接着上一篇的介紹繼續
關于在使用readHeader函數讀取點雲資料頭的類型的代碼(Read a point cloud data header from a PCD file.)
檢視PCD檔案裡的内容(其實對于如何生成這種高緯度的檔案呢?)
另外一種PCD檔案的比如VFH的PCD檔案
那麼接下來我們就可以使用PCL給定的資料集,以及FLANN的庫是實作對點雲的識别,方法是按照(1)的思路來做的
首先我們是假設已經有了資料集,以及相應每個資料集的VFH全局表述子的PCD檔案,這樣我們就可以使用(1)中的思路把資料集訓練并儲存到數中,友善之後我們再輸入給定的點雲的VFH的PCD檔案進行查找
那麼其實這裡面,我們如果是自己生成資料集,并對每個資料生成對應的VFH檔案就會有點難度,畢竟這是對采集到的資料,對于一些無關點雲需要剔除,
然後對有用的有價值的點雲資料進行聚類,以及各個角度的點雲聚類,然後對聚類的對象生成對應的VFH的特征PCD檔案,這就是大緻思路,
那麼我們來看一下源代碼是如何讀取并訓練資料源的,并生成可用于FLANN使用的檔案,并存在磁盤中
源代碼分析如下
這裡面就很明顯的生成了兩個可用于FLANN進行搜尋比對的檔案,以及模型的名稱的清單,就是會生成以下三個檔案
kdtree.idx(這個是kdtree模型的索引)
training_data.h5(用于FLANN庫中的一種高效的檔案格式,上一章有介紹),
training_data.list(這是訓練資料集的清單)
(2)那麼對于已經生成好的點雲的資料集,我們就需要使用寫一個程式來實作給定一個點雲的VFH的PCD檔案來尋找這個點雲所在位置并且是什麼角度拍照的結果,閑話少說明,直接就上程式
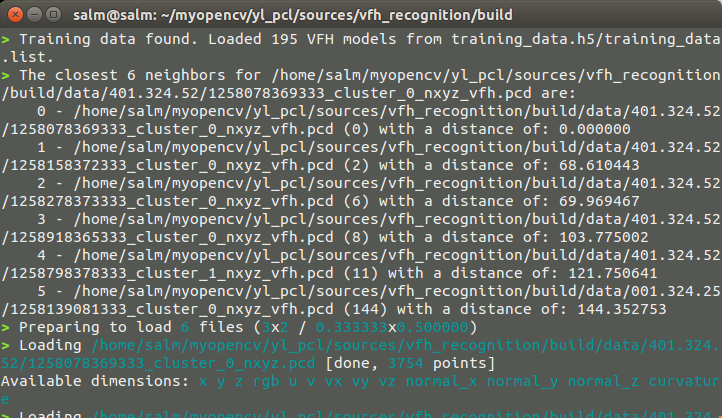
這裡面就涉及到FLANN的庫的函數的使用,執行的結果
列印的結果,這裡面會顯示最接近的六個資料集,并且計算這六個最近點雲與給定點雲之間的“距離”,這也是衡量兩者之間的相似度的大小
可視化的結果

很明顯左下角就是我們給定的資料點雲,而且運作查找的速度非常快~
好了就這樣了
關注微信公衆号,歡迎大家的無私分享