首先給大家講個段子:
2015年開網吧,買了 DDR4 8g 記憶體條400多根,一根180塊,今年2017年,網吧賠了20多萬,昨天我把網吧電腦全賣了。記憶體條600一根,居然賺回了我網吧的錢,感謝三星,感謝人民,感謝黨。。。
今年以來,記憶體條價格暴漲,已經躍升為新的新一代理财産品,是以今天就和大家讨論一下記憶體的話題,主要内容就是在程式運作過程中,記憶體的作用以及如何與CPU,OS互動。
我們先來讨論:計算機的運作究竟是在做什麼?來看一下經典的馮諾依曼結構。計算機科學雖然飛速發展了幾十年,但是依舊遵循馮諾依曼結構。
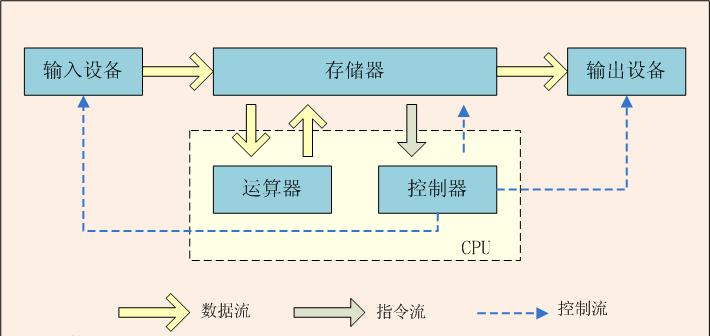
圖1:馮諾依曼結構
數學家馮諾依曼提出的 體系結構包含以下幾個要點:
把程式本身當作資料來對待,程式和該程式處理的資料用同樣的方式儲存。 計算機的數制采用二進制。 計算機應該按照程式順序執行。
我們根據這張圖進行思考就可以得到一個結論,所謂計算機處理任務,就是根據輸入内容,資料/程式從存儲器送往CPU進行處理,然後再将結果輸出。
關于程式與資料,資料就是一首MP3歌曲, 程式就是用來控制解析播放這首歌的代碼,從底層來講就是供CPU運作的指令.總之在計算機當中它們都是0和1,不過為行文友善,我們直接簡稱為資料或程式或指令, 将它們了解為同一個意思,畢竟它們都屬于0和1組成的流,這個可以根據上下文來了解。
本文讨論的主要内容,就是 存儲器部分,為什麼計算機需要存儲器部分?這是顯而易見的,我寫好了程式,或者下載下傳了一部電影,肯定得有個地方放啊。這樣今後需要的時候,才能運作程式或者看電影啊。
我們思考一下,這個存儲器應該具備什麼樣的特點。
1.穩定,掉電不丢失資料:這個道理上面已經提過,辛辛苦苦下載下傳個小電影,一關電腦資料都丢失了。這肯定不行的。
2.存儲容量大:就像誰也不嫌棄自己錢多,嫌棄自家房子太大。我們既然存儲東西,那麼容量肯定越大越好。
3.讀寫速度快:拷貝個電視劇,速度那麼慢,真心累啊。
4.價格便宜:新釋出的iphone x我為啥不買,因為它有一個缺點我無法接受,那就是太貴了。一台電腦賣一百萬,我們誰又能買得起呢?
5.體積小:這個也是理所當然的。
關于這個存儲器,我們大概想出了一個理想的存儲器應該具備的的5個特點。
但是有句話說的好。理想很豐滿,顯示很骨感。一個屌絲在紙上列出了幾十條他理想女友的标準,但是他能如願嗎?
先說結論,完全滿足我們理想條件的存儲器目前還沒發明出來呢。目前的半導體工業隻能造出部分符合條件的存儲器,但是完全滿足以上幾條标準的,對不起,未來也許能做到,但是起碼目前做不到。
是以這也是目前計算機系統存儲器系統比較複雜的原因,區分為記憶體,硬碟,CD光牒等不同的存儲器,如果有個完美的符合我們理想條件的存儲器,直接使用這種存儲器就好了。
先看看看我們最常見的儲存設備:磁盤。足夠穩定;有電沒電都正常存儲;容量也較大;價格也可以接受,是以磁盤是我們最常見的儲存設備。
磁盤就是我們存儲器的代表了。
為了行文友善,文中直接将存儲器用磁盤來代替了,一來大家對磁盤比較熟悉,二來磁盤也是最常見的儲存設備。類似flash,SD卡,ROM等從廣義上來講,也可以稱為磁盤。因為它們的作用都是存儲資料,掉電後不丢失。(這在下面文章中也會讨論到)
磁盤和硬碟什麼關系呢?其實是同一個意思。硬碟是最常見的磁盤類型。在很早之前,計算機使用軟碟存儲資料,是以那種軟碟也被稱為 磁盤,不過軟碟都早就被曆史淘汰了,(電腦硬碟分區從C槽開始,就是因為AB盤是之前軟碟的編号)。是以現在我們說磁盤,直接了解成硬碟就好了。
在我們軟體當中,有個概念叫做資料持久化,意思就是說将資料存儲起來,掉電之後不丢失,這其實就是存儲在磁盤上面。
是以現在我們了解的計算機運作就是這樣一個過程:将資料從磁盤送往CPU,供CPU進行計算,并将結果輸出。
因為我們這片文章就是 讨論 記憶體,存儲等問題,是以關于 輸入裝置,輸出裝置之類的,就不再涉及和讨論。
然後我們再簡短來讨論CPU的發展曆史。
世界上第一台計算機是1946年在美國誕生的ENIAC,當時CPU還是使用笨重的電子管,後面的故事依次是貝爾實驗室發明了半導體,TI的工程師又發明了內建半導體,IBM研發成功首款使用內建電路的計算機,IBM360, 後面 就是仙童八叛徒與intel,AMD的故事了。這段很著名的IT故事,我們不再累述了。伴随着世界上第一款商用處理器:Intel4004的出現,波瀾壯闊的摩爾定律開始了。
當時負責IBM 360 作業系統開發的那個項目經理,根據該項目經驗, 寫了一本經典著作《人月神話》,也有其他參與者根據該項目經驗,立傳出書了,是以當時那批人都是大牛。
摩爾定律:當價格不變時,內建電路上可容納的元器件的數目,約每隔18-24個月便會增加一倍,性能也将提升一倍。
半導體行業開始騰飛了。CPU上內建的半導體數量越來越多。 intel i9的制程工藝已經到了14nm。是以CPU的執行速度也越來越快。
當然,摩爾定律也快到盡頭了,根據量子力學,2nm是理論極限值。線寬不能再細了,低于2nm,隧穿效應就會産生幹擾。
閑扯了一段CPU的發展曆史,想說明的是,現在的CPU內建度越來越高,速度也越來越快。每秒鐘能執行的指令也越來越多。(如果不知道指令,彙編之類的啥意思,看一下我的的另一篇文章關于跨平台的一些認識,否則下面的内容看着也有難度)。
CPU的作用就是去執行指令(當然,也包括輸出結果等,本文隻讨論和存儲器相關,是以不扯其他的),并且盡可能的以它的極限最高速度去執行指令,至于具體的執行過程,做過單片機或者學過微機原理的應該比較清楚。就是伴随着時鐘周期滴滴答答的節奏,CPU踏着拍子來執行指令。
至于CPU的指令集,那就是Intel的架構師們的工作,總之,CPU認識這些指令,并且能執行運算。(别忘記了馮諾依曼體系結構那張圖)。對于這些指令,但是CPU采取了各種措施來加快執行過程(也可以了解為加快它的計算速度)。比如有以下幾種常見的措施:
流水線(pipeline)技術:有電子廠打工經曆的讀者肯定很熟悉這個流水線模式。CPU的流水線工作方式和工業生産上的流水線概念一樣。就是将一個指令的執行過程也分解為多個步驟,CPU中的每個電路隻執行其中一個步驟,這樣前赴後繼加快執行速度。CPU中多個不同功能的電路單元組成一條指令處理流水線,然後将一條指令分成幾個步驟後再由這些電路單元分别執行。在執行過程中,指令源源不斷的送往CPU。讓每個電路單元都不閑着,這樣就大大的加快了執行速度。
超線程(Hyper-Threading)技術:對于超線程,百度百科的解釋我都沒看懂,但是大概原理就是這樣的。CPU在進行線程切換的時候,要執行 切換各種寄存器狀态等一些操作。把第一個線程的各種寄存器狀态寫回緩存中儲存,然後把第二個線程的相關内容送到各種寄存器上。該過程必不可少,否則待會再将第一個線程切換回來時,不知道該線程的各個狀态, 那還怎麼接着繼續執行呢?也正因為如此,是以這個過程比較慢,大概需要幾萬個時鐘周期。是以後來做了這樣的設計,把每個寄存器等都多做一個,就是多做一組寄存器(也包括一些其他相關電路等),,CPU在執行A線程時,使用的第一組寄存器,切換到B線程,直接使用第二組寄存器,然後再切換A線程時,再使用第一組寄存器。,CPU就不用再傻傻的等着寄存器值的切換,線程切換隻需要幾個時鐘周期就夠了。對于普通的執行多任務的計算機,CPU線程切換是個非常頻繁的操作,是以使用該技術就會節省大量的時鐘周期。也就是相當于加快了CPU的執行速度。這就是CPU宣傳參數中所謂的四核八線程的由來,其實就是超線程技術。(每個核多做一組寄存器等電路固然會占用寶貴的空間,但是它帶來的優點遠遠大于缺點)。
超标量技術:CPU可以在每個時鐘周期内執行多個操作,可以實行指令的并行運算。
亂序執行: 我們認為程式都是順序執行的。但是在CPU層面上,指令的執行順序并不一定與它們在機器級程式(彙編)中的順序一樣。比如 <code>a = b+c; d++;</code>這兩個語句 不按照順序執行也不會影響最終結果。當然這隻是在CPU執行指令的層面,在程式員們看來,依舊認為程式是順序執行的。
前面扯了那麼多,就是為了說明CPU的執行速度很快。雖然每條指令的執行時間需要幾個時鐘周期到幾十個時鐘周期不等。但是CPU采用了種種技術來加快執行過程。是以平均執行一條指令隻需要一個周期。而現在CPU主頻都那麼高。比如i7 7700K主頻達到了 4.2G。這也就意味着,每個core每秒鐘大約可以執行4.2億條指令。那四個core呢?
我們讨論完CPU如此快的執行速度,我們再來說我們常見的儲存設備-機械硬碟。

圖2:機械硬碟結構
機械硬碟的結構就不再具體的讨論了。它讓我想起了民國電影中那種播放音樂的唱片機。
帶機械硬碟的電腦,在使用過程中,如果機箱被摔了,可能後果很嚴重,就是因為可能會把機械硬碟的那個讀寫頭/傳動臂等機械結構摔壞。
機械硬碟容量很大(目前普遍1T,2T),我們的資料和程式是存儲在磁盤上的,是以CPU要想執行指令/資料,就要從存儲器,也就是磁盤上讀取, CPU一秒鐘可以執行幾億條指令,但是相對之下,磁盤的讀寫速度就是慢如蝸牛。假設磁盤一秒鐘可以讀取100條指令。那麼這中間就存在 巨大的速度差異。半導體行業發展了幾十年,CPU的執行速度一再飛速提升,奈何磁盤技術發展的太不給力了,CPU再快,可是磁盤嚴重拖後腿,那CPU就相當于工作嚴重不飽和,如果直接從磁盤上 來讀取資料,那麼CPU相當于 99.9999%的時間都在閑置着。
"假設磁盤一秒鐘可以讀取100條指令。":帶有假設字樣的,具體數字都是随便寫的。比如 磁盤讀寫速度自然有它的參數名額,不過我們隻是為了說明問題, 是以能了解其中的道理就好。
磁盤廠商們也在努力研究,比如SSD(固态硬碟),它的速度就比 機械硬碟快了一二十倍吧。但是對于CPU的速度,這也是然并卵啊。(更何況SSD相比機械硬碟太貴了)
是以這就是個大問題。
這就像是老闆對我們這些員工的希望一樣。老闆給我們發工資, 那麼他就是希望我們每一天的每一分每一秒都在努力幫公司幹活。不要有什麼任何時間閑着。是以我們要感謝勞動法,讓我們每天工作八小時就夠了。畢竟我們也是血肉之軀,也需要吃喝拉撒睡覺。
看到勞動法說每天工作八小時就夠了,程式猿們哭暈在廁所。
程式猿問科比:“你為什麼這麼成功? ” 科比:“你知道洛杉矶淩晨四點是什麼樣子嗎? ” 程式猿:“不知道,一般那個時候我還沒下班呢,怎麼了?” 科比:“額…….”
通過上面的介紹,我們就明白了計算機體系的主要沖突,CPU太快了,而磁盤太慢了。是以它倆是不能夠直接通信的,我們可以加一層過度。這就是記憶體的作用。這就是幾百塊錢一根的記憶體條的作用和功能。
實際上,一般情況下,記憶體的讀寫速度比磁盤快幾十萬倍左右。是以它終于夠資格和CPU直接通信了。
這裡有張圖,我們來看一下磁盤/記憶體,與CPU速度之間逐漸增大的差距(主要是CPU技術發展太迅猛了)。
圖三:磁盤DRAM和cpu速度之間逐漸增大的差距
是以現在程式執行過程是這樣的。CPU執行任務時,隻與記憶體通信,它從記憶體擷取指令/資料或寫回資料。記憶體再與磁盤通信,記憶體從磁盤讀取資料/指令,或者記憶體将資料寫回磁盤。
提到添加過渡層。這其實和JVM的原理都是類似的。具體可參考我的另一篇文章關于跨平台的一些認識。也許這就是大道至簡吧。
我們這裡說的記憶體,主要是指主存。就是主機闆上插的記憶體條。它的讀寫速度比磁盤快了幾十萬倍。但是相對于CPU的速度依舊還是慢。那麼主存和CPU之間,可以繼續添加速度更快的過度層。是以intel i7的存儲器層次結構是這樣的。
圖4:一個存儲器層次結構的示例
前面扯了那麼多篇幅,就是告訴你,我們為什麼需要記憶體(主存),那麼了解了主存,自然也就了解了L3,L2,L1等各級緩存存在的意義。對于現代的計算機系統,在CPU與磁盤/主存之間,加了多層過度層。
嚴格來講,應該叫CPU的算術邏輯單元(ALU),但是簡單的直接說CPU,大家肯定也能聽得懂。
實際上這是一種緩存思想。比如,本地磁盤也相當于 遠方伺服器的緩存。因為我們從網上下載下傳資料/檔案時,速度明顯比從本地磁盤讀取要慢。
一般情況下,L5磁盤與L4主存速度相差幾十萬倍, 而L3-L0之間,它們每級緩存的速度差異大概是10倍。
我們是拿i7處理器來做例子,它有三級緩存,像低端一些的處理器,比如i3,隻有兩級緩存,但是道理是相同的。本文當中,都是拿i7的存儲器層次來做例子。
明白一點。CPU執行速度實在太快了,一秒鐘執行幾億/十幾億條指令,CPU幹活幹脆利落,那麼存儲器就要想方設法的用最快的速度把指令/資料 送給CPU去運作。否則CPU幹活再快,又有什麼意義呢。
基本思想已經了解了。那麼我們就開始具體讨論細節問題。
看看上面那幅圖,什麼SRAM,DRAM,還有我們前面講的SSD,Flash,機械硬碟等,還有下面要讨論的總線(BUS),是以我們先來讨論一些基礎硬體知識.
首先,他們都屬于存儲器,存儲器分為兩類:
易失性(volatile)存儲器:包括記憶體,SRAM,DRAM等,特點是讀寫速度很快,掉電了資料會丢失,價格貴,并且存儲容量較小。
非易失性(nonvolatile)存儲器:包括磁盤,Flash,CD光牒,機械硬碟,SSD等,與易失性存儲器相比,它們讀寫速度很慢,但是掉電不丢失資料,存儲容量比較大,價格也便宜。
RAM(Random-Access Memory):随機通路存儲器。易失性存儲器。也可以通路兩類:SRAM(靜态的)和DRAM(動态的),并且SRAM的讀寫速度比DRAM更快,價格也更貴。在上圖中也可以看到, SRAM做L1-L3級緩存,而DRAM做L4級的主存。
ROM(read-only memory):隻讀存儲器,非易失性存儲器。這個名字容易讓人産生誤解,它既可以讀,也可以寫,稱之為read-only隻是曆史原因。
ROM相比于RAM,容量更大,價格便宜,讀寫速度則比較慢。
閃存(Flash memory):非易失性存儲器。SSD,SD卡都屬于Flash技術,如果從概念上來講,他們都屬于ROM,這類存儲器經常用在手機,相機等裝置上。而機械硬碟常用在個人計算機,伺服器上。
其實我覺的把 Flash,ROM等都叫做磁盤,也沒什麼錯。畢竟它們的作用和概念都是相似的,差別隻是他們各自使用的半導體技術不同。Flash晶片等基于內建晶片的存儲器讀寫速度比機械硬碟快,不過(相同容量下)價格也比後者貴。而它們相比于SRAM,DRAM則非常慢了,是以後者了解為記憶體即可。
"圖4:一個存儲器層次結構的示例",越往上,讀寫速度越快,價格更貴,存儲容量也越小。(淘寶上搜搜8G的記憶體條,256G的SSD,1T的機械硬碟都是什麼價格就明白了)。像L0 寄存器,每個寄存器隻能存儲一個字長的内容,但是CPU讀寫取寄存器耗費的時鐘周期為0個。這是最快的速度。
另外,我們在電腦主機闆上可以看到記憶體條(L4主存)。硬碟(L5),但是卻沒看到L3-L0。原因很簡單,他們都是內建在CPU晶片内部的。
我們知道了存儲器的層級結構,下面還有一個問題,就是怎麼把硬碟,記憶體條之類的連接配接起來進行通信呢,這就是 總線(Bus)了。
圖6:一個典型系統的硬體組成
上圖存在三條總線,IO總線,存儲器總線(通常稱為記憶體總線),系統總線。在主機闆上,就是那一排排的32/64根并行的導線。這些導線用來連接配接CPU,記憶體,硬碟,以其他外圍裝置。CPU與存儲器,輸入輸出裝置等通信,都是通過總線。不同總線的速度也有差異。
CPU要通過I/O橋(就是主機闆的北橋/南橋晶片組)與外圍裝置連接配接,因為CPU的主頻太高了,它的時鐘周期一秒鐘震蕩幾億次,外圍裝置的時鐘周期都較慢,是以他們不能直接通信。
本文是讨論軟體的,是以硬體部分就一筆帶過,讀者知道有這回事就ok了。總線上攜帶位址,資料和控制信号, 如何區分不同信号,分辨它與哪個外圍裝置通信,這就是另外一個問題了。
有些讀者腦子轉的比較快,可能想到了這樣一個問題。
不管你中間怎麼加緩存,也不管中間的什麼SRAM,DRAM的讀寫速度有多快,但是磁盤的讀寫速度就是那麼慢,是以磁盤與主存之間的互動速度很慢。CPU歸根到底需要向磁盤讀寫資料。整個環節速度瓶頸就是在磁盤那裡,這個根本快不了,那麼加那麼多級緩存,意義有何在呢?
這是一個好問題啊。 下面讓我們繼續讨論。
我們來看看,CPU如何讀取磁盤中的一個資料。
圖7:讀一個磁盤扇區
網上找的圖檔不是很清楚,注意每張圖中的黑線。步驟分三部:
CPU 将相關的指令和位址,通過系統總線和IO總線傳遞給磁盤,發起一個磁盤讀。 磁盤控制器将相關的位址解析,并通過IO總線與記憶體總線将資料傳給記憶體。 第2步完成之後,磁盤控制器向CPU發送一個中斷信号。(學電子的同學應該很清楚中斷是什麼)。這時CPU就知道了,資料已經發送到記憶體了。
第二步磁盤操作很慢,但是在第一步CPU發出信号後。但是第二步和第三部時,CPU根本不參與。第二步很耗時,是以CPU在第一步發出信号後,就去在幹其他事情啊。(切換到另一個線程)。是以此時的CPU依舊沒有閑着。而待第三步時,通過中斷,硬碟主動發信号給CPU,你需要的資料已經發送到記憶體了,然後此時它可以将線程再切換回來,接着執行這個該線程的任務。
除了多線程切換,避免CPU閑置浪費,還有一點。
我先問一個問題。
對于一個應用/程序而言,它都應該有一個入口。(雖然不一定需要我們直接寫<code>main</code>函數)。入口函數内部就是我們的任務代碼,任務代碼執行完了這個應用/程序也就結束了。這個很好了解,比如測試工程師寫的一個測試case。跑完了這個任務就結束了。
但是 有些程式,比如一個 app,你打開了這個app。不做任何操作。這個界面會一直存在,也不會消失。思考一下這是為什麼。因為這個app程序肯定也要有一個main入口。 main裡面的任務代碼執行完了,就應該結束了。而一個程式的代碼/指令數目肯定是有限的。但該app在我們不主動退出情況下,卻不會主動結束。
是以這個app程序的入口main來講,其實是這樣的。
并且不僅如此,在一個程式内部,也有大量的for,while等循環語句。
那麼當我們把這些相關的代碼指令送到了主存,或者更高一級的緩存時,那麼CPU在執行這些指令時,存取速度自然快了很多。
在執行一個程式時,啟動階段比較慢,因為需要從磁盤讀取資料。(而CPU在這個階段也沒閑置浪費,它會進行線程切換執行其他任務)。 但是資料被送往記憶體之後,它執行起來就會快多了,并且伴随着執行過程,還可能越來越快,因為這些資料,有可能被一級一級的向上送,從L4,送到L3,再送到L2,L1
so,上述那個問題的答案,已經解釋的比較清楚了吧。
locality對于硬體和軟體系統的設計和性能都有着重要的影響。對于我們了解存儲器的層次結構也必不可缺。
程式傾向于引用臨近于與其他最近引用過的資料項的資料項。或者最近引用過的資料項本身。這種傾向性,我們稱之為局部性原理。它通常有以下兩種形式:
時間局部性(temporal locality):被引用過一次的存儲器位置的内容在未來會被多次引用。
空間局部性(spatial locality):如果一個存儲器位置的内容被引用,那麼它附近的位置也很大機率會被引用。
一般而言,有良好局部性的程式比局部性差的程式運作的更快。 現代計算機系統的各個層次,從硬體到作業系統、再到應用程式,它們的設計都利用了局部性。
當然,光說理論的東西比較玄乎。我們來看實際的例子。
在這個程式中,變量<code>sum</code>,<code>i</code>在每次循環疊代時被引用一次,是以對<code>sum</code>和<code>i</code>來說,有較好的時間局部性。
對變量<code>array</code>來說,它是一個int類型數組,循環時按順序通路<code>array</code>,因為一個C數組在記憶體中是占用連續的記憶體空間。因而的較好的空間局部性,
再來看一個例子:
這是一個空間局部性很差的程式。
假設這個數組是<code>array[3][4]</code>,因為C數組在記憶體中是按行順序來存放的。是以sum2對每個數組元素的通路順序成了這樣:0, 4, 8, 1, 5, 9…… 7, 11。是以它的空間局部性很差。
但是幸運的是,一般情況下軟體程式設計天然就是符合局部性原理的。比如程式的循環結構。
假設CPU需要讀取一個值,<code>int var</code>,而<code>var</code>在L4主存上,那麼該值會被依次向上送,L4->L3->L2,但是這個傳遞的過程并不是單純的隻傳遞<code>var</code>四個位元組的内容,而是把<code>var</code>所在的記憶體塊(block),依次向上傳遞,為什麼要傳遞block?因為根據局部性原理,我們認為,與<code>var</code>值相鄰的值,未來也會被引用。
存儲器的層次結構,資料進行傳送時,是以block(塊)為機關傳送的。在整個層次結構上,越往上,block越小而已。
洋洋灑灑的扯了那麼多,我相對于所謂的 存儲器層次結構讀者應該有一個基本的認識,有些地方介紹的 不夠嚴謹,但是本文的目的也就是讓大家了解基本思想。
歸根到底,它就是一個緩存(caching)的思想,并且其實不複雜,
我們做app開發時,對于app中活動頁面等,都是背景發給我們圖檔url,我們下載下傳後才顯示在app上,這時我們總要使用 <code>Glide</code>,<code>Picasso</code> 等圖檔緩存架構來把下載下傳好的圖檔緩存在手機本地存儲上。這樣下次打開app時,如果這個圖檔連結沒有改變,我們就直接拿手機本地緩存的圖檔來進行顯示,而不用再從伺服器上下載下傳了。如果圖檔連結改變了,則重新下載下傳。為什麼要這麼做?因為從伺服器上下載下傳比較慢,而手機本地存儲(ROM)中讀取就會快很多。
這個時候可以再回頭看看"圖4:一個存儲器層次結構的示例"。
下面這張圖和這段文字來自《深入了解計算機系統》(CSAPP),大家可以有個更嚴謹和細節的認識。
圖8:存儲器層次結構中基本的緩存原理
存儲器層次結構的中心思想:位于k層的更快更小的儲存設備作為位于k+1層得更大更慢的儲存設備的緩存;資料總是以塊大小為傳送單元(transfer unit)在第k層和第k+1層之間來回拷貝的;任何一對相鄰的層次之間傳送的塊大小是固定的,即每一級緩存的塊大小是固定的。但是其它的層次對之間可以有不同的塊大小。
當程式需要第k+1層的某個資料對象d時,它首先在目前存儲在第k層的一個塊中查找d。如果d剛好在k層,那麼就是緩存命中。如果第k層中沒有緩存資料對象d,那麼就是緩存命不中。當緩存不命中發生時,第k層的緩存從第k+1層 緩存中取出包含d的那個塊,如果第k層的緩存已經滿了的話,可能會覆寫現存的一個塊。(覆寫政策可以使用常見的LRU算法)。
在java和C當中,有一個<code>volatile</code>關鍵字(其他語言估計也有),它的作用就是在多線程時保證變量的記憶體可見性,但是具體怎麼了解呢?
我們在"圖4:一個存儲器層次結構的示例"中,說的緩存結構其實對于一個單核CPU而言的,比如 對于 一個四核三級緩存的CPU,它的緩存結構是這樣的。
圖9:多核處理器緩存結構
我們可以看到<code>L3</code>是四個核共有的,但是<code>L2</code>,<code>L1</code>其實是每個核私有的,如果我有一個變量<code>var</code>,它會被兩個線程同時讀取,這兩個線程在兩個核上并行執行,因為我們的緩存原理,這個<code>var</code>可能分别在兩個核的 <code>L2</code>或<code>L1</code>緩存,這樣讀取速度最快,但是該<code>var</code>值可能就分别被這兩個核分别修改成不同的值, 最後将值回寫到<code>L3</code>或<code>L4</code>主存,此時就會發生bug了。
是以<code>volatile</code>關鍵字就是預防這種情況,對于被<code>volatile</code>修飾的的變量,每次CPU需要讀取時,都至少要從<code>L3</code>讀取,并且CPU計算結束後,也立刻回寫到<code>L3</code>中,這樣讀寫速度雖然減慢了一些,但是避免了該值在每個core的私有緩存中單獨操作而其他核不知道。
本篇是"什麼是記憶體"系列第一篇文章,下一篇文章會讨論關于記憶體的另一個重要方面,兩篇文章加起來,相信大家會對記憶體有一個全面的,全新的認識。
這裡請大家思考以下幾個問題。
不管什麼程式,最後的直接/間接的編譯結果都是0和1,(我們直接了解為彙編)。(這點不知道的,歡迎閱讀我的另一篇文章關于跨平台的一些認識),比如這句彙編代碼:<code>mov eax,0x123456;</code>它的意思是将記憶體<code>0x123456</code>處的内容送往<code>eax</code>這個寄存器。各個應用的資料共同存在記憶體中的。假設有一個音樂播放器應用的彙編代碼中,引用了<code>0x123456</code>這個記憶體位址。但是同時運作的應用有很多,那其他應用也完全有可能引用 <code>0x123456</code>這個位址。那為什麼竟然沒起沖突和錯誤呢?
程序是計算機領域最重要的概念之一,什麼是程序?程序是關于某次資料集合的一次運作活動, 是運作在它自己位址空間的一段自包容程式, 解釋的通俗的點, 一個程式在運作時,我們會得到一個假象,該程序好像是獨占地使用CPU和記憶體,CPU是沒有間斷地一條接一條的執行該程式的指令,所有的記憶體空間都是供該程序的代碼和資料配置設定使用的。(這點不嚴謹,其實記憶體還有一部分要分給<code>核心kernel</code>)。說起來,這個程式就好像得到了全世界一樣。,CPU是我的,記憶體也全部我的,妹子們還是我的。當然這是假象而已。但是這些假象又是怎麼做到的呢?
程式中都會引用庫API,比如每個C程式都要引用<code>stdio.h</code>庫的<code>printf()</code>,在程式運作時,庫代碼也要被加入到記憶體,這麼多程式都引用了這個庫,難道我記憶體中需要加很多份嗎?這自然不可能,那麼庫代碼又是怎麼被所有程序共享的呢?
下篇文章将會給大家解釋這些問題,并且這些問題的答案是非常簡單的。相信大家看了會有恍然大悟的感覺,敬請期待。
1109補充
什麼是記憶體(二):虛拟記憶體已經發表。歡迎指點批評。
作者:
www.yaoxiaowen.com
部落格位址:
www.cnblogs.com/yaoxiaowen/
github:
https://github.com/yaowen369
歡迎對于本人的部落格内容批評指點,如果問題,可評論或郵件([email protected])聯系