庫的位址:www.cs.ubc.ca/research/flann/
很顯然在PCL 搜尋最近鄰也是屬于高次元近鄰搜尋,是以需要用到這樣的庫來尋找比對的,比如我們如果想通過使用PCL點雲的資料來識别出物體到底是什麼,那麼很明顯是需要一個資料錄的,這個資料庫的訓練該怎麼來實作呢?因為我對機器學習了解的比較少,我想通過機器學習的方法來識别是最好的,也是今後可以做的工作,目前來看,我認為的方法就是通過對大量的點雲進行訓練并提取他們的特征點,比如VFH,然後把大量點雲訓練存儲成八叉樹,以便于很好的搜尋和比對,而且在PCL 中使用八叉樹是很常見的一種存儲結構,也是友善搜尋的,然後通過計算我們想要識别物體的點雲 的VFH,通過FLANN算法尋找到最接近的,這就是整體的思路
主要流程
使用SURF,SIFT特征提取關鍵點(在PCL中同樣适用) 計算特征描述子(比如VFH) 使用FLANN比對器進行描述子向量比對
那麼有興趣可以去仔細看看論文啊,我等渣渣真是多年以來對論文沒什麼感覺
介紹幾種FLANN庫中的API接口,如何去使用它,然後通過具體的執行個體去實作這樣一個比對
(1)flann::Index這是FLANN最近鄰指數類。該類用于抽象的不同類型的最近鄰搜尋索引。距離函數類模闆用于計算兩個特征空間之間的距離。
(2)flann::Index::knnSearch
對一組點查詢點,該方法執行K最近鄰搜尋。該方法有兩個實作,一個攜帶預開辟空間的flann::Matrix對象接收傳回的找到鄰居的索引号和到其距離;另一個是攜帶std::vector<std::vector>根據需要自動重新調整大小。
參數解釋:
queries: 承載查詢點的矩陣,矩陣大小是:查詢點數*緯數;
indices: 将承載所有被找到的K最近鄰的索引号( 預開辟的大小應該至少是查詢點數*knn);
dists: 将承載到所有被找到的K最近鄰的距離隻(預開辟大小應該至少是查詢點數*knn);
knn: 要找的最近鄰的個數;
params: 搜尋參數。承載搜尋時要使用的參數的結構體,結構體類型是SearchParameters。
在這裡就不再一一翻譯了
設定FLANN距離的類型
建立和傳回索引的函數
儲存索引到本地磁盤(僅僅是索引被儲存)
從磁盤中載入索引檔案
建立一個索引或者說指定一個索引來尋找最近鄰域
對提供的索引來尋找最近鄰
半徑搜尋的方法在已經建立的索引檔案中尋找
釋放記憶體
利用特征聚類
基本的介紹,可以檢視相應的手冊
#include <flann/flann.h>
#include <flann/io/hdf5.h>
其中還涉及到另外一種檔案的資料結構的使用,一般都會包含兩個頭檔案,第一個頭檔案是關于FLANN算法實作的聲明的函數集,第二個頭檔案是關于資料結構的一種存儲的方式,hdf5是用于存儲和分發科學資料的一種自我描述、多對象檔案格式,HDF 被設計為:
自述性:對于一個HDF 檔案裡的每一個資料對象,有關于該資料的綜合資訊(中繼資料)。在沒有任何外部資訊的情況下,HDF 允許應用程式解釋HDF檔案的結構和内容。
通用性:許多資料類型都可以被嵌入在一個HDF檔案裡。例如,通過使用合适的HDF 資料結構,符号、數字和圖形資料可以同時存儲在一個HDF 檔案裡。
靈活性:HDF允許使用者把相關的資料對象組合在一起,放到一個分層結構中,向資料對象添加描述和标簽。它還允許使用者把科學資料放到多個HDF 檔案裡。
擴充性:HDF極易容納将來新增加的資料模式,容易與其他标準格式相容。
跨平台性:HDF 是一個與平台無關的檔案格式。HDF 檔案無需任何轉換就可以在不同平台上使用
最好的辦法是把HDF 檔案看成為一本有表格内容的多章節書。HDF 檔案是“資料書”,其中每章都包含一個不同類型的資料内容。正如書籍用一個目錄表列出它的章節一樣,HDF檔案用“data index”(資料索引)列出其資料内容
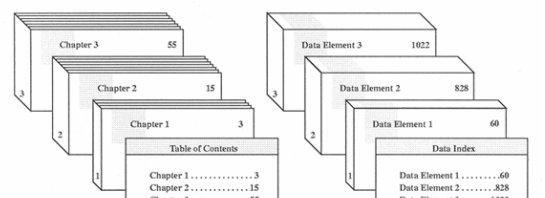
HDF 檔案結構包括一個file id(檔案号)、至少一個 data descriptor (資料描述符)、沒有或多個 data element(資料内容)資料内容。
以上内容是涉及到關于對PCL中物體的識别的基礎知識。
有興趣者關注微信公衆号,更歡迎大家投稿分享,隻要是關于點雲的都可以分享
