目錄
<a href="#_Toc376526215">SQL Server 2014 新特性——記憶體資料庫... 1</a>
<a href="#_Toc376526216">簡介:... 1</a>
<a href="#_Toc376526217">設計目的和原因:... 1</a>
<a href="#_Toc376526218">專業名詞... 1</a>
<a href="#_Toc376526219">In-Memory OLTP不同之處... 2</a>
<a href="#_Toc376526220">記憶體優化表... 2</a>
<a href="#_Toc376526221">記憶體優化表的索引... 2</a>
<a href="#_Toc376526222">并發能力的提升... 3</a>
<a href="#_Toc376526223">和競争對手相比幾點... 3</a>
<a href="#_Toc376526224">Getting Start. 3</a>
<a href="#_Toc376526225">記憶體資料庫的使用... 3</a>
<a href="#_Toc376526226">存儲... 5</a>
<a href="#_Toc376526227">TSQL支援... 7</a>
記憶體資料庫(In-Memory OLTP),代号Hekaton
1.将請求的負荷放到記憶體中
2.減少資料延遲
3.來适應特殊的負荷類型
如果資料都是在記憶體中,那麼目前的資料庫優化器産生的執行計劃是沒什麼意義的,因為現在的優化器預設資料在磁盤中而不是在記憶體中,是以不從磁盤中讀取資料,優化器應該使用新的執行計劃和新的開銷算法。
In-Memory OLTP 減少了鎖等待問題,使用基于行版本來優化同步的控制,改善了寫入等待的延遲,寫入日志變少,寫入次數變少。
Memory-optimized tables(索引優化表):引入了新的結構,被加入到in-memory oltp的新表
Disk-Based tables(磁盤表):基礎磁盤存放的表,就是我們一直使用的表。
Natively complied(原生編譯)存儲過程:用于索引優化表的通路,也可以使用tsql通路,通過原生編譯存儲過程通路速度會更快一點
嵌套事務:可以在優化表中使用,也可以在磁盤表中使用
interop:可以讓tsql通路索引優化表
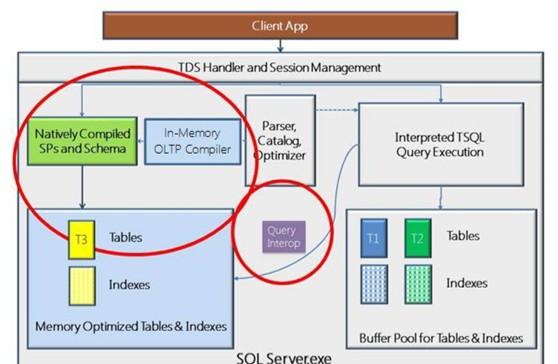
通過圖可以發現,原生編譯存儲過程隻能使用在記憶體優化表上,而query interop使用者tsql通路記憶體優化表的橋梁
1.記憶體優化表和硬碟表不同,不需要把資料從硬碟上讀取放入cache中,
2.checkpoint隻是使用者恢複的目的
3.和硬碟表一樣,使用事務日志,當服務重新開機後,使用checkpoint的檔案和日志,對記憶體優化表進行重建
4.記憶體優化表可以通過選項來設定表的持久性:SCHEMA_ONLY隻儲存表的結構,不儲存資料,當服務重新開機後資料就會丢失
1.記憶體優化表中的索引不再以btree方式存儲,而是以hash 表的方式
2.記憶體優化表必須有一個索引,并沒有堆表的概念
3.索引,不會被儲存在檔案或者事務日志,并會根據記憶體優化表的修改自動維護,在所有重新開機時,根據表的檔案和日志重建索引
1.以行版本的方式存儲表資料,修改資料時會請求鎖,但是在記憶體優化表中不會
2.雖然沒有寫入鎖,但是還是有等待比如log write,比硬碟表高效,寫入的日志少,速度快
1.記憶體表和硬碟表通過interop內建,有利于過渡
2.原生編譯存儲過程,效率高
3.hash索引,提高記憶體通路效率
4.沒有page,不會出現page latch的等待
5.通過行版本實作,不需要lock和latch
CREATE DATABASE HKDB
ON
PRIMARY(NAME = [HKDB_data],
FILENAME = 'Q:\data\HKDB_data.mdf', size=500MB),
FILEGROUP [SampleDB_mod_fg] CONTAINS MEMORY_OPTIMIZED_DATA
(NAME = [HKDB_mod_dir],
FILENAME = 'R:\data\HKDB_mod_dir'),
FILENAME = 'S:\data\HKDB_mod_dir')
LOG ON (name = [SampleDB_log], Filename='L:\log\HKDB_log.ldf', size=500MB)
COLLATE Latin1_General_100_BIN2;
在建立庫時需要制定 MEMORY_OPTIMIZED_DATA檔案組,用來儲存checkpoint和delta檔案,
建立的資料庫隻能使用BIN2排序規則,原生編譯存儲過程隻能支援在這些規則上比較,排序,分組
ALTER DATABASE AdventureWorks2012 ADD FILEGROUP hk_mod CONTAINS MEMORY_OPTIMIZED_DATA;
GO
ALTER DATABASE AdventureWorks2012 ADD FILE (NAME='hk_mod', FILENAME='c:\data\hk_mod')
TO FILEGROUP hk_mod;
CREATE TABLE T1 (
[Name] varchar(32) not null PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1024),
[City] varchar(32) null,
[LastModified] datetime not null,
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);
1.建立記憶體優化表是需要注明,MEMORY_OPTIMIZED=ON,并設定持久性
2.bit,tinyint,smallint,int,bigint,money,smallmoney,float,real,datetime,smalldatetime,datetime2,date,time,numeric,decimal,char,varchar,nchar,nvarchar,sysname,binary,varbinary,uniqueidentifier
BLOB的資料類型都是不被支援的
3.有2個持久性選項:1.SCHEMA_AND_DATA持久化資料和結構,2.SCHEMA_ONLY隻持久化結構
4.每個表至少有一個索引,會自動為主鍵限制建立索引,在建立索引是要指定hash索引的bucket_count
5.建立表後,記憶體資料庫引擎會自動加載用于DML的原生編譯存儲過程,像加載ddl一樣
6.SQL Server 自身不操作記憶體資料庫的資料,而是通過ddl來操作
7.記憶體資料庫的限制:1.沒有觸發器,2.沒有外鍵和check,3.沒有identity,4.沒有主鍵以外的唯一索引5.最大8個索引,包括主鍵索引,9.不能通過alter table修改表結構,索引沒有DDL,索引是和表一體的,作為表的一部分建立
記憶體優化表使用記憶體位元組位址,來代替磁盤區塊位址,不想堆表,記憶體優化表的行并不是存放在一起的,而是通過一個标記,來指明是同一個索引

結構圖
每行分為,行頭和payload。
行頭有begints(行插入時間),endts(行删除時間),stmtid(儲存事務中的語句id),idxlinkcount(索引引用計數器,若為0,會被指向到垃圾回收器),最後面8個位元組*索引個數,說明記憶體表的索引。
payload是資料區,包含key和所有其他列,是以hash索引都是覆寫索引。
hash索引是一組指針,每個組中的單元叫做hash bucket,index key通過hash計算把所有相同的hash值用同一個指針。
當索引被建立的時候,必須制定bucket大小,大小必須大于表中會産生的bucket大小,每個bucket都是使用記憶體的,并且是2的整數次幂,若設定的太多不但不會提升性能,然後會在掃描的時候降低性能。
通過維護一個内部事務id(時間戳)來确定一個事務可見的行版本。
有三個時間需要留意:
1.Commit/End Time 每個事務資料被修改的時間都稱為 Commit Time或者End Time
2.Valid Time 可用時間,由3部分組成,BeginTx(行版本插入時間),Endtx(行版本删除時間),在之間的就是可用時間
3.Logical Read Time 讀時間可以是事務開始到現在的任何時間,隻要行版本的可用時間可以覆寫讀時間,那麼行版本就是可讀的,對于讀送出之外的隔離級别讀取時間是事務的開始時間,對于讀送出讀取時間是語句的執行時間。
記憶體資料庫支援一下幾種隔離級别:
1.快照
2.可持續讀
3.串行
隻有在自動送出事務裡面才能支援讀送出隔離級别,顯式事務或者隐式送出事務都不支援讀送出隔離級别
當不通路硬碟表的自動送出事務可以支援讀送出快照,當使用TSQL啟用快照隔離級别,不能通路記憶體優化表,當使用TSQL使用串行隔離級别,要使用快照隔離級别通路通路記憶體優化表。
删除:删除操作隻會在endtx上寫入一個時間戳,表示資料是否活躍,任何活動中的事務要通路這條資料,在時間戳範圍内,都要看是否在該記錄還是活躍。
插入/修改:修改操作時先插入後删除,任何寫沖突的事務都會直接報錯,修改完成後,要開始檢查隔離級别,如果隔離級别不對,那麼就復原。任何修改都會被記入write set中,有個指針執行相關的行。
讀取:以讀取時間為時間點,讀取可以覆寫讀取時間的行
驗證:因為記憶體資料庫沒有鎖,是以要使用驗證來保證一緻性:
1.快照隔離級别,commit出錯,由2個以上插入同一個主鍵
2.可持續讀,讀取的行,在送出前被另外一個事務修改
3.串行,讀取可用行出錯,或者出現幻影,無法保證串行
通過interop可以使用tsql通路記憶體優化表,性能比原生編譯存儲過程差,但是友善,易相容。
不支援,truncate,merge,動态、鍵值遊标,交叉資料庫查詢,交叉資料庫事務,連接配接伺服器,鎖提示,READUNCOMMITTED,READCOMMITTED,READCOMMITTEDLOCK這幾個隔離界别的提示,記憶體表類型和變量不支援。
優點:可以執行的更快,有不少的限制,如資料類型和排序規則,不能用于通路硬碟表
缺點:相容性差