库的地址:www.cs.ubc.ca/research/flann/
很显然在PCL 搜索最近邻也是属于高维度近邻搜索,所以需要用到这样的库来寻找匹配的,比如我们如果想通过使用PCL点云的数据来识别出物体到底是什么,那么很明显是需要一个数据录的,这个数据库的训练该怎么来实现呢?因为我对机器学习了解的比较少,我想通过机器学习的方法来识别是最好的,也是今后可以做的工作,目前来看,我认为的方法就是通过对大量的点云进行训练并提取他们的特征点,比如VFH,然后把大量点云训练存储成八叉树,以便于很好的搜索和匹配,而且在PCL 中使用八叉树是很常见的一种存储结构,也是方便搜索的,然后通过计算我们想要识别物体的点云 的VFH,通过FLANN算法寻找到最接近的,这就是整体的思路
主要流程
使用SURF,SIFT特征提取关键点(在PCL中同样适用) 计算特征描述子(比如VFH) 使用FLANN匹配器进行描述子向量匹配
那么有兴趣可以去仔细看看论文啊,我等渣渣真是多年以来对论文没什么感觉
介绍几种FLANN库中的API接口,如何去使用它,然后通过具体的实例去实现这样一个匹配
(1)flann::Index这是FLANN最近邻指数类。该类用于抽象的不同类型的最近邻搜索索引。距离函数类模板用于计算两个特征空间之间的距离。
(2)flann::Index::knnSearch
对一组点查询点,该方法执行K最近邻搜索。该方法有两个实现,一个携带预开辟空间的flann::Matrix对象接收返回的找到邻居的索引号和到其距离;另一个是携带std::vector<std::vector>根据需要自动重新调整大小。
参数解释:
queries: 承载查询点的矩阵,矩阵大小是:查询点数*纬数;
indices: 将承载所有被找到的K最近邻的索引号( 预开辟的大小应该至少是查询点数*knn);
dists: 将承载到所有被找到的K最近邻的距离只(预开辟大小应该至少是查询点数*knn);
knn: 要找的最近邻的个数;
params: 搜索参数。承载搜索时要使用的参数的结构体,结构体类型是SearchParameters。
在这里就不再一一翻译了
设置FLANN距离的类型
建立和返回索引的函数
保存索引到本地磁盘(仅仅是索引被保存)
从磁盘中载入索引文件
建立一个索引或者说指定一个索引来寻找最近邻域
对提供的索引来寻找最近邻
半径搜索的方法在已经建立的索引文件中寻找
释放内存
利用特征聚类
基本的介绍,可以查看相应的手册
#include <flann/flann.h>
#include <flann/io/hdf5.h>
其中还涉及到另外一种文件的数据结构的使用,一般都会包含两个头文件,第一个头文件是关于FLANN算法实现的声明的函数集,第二个头文件是关于数据结构的一种存储的方式,hdf5是用于存储和分发科学数据的一种自我描述、多对象文件格式,HDF 被设计为:
自述性:对于一个HDF 文件里的每一个数据对象,有关于该数据的综合信息(元数据)。在没有任何外部信息的情况下,HDF 允许应用程序解释HDF文件的结构和内容。
通用性:许多数据类型都可以被嵌入在一个HDF文件里。例如,通过使用合适的HDF 数据结构,符号、数字和图形数据可以同时存储在一个HDF 文件里。
灵活性:HDF允许用户把相关的数据对象组合在一起,放到一个分层结构中,向数据对象添加描述和标签。它还允许用户把科学数据放到多个HDF 文件里。
扩展性:HDF极易容纳将来新增加的数据模式,容易与其他标准格式兼容。
跨平台性:HDF 是一个与平台无关的文件格式。HDF 文件无需任何转换就可以在不同平台上使用
最好的办法是把HDF 文件看成为一本有表格内容的多章节书。HDF 文件是“数据书”,其中每章都包含一个不同类型的数据内容。正如书籍用一个目录表列出它的章节一样,HDF文件用“data index”(数据索引)列出其数据内容
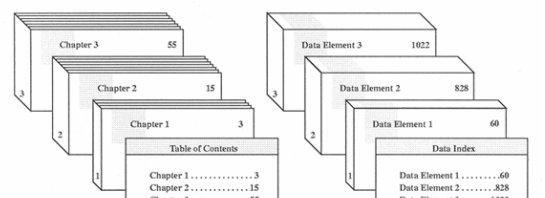
HDF 文件结构包括一个file id(文件号)、至少一个 data descriptor (数据描述符)、没有或多个 data element(数据内容)数据内容。
以上内容是涉及到关于对PCL中物体的识别的基础知识。
有兴趣者关注微信公众号,更欢迎大家投稿分享,只要是关于点云的都可以分享
