在實際開發中,有時候會收到一些服務的監控報警,比如CPU飙高,記憶體飙高等,這個時候,我們會登入到伺服器上進行排查。本篇部落格将涵蓋這方面的知識:Linux性能工具。
背景:服務在平穩運作一段時間後,CPU突然飙高。
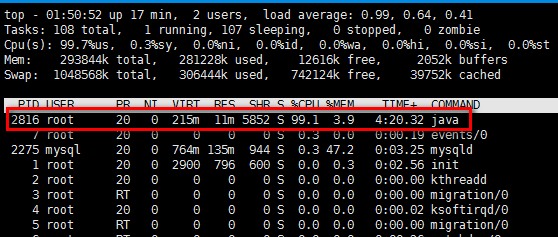
通過top指令,可以确認下,到底是哪個程序導緻CPU飙高了(也許是誤報呢?)。 可以看到圖中PID是2816的程序,CPU使用率非常高。

使用top -Hp 2816來對程序下的線程進行觀察。圖中可以發現,2825這個線程CPU非常高。
這裡利用Python非常友善的把十進制的線程ID轉化成了16進制,為什麼要這麼做呢? 因為在接下來的線程DUMP檔案中使用的就是16進制的NID。
在實際中,我們應該利用jstack pid多DUMP幾次,因為線程存在狀态轉換,是以多次DUMP有利于抓取到線程更多的資訊。 圖中,你可以觀察到,一個線程得到了鎖,在運作,遲遲沒有釋放,而另一個線程一直在等待這個鎖。至此,就可以到去檢視代碼去分析為什麼鎖遲遲不釋放的原因了。
上文的案例中,就使用到了top,而在實際中,top的資訊量是很大的,這裡詳細分析下。
第一行: 涉及到2個時間,一個是系統時間,一個是機器運作的時間。【我們應該重點關注的是機器運作的時間,Why? 有時候,重新開機機器能帶來很多問題,你懂的!】 多少使用者登入了系統?【通過who/w/history可以查到更多資訊】 3個load值是什麼含義? 分别代表的是1MIN,5MIN,15MIN機器的負載情況,如何确定負載的大小呢?需要和CPU的核數相結合來看,比如該機器是4核CPU,那麼如果load值超過了4,就意味着負載很大了!【在top下按下1可以觀察出CPU的個數】 上述資訊,其實也可以通過uptime指令來擷取。 第二行: 主要是總共有多少個任務,重點應該關注的是僵屍狀态的任務數。 第三行: 主要是CPU的一些資訊。 US/SY,說的就是使用者程序和系統程序使用CPU的占比。 NI,即NICE,表示被調整過線程優先級的程序占比,這個比例正常不應該很大。 ID,表示空閑;WA表示資源等待的時間,比如在瞬時大流量下,服務打了很多日志的話,那麼這個值就會飙高,因為這會很消耗資源的。 HI,硬中斷,一般就是外設引起的,如果HI飙高的話,那麼意味着外設在硬體層面出現了問題。SI表示軟中斷。 ST,即steel,如果該主機是虛拟的話會有這個ST資訊,也即是該虛拟機從主控端擷取CPU的時間片的百分占比。
第四和第五行: 這裡主要說2個概念性的東西:buffer 和 cache。 buffer主要是什麼呢?應該是待處理的資料,主要是處理2個系統之間速度不比對的問題。而cache,一般應該是結果資料的緩存,比如從DB加載一些資訊供查詢用。 SWAP分區,就是想利用硬碟的做一部分緩存,如果SWAP交換非常頻繁的話,就是說記憶體不夠用! 清單說明: PID 程序ID、USER 使用者、PR 優先級、VIRT 虛拟記憶體、RES 駐留記憶體、SHR 共享記憶體 這裡需要指出的是,RES表示的是該程序實際占用的記憶體,而并不是申請的記憶體大小。也就是說目前程序所占用的記憶體實體大小是 RES-SHR。