于某種計算機系統結構,而不像許多進階語言,可以在不同系統平台之間移植。
什麼是彙編,相關專業的同學應該都明白,因為計算機隻認識0和1(就是二進制),是以在計算機剛開始發明時,那些科學家們就是直接 向計算機輸入0和1,來運作計算任務的。(當然,他們是通過穿孔紙帶的方式來向計算機輸入, 比如有孔代表1,沒孔代表0)。通過這樣的方式,計算機終于能運作了,但是這樣的效率實在太慢了。
而在他們輸入的0和1中,有些代表的是指令,這些是有固定含義和編碼的。也是晶片能識别的。而另一些是資料。這些不同的程式的資料自然是不同的。我們前面就說,不管多麼複雜的計算機操作,到了cpu級别都是0和1,資料雖然多變,但是 指令的數量是有限的。因為 指令是要被晶片固定識别的。晶片中要用 半導體(最初是電子管)組成的與或非門組合來識别這些指令和資料。因為直接輸入0和1,實在太繁瑣了,是以他們就發明了彙編語言。來簡化 程式的編寫。
比如 計算 1+1,兩個 資料1都 使用 <code>0x0001</code> 來表示,而 加操作,放在cpu中,可以是 <code>0xa90df</code>(這個是胡亂寫的),這個二進制代表的加操作能被計算機識别。而因為這個加操作對于cpu來說,編碼的<code>0xa90df</code>格式是固定的。是以可以直接一個助記符<code>add</code>來表示,這樣科學家們寫程式就友善多了,而這就是彙程式設計式的由來。因為彙程式設計式完成之後,可以再有一個專門的程式(就是要上文中所說的彙編器)來把編寫的彙程式設計式編譯成0和1.這樣計算機也可以識别了,而彙編語言本身也友善了程式的編寫和閱讀。
編寫彙編比直接編寫二進制友善高效了太多。但是 随着計算任務的複雜,程式的規模越來越龐大,使用彙程式設計式也很累啊,那麼是否有更簡單的方式呢?是以科學家們發明了進階語言(比如 <code>C</code>,<code>lisp</code>等),在編寫程式的時候,使用C語言等編寫,然後再使用 編譯器将C語言程式翻譯成彙程式設計式,彙程式設計式再使用彙編器編譯成0和1,這樣,cpu能識别的東西沒有變化,但是對于編寫程式的人,确實友善了很多。
通過以上的描述,我們就知道了進階語言的大概由來。也明白了我們所編寫的各種進階語言,到了最後,其實都是轉化為二進制執行。
而直接二進制格式的程式,我們稱之為本地機器碼(native code)。而類似那些 <code>add</code>之類的 助記符,以及彙編的編寫格式或标準,我們稱之為 指令集。
但是問題的關鍵來了。不同公司所生産的 cpu晶片。他們所使用的指令集不同啊, 這種晶片設計的事情,又不像TCP/IP協定那樣,有國際統一的标準,甚至像intel所代表的複雜指令集,和arm為代表的精簡指令集,它們指令集的設計思路就是不一樣的。
是以 我們C語言最後編譯出來的的二進制檔案,假設是這段<code>93034030930900090222ab2d11cd22dfad</code>(随便寫的),不同的cpu上識别的意義是不同的。
是以為什麼說C語言不能實作跨平台運作,就是因為它編譯出來的 輸出檔案的格式,隻适用于某種cpu,其他cpu不認識啊。
我們所說的跨平台運作,并不是指<code>hell.c</code>這個文本檔案的運作。因為文本檔案本身也沒辦法運作。運作的隻是它的編譯結果<code>hello</code>,而這個由0和1組成的編譯結果,不同的cpu和平台,他們的格式不同。是以<code>C</code>語言編譯出來的結果,沒辦法跨平台運作。
甚至在不同的平台下,<code>hello.c</code>最後所編譯出來的檔案的格式都不同。比如linux下編譯出的<code>hello</code>,window下編譯結果是<code>hello.exe</code>,而mac下編譯結果是<code>hello.out</code>,(至于單片機上編譯結果的字尾是啥子,這個忘記了)。
也有些人會講,為了讓linux下編寫的一段<code>hello</code>程式運作在<code>window</code>上,我不拿最後的編譯結果<code>hello</code>來直接運作,我在window環境下重新用IDE建立項目,同樣的源代碼在window下重新運作一遍,輸出<code>hello.exe</code>,再在window上運作,行不行啊?這個答案是No。因為不同環境下,c語言的标準有差别。例如 int類型,在有的平台上 可能16位表示,而有的平台上則是32位表示。是以不同環境下的同一個程式,會存在資料溢出之類的錯誤。
其實還有一點,大家平時寫個程式,IDE上點選個run/build之類的,稍等一會就輸出結果了,但是實際上,很多大型程式的編譯過程是比較長的,比如我第一家公司做手機系統的,編譯一個Android5.0的系統rom,在i7 cpu,16G記憶體的電腦上,需要編譯運作一個多小時,才能編譯成功輸出最後的結果。
知道了 C語言不能跨平台運作,那有沒有一種辦法,能夠 讓進階語言實作跨平台的運作呢?
思考實際程式設計中的一個場景,我們前端需要處理的某個資料是A格式,但是背景隻能提供B格式的資料,那我們怎麼辦?很簡單啊。寫個接口,把B格式轉化為A格式不就行了嘛。這就是設計模式當中的擴充卡設計模式。
關于跨平台也是一樣的道理。cpu的指令集不同, 不同平台編譯出來的結果格式都不同,那麼我們可以在各個平台上運作虛拟機,然後我們制定某種編譯結果的輸出格式,我們的輸出了某種格式的結果,直接在虛拟機上運作。這樣不就ok了嘛。。
這其實就是 java采取的方式。
這是java版本的<code>helloJava</code>;
這段java程式編譯出來的結果是 <code>helloJava.class</code>,換句話說,它輸出的結果是Class檔案格式(也叫位元組碼存儲格式)。
class檔案的内容大概就像下面那樣:

是不是看不懂?看不懂就對了。這其實就是java虛拟機定義的二進制格式,這種我們稱之為 位元組碼(ByteCode),是java虛拟機所能運作的格式。類似本地機器碼可以反編譯成彙編,這種二進制也可以反編譯成更容易閱讀的格式。
類似下面這樣。
而各個平台的java虛拟機 是不同的。但是我們編寫的java程式 統一編譯成特定格式的 Class檔案格式,然後Class檔案可以在各個不同平台的java虛拟機上運作,當然運作結果肯定也是一緻的,至于各個不同平台之間的差異,這是那些編寫java虛拟機的人去考慮的事情,我們這些做java的程式員,不用去關心這個問題。
通過這種方式,我們的java程式就實作了跨平台。
是以java也被稱為 中間件技術語言。意思就是 中間加一層過度。很好了解。(當然,維基百科上對中間件技術的解釋,基本把我看暈了,也和java沒關系,不過大家了解這個意思就好)。
而通過java虛拟機和Class檔案格式,我們就實作了平台無關性,換句話說,這些适應各個不同平台和cpu的工作的還是要有人幹的。那就是設計java虛拟機的人去做這些工作,但是他們的辛苦換來了我們上層程式員的輕松。我們就完全不關心各個平台和cpu的差異了。
雖然說名字是 ByteCode,但是我覺的,其實和 NaticeCode 都差不多,反正都是定義了一套指令集,隻是前者能被虛拟機執行引擎去執行,而 後者能被實體機的CPU去執行罷了。
知道了大概的原理,我們就思考另一個問題,java虛拟機去執行Class檔案,那和java的源檔案 有什麼關系呢。答案是 沒關系。換句話說,java的源檔案編譯的輸出結果為Class檔案,而Class檔案能被java虛拟機認識,并執行,這是兩個獨立的過程,中間也沒啥關系和必然性。
那麼進而引申出另一個問題,某一種其他程式設計語言,如果我設計出了一種對應的編譯器,将其編譯輸出結果為Class檔案,那這樣該語言豈不是也實作了跨平台了?
想到這一點,那麼恭喜你,你發現了 java虛拟機的另一種 重要特性。語言無關性
java虛拟機在執行Class檔案時,不知道也完全不關心這個Class檔案是咋來的。(這個Class檔案可以是任何一種語言的源檔案編譯而來,當然,就像直接編寫彙編一樣,你直接編寫 ByteCode也行,隻要格式正确)。
其實CPU在執行二進制的指令時,它不知道也完全不關心這些指令流是咋來的。這都是同一個道理。
很多程式員都還認為Java虛拟機執行Java程式是一件理所當然和天經地義的事情。這是錯誤的。
下面某些内容 援引 周志明的 《深入了解java虛拟機》:
Sun的開發設計團隊在最初設計的時候就把Java的規範拆分成了Java語言規範《The Java Language Specification》及Java虛拟機規範《The Java Virtual Machine Specification》。
并且在1997年釋出的第一版Java虛拟機規範中就曾經承諾過:“In the future,we will consider bounded extensions to the Java virtual machine to provide better support for other languages”(在未來,我們會對Java虛拟機進行适當的擴充,以便更好地支援其他語言運作于JVM之上)。
實作語言無關性的基礎仍然是虛拟機和位元組碼存儲格式。Java虛拟機不和包括Java在内的任何語言綁定,它隻與“Class檔案”這種特定的二進制檔案格式所關聯,Class檔案中包含了Java虛拟機指令集和符号表以及若幹其他輔助資訊。基于安全方面的考慮,Java虛拟機規範要求在Class檔案中使用許多強制性的文法和結構化限制,但任何一門功能性語言都可以表示為一個能被Java虛拟機所接受的有效的Class檔案。作為一個通用、機器無關的執行平台,任何其他語言的實作者都可以将Java虛拟機作為語言的産品傳遞媒介。
換句話說,java虛拟機這個名字其實隻是一個誤導,java虛拟機和java沒啥關系,其實更應該叫做 Class檔案虛拟機。
因為其他語言, 隻要有對應的編譯器,輸出結果就可以運作在java虛拟機上,是以時至今日,湧現Clojure、Groovy、JRuby、Jython、Scala一批運作在java虛拟機上的語言。
目前下圖中的語言都已經可以運作在java虛拟機上。
是以廣義上的java技術體系,也包括Clojure、JRuby、Groovy,Scale等運作于Java虛拟機上的語言及其相關的程式。
Java,Scale等各種語言中的各種變量、關鍵字和運算符号的語義最終都是由多條位元組碼指令組合而成的,是以位元組碼指令所能提供的語義描述能力肯定會比單一語言本身更加強大。
當然,在java最初剛出現的時候,Write Once,Run Anywhere, 這種 平台無關性被吹噓的比較厲害,但是現在 這種虛拟機的思想,被很多其他語言也學會了,比如python和pvm。go語言,.NET等都是同樣的思想。
關于java虛拟機和Class檔案格式, 貌似很厲害的樣子,什麼 個人一小步,人類一大步都扯上了,那肯定有人疑問,為什麼 c/c++這些不能跨平台的語言,還現在還被很多人使用,還沒被java取代呢。
當然,這個原因有很多,比如java的gc過程所無法避免的stop the world過程,這在 某些實時性要求比較高的 系統中,比如 股票交易系統,軍事系統,是不可接受的。(關于垃圾回收這是另一個話題,不在本文範圍内,未來有時間可以花時間另寫部落格讨論這個問題)。
不過有句話說的很好
java和c++之間有一堵由動态記憶體配置設定和垃圾收集技術所圍成的'高牆',牆外的人想進去,牆内的人想出來
另外,對于直接與硬體互動的事情,也隻能靠C語言了。畢竟上層再怎麼發展,硬體與系統之間永遠要存在一個驅動層啊。
但是除了以上這些,還有一個原因。給大家講講軟體曆史上的一個重大教訓,大家也許就明白了。
當年為了對抗sun的java平台,微軟2002年推出了類似中間件思想的.NET平台(C#)。當時window xp一統江湖,讓微軟如日中天,不可一世,微軟在下一代作業系統(就是window visa)的開發中,決定使用 C#, 雖然微軟牛逼哄哄,擁有最牛逼的程式員,最頂尖的科學家,但是開發到最後他們發現,使用C#這種運作在虛拟機上的中間件語言,無論如何也達不到 C/C++語言的速度。是以最後悲劇的 window visa,全部推倒重來,重新開發。當時李開複在微軟,他的一本書中對此有詳細介紹。
當然,當年window visa項目的失敗,還有其他一些原因,比如 使用資料庫系統代替檔案系統,驅動不相容等, 但是 使用.NET來進行開發,起碼也是失敗的主要原因之一。
是以現在大家明白了,ByteCode運作在虛拟機上,相比于直接編譯成 NativeCode 運作在實體機上,速度較慢。
現在随着虛拟機運作時優化技術的發展,以及硬體的速度越來越快,是以它們速度之間的差異,也沒之前差距那麼大了。
實質上,Class檔案在虛拟機上運作的時候,還會有很多的優化措施。
在部分的商用虛拟機中,Java程式最初是通過解釋器(Interpreter)進行解釋執行的,當虛拟機發現某個方法或代碼塊的運作特别頻繁時,就會把這些代碼認定為“熱點代碼”(Hot Spot Code)。為了提高熱點代碼的執行效率,在運作時,虛拟機将會把這些代碼編譯成與本地平台相關的機器碼,并進行各種層次的優化,完成這個任務的編譯器稱為即時編譯器(Just In Time Compiler,簡稱JIT編譯器)。
許多主流的商用虛拟機都同時包含解釋器與編譯器。解釋器與編譯器兩者各有優勢:當程式需要迅速啟動和執行的時候,解釋器可以首先發揮作用,省去編譯的時間,立即執行。在程式運作後,随着時間的推移,編譯器逐漸發揮作用,把越來越多的代碼編譯成本地代碼之後,可以擷取更高的執行效率。當程式運作環境中記憶體資源限制較大(如部分嵌入式系統中),可以使用解釋執行節約記憶體,反之可以使用編譯執行來提升效率。
但是實際上,編譯器可以把java源檔案的輸出結果編譯成Class格式(也就是 ByteCode),那自然也可以有其他類型的編譯器 可以直接将java源檔案編譯為NativeCode啊。是以對于程式設計語言來說,我們可以有各種方式來編譯它,Java語言的“編譯期”其實是一段“不确定”的操作過程。因為我們可以使用不同類型的編譯器編譯出不同的輸出結果。
java常見的編譯器有以下類型。
前端編譯器:把.java檔案轉變成.class檔案。比如Sun的Javac、Eclipse JDT中的增量式編譯器(ECJ)。
JIT編譯器:位元組碼(ByteCode)轉變成機器碼(NaticeCode)。比如HotSpot VM的C1、C2編譯器。
AOT編譯器:直接把*.java檔案編譯成本地機器代碼。 比如GNU Compiler for the Java(GCJ)、Excelsior JET。
是以讨論到最後,大家就已經明白,是以平台無關性,與 編譯器與編譯輸出結果格式 的關系。花了一天時間寫了這麼多内容,也希望給大家帶來一些啟發。
在本篇部落格當中,很多内容也并不是精确的分析,比如某些概念,都說的比較模糊,因為我們這片部落格隻是讨論思想。很多概念和過程也都沒有去深究, 如有錯誤不準确的地方,歡迎指正。
非常感謝大家對這篇文章的支援,能夠對其他人有所幫助,獲得大家的認可。更加提升了我堅持寫部落格的動力。
針對評論中的問題,也進行一些解答。
如文章末尾所說,我本來就是寫大概思想,是以很多細節沒有深入去追究,其實比如像彙編的格式,指令集的執行等,其實這些讨論起來真心複雜,牽扯到cpu的結構設計等。今後也計劃寫文章和大家讨論這些問題。
評論中倒沒有人指出這方面的問題,不過我大學時本來就是做C語言和單片機的,明白這方面介紹的依舊不夠準确和詳細。(當然,很多細節我也忘記了)
評論當中有人提到.NET的虛拟機的問題,首先因為我本身是Android程式員,大學時期也做過C語言,單片機等,是以對java,C等算是了解一些,但是對.NET的确不了解。對.NET有限的知識,也來源于和做.NET的朋友的讨論交流。是以關于.NET思想的評價可能不夠準确。
評論中有人提出了以下問題:
wdwwtzy 評論: 那我想問問,.net 也是 java 一樣的虛拟機技術,為什麼早期.net 無法跨平台? 隆德爾評論:樓主,據我所知,java與.net,此虛拟機非彼虛拟機。而且這個問題一直被很多javaer所混淆。 wdwwtzy評論:啥意思,看文章的意思,java 一出生不就是真正的跨平台了嗎?
有些同學直接評論做了相關解答,對此深表感謝。寫部落格本來就是一個互相讨論互相促進的過程,是以感謝各位的解答。
WindyAmy評論:.net CLR/.net framework 和window系統結合的太緊密導緻。現在微軟重寫了部分framework庫(.net core),已經可以實作誇平台了。 Blackheart評論:因為沒有人在其他平台實作.net 的clr啊,後來有了mono,可以跨平台了。沒有真正意義上的跨平台,對于開發者而已,可能你不需要關心作業系統是windows還是linux了,你感覺是跨平台了。但是底層總有這麼一幫人在幫你搭建支撐“跨平台”的基礎設施的,對于他們來說,一個個的平台都需要單獨去實作的。**
幾位解答的同學說的都已經非常好了,本人結合評論,也google了一些相關知識。再對.NET的相關問題寫出我的了解。以期抛磚引玉。
可以确定是,.NET和java虛拟機也是一樣的思想,都是引入中間層/虛拟機的思想。做java的同學說java虛拟機(JVM),而微軟的.NET的虛拟機的名稱叫做通用語言運作平台(Common Language Runtime,簡稱CLR)。雖然有些同學可能認為CLR不叫虛拟機,但是歸根到底,它還是廣義的虛拟機的概念和思想。
Clojure、Groovy、JRuby、Jython、Scala等很多語言都可以運作在JVM上。而 CLR也是一樣的,C#、F#、VB.NET、C++、Python等幾十種語言也可以運作在CLR上。
java,Scala等編譯結果為ByteCode(位元組碼),被稱之為Class檔案格式運作在jvm上,而jvm在運作Class格式檔案時,可以解釋運作,也可以通過JIT編譯器編譯成NativeCode加快運作。而C#,C++等編譯成 通用中間語言(Common Intermediate Language,簡稱CIL),然後再彙編成位元組碼,(當然這個位元組碼肯定不會是Class檔案格式,但是概念相同),而在運作時,也是翻譯成本地機器碼運作(但是CLR貌似沒有解釋運作,這點求相關同學解答,我估計應該也有類似javascript的解釋運作方式,不過沒查到相關資料)。
大家知道,我們要想在某個平台上運作java開發的項目,必須要安裝jdk,這個過程還是很麻煩的,要設定環境變量之類的。這對于普通使用者來講是不可能完成的操作。而.NET其實也是需要安裝環境的(叫做 .NET framework),但是window就是微軟自家的,是以window系統内置了.NET framewok。(win7自帶.net3.5版本,win10自帶4.0版本),是以window上本來就可以運作.NET的程式。省去了普通使用者安裝.NET framework的麻煩。
但是微軟肯定不會為window内置jdk的,原因太簡單了,如果window也都内置了jdk,而其他的linux,mac等作業系統也都進行内置,那麼各個開發應用/遊戲的廠商們,直接使用java開發就好了,然後開發出來的産品直接window/linux/mac所有系統平台上都通用,廠商們開心了,消費者也開心了,那這個時候,我們為什麼還要使用window作業系統呢?反正對于普通消費者而言,使用應用或玩遊戲都是沒啥差別的。
(是以這也是為什麼java在pc端應用/遊戲領域沒人使用,而伺服器端使用java的多,因為開發伺服器的碼農們搭配java環境很easy啊)
回想一下 window與Netscape的浏覽器大戰,如果使用浏覽器就能幹大部分事情,那麼大家根本就不關心運作浏覽器的作業系統是window還是linux了。當然,現在網際網路的流量/入口之争其實都是同一個道理。普通消費者哪裡關心那麼多,哪個好用,哪個便宜就用那個。
2014年11月12日,微軟宣布将完全開放.NET架構的源代碼,并提供給Linux和OS X使用。
首先本部落格當中非常清晰的表達了這個觀點,什麼跨平台不跨平台,适應各個平台/CPU的差異,這種髒活累活永遠也得有人幹,隻是那些 去做虛拟機的人幹了這種活,我們這種純粹寫上層的人輕松了而已。
是以我覺的很多時候,能不能跨平台,除了技術問題,還要有商業原因,甚至也有money的問題(畢竟開發各個平台的虛拟機也是不易)。就像 .NET理論上跨平台,但是不開源,幾年前微軟又不肯為.NET提供linux環境下的實作。那麼自然沒辦法跨平台,但是這和技術無關。
java最初設計時,理論上就可以跨平台,但是那些苦逼的虛拟機開發者們還要去開發各個平台/cpu的虛拟機,這也不是一朝一夕之功。
微軟現在可以讓.NET跨平台,一來大的形勢變了(之前的作業系統賣的那麼貴,現在win10都可以免費了),二來微軟對.NET有控制權。而在java剛出來的時候,微軟也支援java,也設計過微軟版本的jvm。但是微軟是想擁有對java技術體系的控制權,但是發現搞不過sun之類的,java不在它的控制之下,是以微軟就開始搞自己的.NET平台了。
也許Java程式員聽起來可能會覺得驚訝,微軟公司曾經是Java技術的鐵杆支援者(也必須承認,與Sun公司争奪Java的控制權,令Java從跨平台技術變為綁定在Windows上的技術是微軟公司的主要目的)。在Java語言誕生的初期,微軟公司為了在IE3中支援Java Applets應用而開發了自己的Java虛拟機,雖然這款虛拟機隻有Windows平台的版本,卻是當時Windows下性能最好的Java虛拟機。但好景不長,在1997年10月,Sun公司正式以侵犯商标、不正當競争等罪名控告微軟公司,在随後對微軟公司的壟斷調查之中,這款虛拟機也曾作為證據之一被呈送法庭。這場官司的結果是微軟公司賠償2000萬美金給Sun公司(最終微軟公司因壟斷賠償給Sun公司的總金額高達10億美元),承諾終止其Java虛拟機的發展,并逐漸在産品中移除Java虛拟機相關功能。具有諷刺意味的是,到最後在Windows XP SP3中Java虛拟機被完全抹去的時候,Sun公司卻又到處登報希望微軟公司不要這樣做。Windows XP進階産品經理Jim Cullinan稱:“我們花費了3年的時間和Sun打官司,當時他們試圖阻止我們在Windows中支援Java,現在我們這樣做了,可他們又在抱怨,這太具有諷刺意味了。”
這個故事告訴我們一個道理:早知今日,何必當初呢。
本篇部落格補充了以上内容,謝謝大家,歡迎指點批評。
如果大家能對我的文章推薦一下,關注一下本人部落格,那就更開心了,我今後也會更多的寫一些計算機系統/原理類的文章,以飨各位讀者。再次謝謝。
作者:
www.yaoxiaowen.com
部落格位址:
www.cnblogs.com/yaoxiaowen/
github:
https://github.com/yaowen369
歡迎對于本人的部落格内容批評指點,如果問題,可評論或郵件([email protected])聯系