本文大意:
錯誤832:
A page that should have been constant has changed (expected checksum: 1dcb28a7, actual checksum: 68c626bb, database 13, file 'E:\Program Files\microsoft sql server\MSSQL\data\BlahBlah.mdf', page (1:112644)). This usually indicates a memory failure or other hardware or OS corruption.
當一個頁從磁盤讀入,被标記為幹淨,如果被修改,變成髒頁,檢查checksum,發現checksum不再可用,832錯誤發生,發生這個錯誤一般出現在:1.記憶體問題,2.作業系統記憶體管理器問題,或者流氓程式寫入到sql server。
1.通過微軟産品支援,跟蹤記憶體
2.通過替換法,替換記憶體
windows是支援大資料頁的,關于windows大資料頁的支援可以看Microsoft windows internal,X64支援2MB的大資料頁。
有3個條件決定了是否使用大資料頁:
1.sql server企業版
2.記憶體在8G以上
3.Lock Page in Memory權限
這個檢查Lock Page in Memory和buffer pool使用AWE API沒有關系,因為Large Page 也是不在work set中,也是不能被page out的。
如果Large Page啟用會在error log中有一下資訊:
2009-06-04 12:21:08.16 Server Large Page Extensions enabled.
2009-06-04 12:21:08.16 Server Large Page Granularity: 2097152
2009-06-04 12:21:08.21 Server Large Page Allocated: 32MB
但是有人會懷疑,明明沒有開啟TF 834為什麼會用large page,因為TF834隻限制buffer pool用不用large page。
開啟834之後,buffer pool使用large page,因為large page通過virtualalloc()配置設定記憶體,比較慢是以會在開機時一次性配置設定。
啟動時,配置設定算法:
1.會根據max server memory 和實體記憶體的最小值,若沒有設定max server memory那麼會配置設定所有記憶體。是以max server memeory的設定很總要
2.當使用large page的時候最讓是sql server專用伺服器。
3.如果不能配置設定,那麼會配置設定的少一點,還是不能配置設定就會報錯,服務無法啟動。
注意:
記憶體size必須是連續的,并且在使用過程中buffer pool 不會自動增長。
使用large page導緻開機時間變成,因為virtualalloc配置設定記憶體比較慢,并且時間不單單是配置設定記憶體的時間
總結
1.large page在記憶體>8gb,并有lock page權限
2.需要開啟TF834,擦能讓buffer pool使用large page
2.需要啟動TF834,64作業系統并且已經啟動了large page
3.large page 并不适用所有場景應該測試後再決定
作者在64BIT環境下看到一個錯誤,并且被問是否和MemToLeave有關。
作者解釋了在64bit下并沒有MemToLeave。
當32bit的年代,虛拟位址空間隻有4個g,核心2g,使用者2g,也可以通過4g選項調整為核心1g,使用者3g,反正就是很少,設計者會為buffer pool保留位址,buffer pool有位址了,才不會影響記憶體的使用。buffer pool盡量大的保留位址空間了,但還是沒有用完位址空間,因為有記下幾個也需要用記憶體的:
1.線程stack,2.heap,3.SQL Server多頁配置設定,4.其他DDL配置設定。
MemToLeave的意思就是留下來用來做别的事情,比如上面的,當服務啟動的時候sql server 會先保留一部分位址空間,然後buffer pool保留位址空間,保留完之後,memtoleave釋放位址空間。保留的位址的大小如下:線程堆棧大小*線程數+g參數的大小(預設256M)。
當64位來臨,帶來了大量的位址空間,是以沒有必要在再服務啟動時去保留位址空間,直接在需要用的時候配置設定就好了。
1.sql server 2005啟動的時候發現一緻性檢查資訊,但是不管資料庫大小,檢查都很快,為什麼?
其實這些并不是實際上的檢查,隻是把上次最後一次檢查的資訊輸出出來。當dbcc checkdb運作完之後會寫入到boot page 上。啟動服務的檢查隻是把boot page的資訊print出來。
2.如何确定記憶體被使用在那個資料庫?
sql server會占用大量記憶體,并且在沒必要的時候是不會釋放啊記憶體,除非os有記憶體壓力。sql server主要的記憶體都使用在buffer pool中,還有一部分是使用在plan cache中,記憶體多可以減少io,可以減少編譯所占用的時間。可以通過sys.dm_os_buffer_descriptors是buffer pool的資訊,來确定是那個資料庫占用了記憶體。當然也可以使用 dbcc memorystatus 來确定執行個體記憶體的使用。
3.資料庫偶爾會出現SUSPECT和RECOVERY_PENDING的情況,就會需要通過被備份恢複,會有資料丢失的問題,如何解決?
這2個狀态都是由故障恢複的時候出現的,當crash 恢複,讀不到日志的時候會出現RECOVERY_PENDING。當日志可讀,但是日志可以通路,但是無法完成恢複,一緻性不對的時候會出現SUSPECT。有2個原因會導緻恢複無法完成,1.日志資料問題,2.資料檔案有問題。
還有一個會進入SUSPECT狀态就是,當事務復原,在復原時出現錯誤。
可以使用備份來恢複資料,如果沒有備份可以轉入應急模式,來恢複。
4.高安全的資料庫鏡像使用witness是如何識别錯誤的?
錯誤識别有一下幾種:
1.sql server執行個體級crash,每秒ping,能ping通但是發現sql server沒有監聽端口,立即報告
2.伺服器級别crash,每秒ping 不能ping通馬上報告
3.事務磁盤問題,當日志寫入的隊列太高,20秒後會寫入到error log,40秒後認為log 磁盤offline,觸發切換
4.資料庫頁出錯,資料庫會變成suspect狀态,馬上觸發切換
5.如果檔案或者檔案組offline,primary正常,當碰到錯誤是切換。
記憶體浪費是可恥,特别是對于資料庫來說,記憶體不足有一下幾個特點:
1.實體io變多,不管讀還是寫
2.Lazy write變多
3.RESOURCE_SEMAPHORE等待變多,因為查詢需要記憶體
4.大量的plan重編譯,因為沒有地方放plan cache
低資料密度:
使用sys.dm_os_buffer_descriptors可以看,到底buffer pool 裡面有多少是空的,也就是浪費的。
低資料密度引起的原因一般就怎麼幾個:
1.寬行,那麼就使用小的資料類型
2.分頁,合理設定填充因子
3.行删除,導緻内部碎片
低資料密度也會有一下幾個代價:
1.io變多,因為空間被浪費了
2.磁盤空間被浪費
3.記憶體被浪費
低資料密度解決辦法:
1.小資料類型
2.使用順序的key,不要用随機降低分頁
3.調整填充因子,填充因子本身就是一種浪費,是以要合理不能太大
4.重建索引
5.資料壓縮
作者各處了一些腳本,自己去原文看,個人覺得還是蠻有用的。
在鏡像伺服器出現不能擷取LOCK資源,很有趣,鏡像是不會動的,為什麼會出現這個錯誤?
原因很簡單,比如一個事務主體回顧的時候,鏡像也復原,會滾就會産生事務,不信自己試試看。
LOCK結構是需要記憶體的,盡管很小,但是量大的時候,也是很可怕的,作者就認為,主體記憶體和鏡像記憶體不太一緻,導緻主體上的lock大量,但是鏡像上無法達到這個量導緻的問題。那麼把2邊的記憶體搞成一樣,更有甚者,很多復原事務同時到鏡像,也是會報這個錯誤,那麼就繼續加記憶體。作者的意思是加記憶體。
作者給出了一個sql用來跟蹤sql server 對虛拟記憶體的儲存和使用。
VAS也就是虛拟位址,一般處理問題的時候很少去關注虛拟位址,虛拟位址使用VirtualAlloc*/VirtualFree*配置設定和釋放,可以保留白間,也可以配置設定記憶體。
配置設定記憶體的方式是:先保留白間然後馬上配置設定記憶體,綁定。VAS最小塊為64KB,并以64KB為配置設定單元。
每個程序都有VAS,為了友善使用,在VAS配置設定之後會配置設定一個VAS,用來描述VAS。VirtualQuery API和sys.dm_virtual_address_dump都是使用VAD查資訊。
VAS是很重要的資源,是以要跟蹤這些資源,有2個工具:VASUMP,可以檢視VAS利用但是沒辦法檢視是哪個元件配置設定的。還有一個LEAKDIAG可以跟蹤到元件級别的資訊。
作者給出了一個跟蹤線程stack的例子,來說明。可以使用sys.dm_os_threads,sys.dm_os_load_modules,sys.dm_os_virtual_address_dump連接配接擷取VAS資訊
SELECT * FROM sys.dm_os_virtual_address_dump a
INNER JOIN sys. dm_os_loaded_modules b ON a.region_allocation_base_address = b.base_address
INNER JOIN sys. dm_os_threads b ON a.region_allocation_base_address = b .thread_address
VAS綁定page是按需的,當page第一次被通路,綁定發生,一次隻能一個頁(綁定和送出有什麼差別?綁定主要做些什麼事情)。若第一次通路出現硬體頁錯誤,那麼OS嚴重VAD,VAS是否送出,若已經送出,OS會在記憶體中找一個空的頁,初始化,并且把頁綁定到虛拟位址,并填入資料結構。
當記憶體使用緊張,會啟動回收機制,把程序中的要釋放的頁,page 到磁盤上,并修改資料結構,下次通路的時候就會找到,page 完成後,清零并放到free list中。
錯誤頁,頁錯誤有3種,最被人說道的是2種1:軟錯誤,2.硬錯誤:
軟錯誤出現在,第一次通路的時候,因為mmu中沒有記錄,但是資料頁在記憶體中存在是以會出現。
硬錯誤,在記憶體中不存在在頁面檔案中有
實體頁能夠映射到不同的VAS,若值映射到一個VAS,我們就稱私有的,否則就是共享的。使用virtualalloc都不能共享。
為了不讓記憶體不切換的頁面檔案,可以使用page lock,page lock會打破系統内記憶體的平衡,可以使用lock page in memory權限打開。
4G調整和AWE是對虛拟位址的應用,4G調整,讓核心模式隻占用1G的記憶體空間,其他3G為使用者模式位址。
為了能夠通路4G以上記憶體,windows出了一個PAE,實體位址擴充,從32擴充到36能讓windows 通路64G實體記憶體,相應出了AWE,通過virtualalloc配置設定位址并映射到實體記憶體的方式通路。AWE的記憶體os不能page,但是如果濫用,會導緻性能問題,隻能通過重新開機程序來釋放。
記憶體壓力分為2種,1.内部壓力,2外部壓力
外部記憶體壓力又分為,靜态記憶體壓力:系統運作超出頁面檔案,導緻系統記憶體不足,動态記憶體壓力:os可用記憶體不足。
windows會通知程序目前記憶體是否有壓力,或者你記憶體太多,應用程式實施的開辟記憶體或者收縮記憶體。
内部記憶體壓力分為:1.記憶體壓力,2.VAS壓力。
外部記憶體壓力導緻記憶體收縮就可能英氣内部記憶體壓力。或者使用記憶體的限制也可能導緻記憶體壓力。處理方法:收縮stack,pool,把記憶體傳回給記憶體管理器
造成VAS壓力的情況2中:1.VAS碎片導緻,無法開辟聯系的VAS空間,2.VAS位址空間不夠消耗的。VAS不足會導緻,系統變慢,甚至程序終止。處理方法:收縮stack,pool。
以下幾點要在實作,記憶體通知的時候注意:
外部記憶體壓力出現:記憶體被page out,記憶體壓力通知,釋放記憶體,記憶體變多,有開辟,又有記憶體壓力通知以此循環
當頁面檔案變小,沒有通知,而是在下次配置設定的時候直接報out of memory
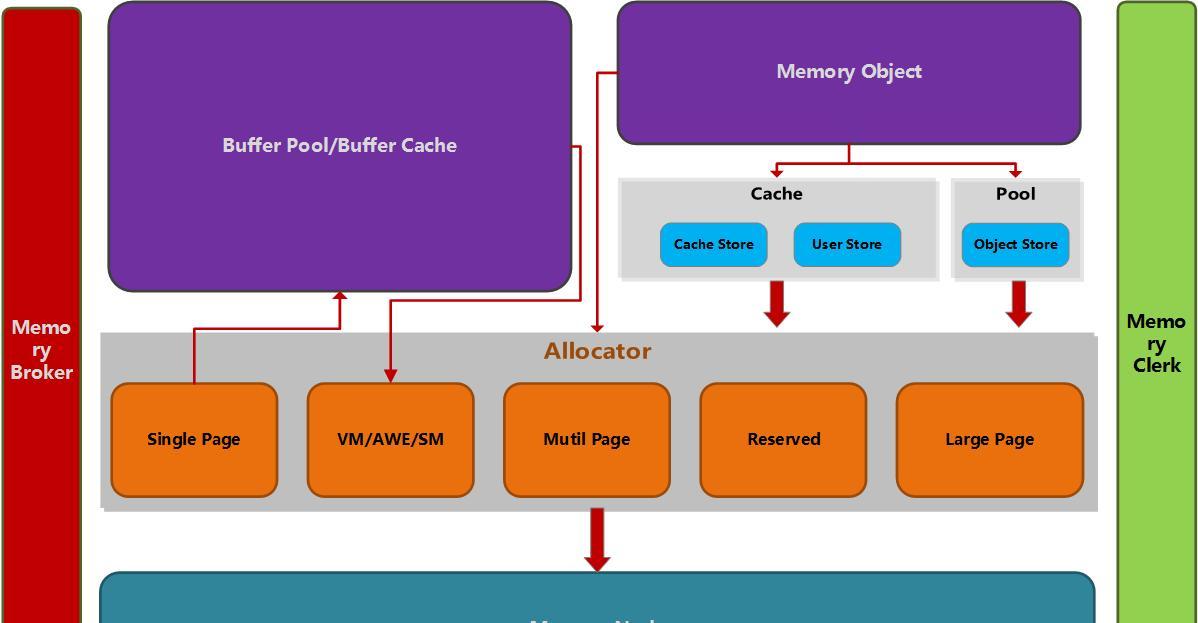
記憶體節點:主要提供本地記憶體的配置設定,由一些配置設定器組成。
記憶體clerk:clerk有4中類型,generic,cache store,user store,object store,可以用來跟蹤記憶體的使用。
記憶體對象:記憶體對象的記憶體配置設定會被記錄到clerk中。對象分為3種:1.可變記憶體對象正常heap,2.自增記憶體對象,是mark/shrink heap 3.固定長度的記憶體對象(記憶體對象内部還沒有研究),記憶體對象和clerk都有頁配置設定器位址,可以使用這個,檢視對象對應的clerk。
buffer pool:sp_configure,有2個參數,最大服務記憶體,最小服務記憶體,用來控制buffer pool,但是不能控制其他元件。在服務啟動的時候,sql server 會先保留一部分位址空間,是g參數+最大線程數*512KB(32位,64位為2M)就是MemtoLeave。然後再為buffer pool保留位址空間。buffer pool是根據内部記憶體和外部記憶體狀況按需配置設定,計算目标記憶體,根據實際狀況計算,并不引起記憶體壓力,為了避免page,target經常被重新計算。buffer pool配置設定單元大小是8kb,其他元件需要記憶體時可以用buffer pool作為底層記憶體管理。在sql server 啟動的時候buffer pool被設定為sqlos的單頁配置設定器。對于大的元件都有自己的clerk,buffer pool也一樣通過VM/AWE/SM配置設定記憶體。所有元件從buffer pool配置設定記憶體最好,是以小記憶體配置設定首選buffer pool,當需要大記憶體的時候從Mutil Page等配置設定。
buffer pool和AWE機制:有幾個注意點:1.buffer pool通過clerk來記錄VAS和實體頁的配置設定,2.buffer pool使用4mb的VAS而不是大的,因為4MB容易對記憶體壓力做出反應。3.2000中BP是一次性配置設定的,2005則是按需配置設定的。AWE不算workset,是以當啟動AWE是,記憶體配置設定很難在裡面發現。隻有buffer pool能夠map,unmap記憶體,是以其他元件不能使用AWE。
記憶體壓力實際上可以分為VAS,實體記憶體,實體記憶體壓力可能是外部壓力,也可能是内部壓力。
RM運作一些監控的名額,來判斷是否有記憶體壓力。一旦有問題就會廣播到memory clerk。RM位于cpu節點上,是以可能有多個RM在運作。
多數記憶體的消耗,在clerk中都有記錄,而且每個cpu節點都有一份clerk,RM先計算通知,然後通過list廣播通知。
有幾個注意點:1、RM有自己的排程器,2.RM運作在非搶占模式下,3.DAC節點沒有RM
外部記憶體壓力,RM,Buffer pool:BP被當做一個單頁配置設定器,當出現外部記憶體壓力,RM廣播到clerk,BP重新計算可用記憶體,然後shrink,一直循環知道壓力消失。但是不低于最小服務記憶體。
内部記憶體壓力,RM,Buffer Pool:當buffer pool出現記憶體壓力,sqlos通過一些機制打開RM内部記憶體壓力的辨別符,然後通知clerk,buffer pool并不對内部記憶體壓力作出反應。動态修改最大服務記憶體,BP中75%的頁被steal也會觸發内部記憶體壓力
VAS壓力:當virtual或者shared memory配置設定4MB的位址空間失敗,或者掃描VAS不存在4MB的連續空間時,通知VAS不足。2000中很難對VAS壓力處理,在2005中會通知所有的clerk所有會有機會去shrink:1.shrink thread,2.解除安裝CLR,3.network lib收縮buffers。當buffer pool使用AWE時,發現有4MB的位址空間沒有被使用的,也會被釋放。
通過檢視DMV:
SELECT *
FROM sys .dm_os_ring_buffers
WHERE ring_buffer_type = 'RING_BUFFER_RESOURCE_MONITOR'
随着時間,就很容易看出盡力了哪些記憶體壓力。
2000中,cache主要是2種:data page cache:buffer pool,procedure cache:plan cache,plan cache通過buffer pool來完成對cache大小的控制,但是随着2005,cache變得越來越多,是以通過buffer pool控制是不太可以了解的,是以使用了通用的架構。
2005中有3總主要的cache 類型:cache store,user store,object store,其中又分為cache 和pool,其中 cache strore 和user store是cache,object cache 是pool
cache最主要的特點是:存放各種不同的資料,使用cost,結合lru來實作算法。pool:沒有cost,也不需要做lru算法。并且有2個概念:生命周期控制,和可見性控制
生命周期的算法可以自己實作,也可以用架構的,比如cache store 是使用架構的,user store是自己一部分,架構一部分。生命周期通過應用計數管理,
可見性通過pin count管理
SQLOS 通過LRU算法實作了可見性和生命周期的控制,模拟LRU算法實作了時鐘政策,外部時鐘指針,和内部時鐘指針。
外部時鐘指針:通過RM而移動用來控制sql server 整體記憶體
内部時鐘指針:用來控制cache 的大小,避免單個cache占用過大的記憶體。
時鐘指針移動并不會影響存儲,并且隻有當2個指針都運作過的時候,記憶體塊才會被回收。
<a href="http://blogs.msdn.com/b/slavao/archive/2005/04/29/413425.aspx">Be Aware: Using AWE, locked pages in memory, on 64 bit</a>
64位中還是可以使用AWE的,AWE使用的步驟2步:1.配置設定記憶體(PFN),2.映射到VAS中。但是AWE配置設定的記憶體釋放1.終止程序,2.程式控制釋放。
通過頁表項(PTE)來表示用來描述實體記憶體和VAS的映射,内部實體也通過PFN表示。OS有個庫用來儲存PFN,AWE配置設定後的PFN也儲存在這裡,一旦屋裡也綁定到VAS,PFN會指回PTE。AWE配置設定的記憶體一旦與VAS綁定就是lock的不會被換出。
在64位下使用AWE有2個好處:1.不會被換出,對于NUMA有顯示的駐留資訊,當被page後很難再回到,原來的處理器,這樣做顯然會增加通路記憶體的消耗。2.鎖定是workset和PFN鎖定。這樣可以讓應用程式運作的較快,并且擴充性也較好。numa中buffer pool通過queryworkingsetex函數來查詢記憶體所在的節點資訊,因為是lock的是以隻需要執行一次即可,提高了性能。唯一要注意的是記憶體不足時,lock的記憶體沒辦法被換出,擷取可能記憶體。
Q:plan cache太大,會不會造成查找plan的瓶頸,如何控制cache大小?
A:内部指針用來控制内部單個cache的大小,以免出現性能問題,當架構預測過程最大cache到達了就會移動内部指針。還有當有一些項進入cache,具體多少項根據最大服務記憶體來确定,還有就是機器上的記憶體狀态。
NUMA有2中方式,1:純NUMA,2:交錯是NUMA。NUMA是每個節點都有自己管理的記憶體,本地通路代價比遠端通路代價小。交錯numa是當成SMP通路,适合對NUMA沒有優化的程式。
當配置成純NUMA然後重新開機,windows就會識别,通過觀察發現大多數記憶體都是開辟在第一個節點上,開辟的數量和可用記憶體數量,要啟動的程序有關。這樣的開辟方式會讓記憶體出現不均衡的狀況。
SQL Server Node有自己的記憶體管理和排程個數,io和其他元件,node的線上和離線通過affinity設定。在沒有顯示規定指定那個節點是,是通過環形的方式配置設定。
在SQL變慢,但是plan沒有變化,造成性能下降,往往可能是記憶體的問題引起:
1.Node 0,系統啟動過程中都是使用node 0的記憶體,方法是把node 0 offline
2.其他node,檢視SFC,其他程序記憶體的記憶體消耗,和SQL Server的記憶體消耗。方法:在啟動其他程序前,為sql server通過設定min,max一樣來保留記憶體。
3.錯誤的配置SFC,導緻記憶體的大量消耗。
本文大意:
Memory Broker:用來調整buffer pool,query execution,query優化,cache之間的記憶體配置設定,讓記憶體更有效的使用。根據元件的記憶體需求調整記憶體配置設定,計算最優配置設定方案,然後廣播到clerk。
SELECT *
FROM sys . dm_os_ring_buffer
WHERE ring_buffer_type = 'RING_BUFFER_MEMORY_BROKER'
NUMA:SQL Server 當本地無法配置設定記憶體的時候會從其他有記憶體的節點配置設定記憶體。每個節點記憶體配置設定為max/Nodes 如果設定了affinity那麼就是 max/affinity Nodes
<a href="http://blogs.msdn.com/b/slavao/archive/2005/11/15/493066.aspx">Q and A: Virtual Address Space, VAS, reservation - why bother?</a>
Q1:經常提到保留但是沒有送出是講的是VAS嗎?
A1:是講的是VAS,如當查詢執行需要記憶體,那麼就會去buffer pool裡面保留記憶體,這個和VAS的保留和送出時2回事。
Q2:為什麼不在保留的時候直接送出記憶體,而是需要先保留然後再送出
A2:先保留的理由有2個1:因為有很多的送出方式,如:AWE,file map等。2:VAS有限,以免發生不必要的争用。
Q3:保留的VAS能收縮或者增長嗎?
A3:一旦被保留就不能grow,收縮,隻能一起釋放。
Q4:當VAS保留了,但是配置設定不到記憶體會發生什麼情侶:
A4:造成這個往往是記憶體不足引起,會記錄在錯誤日志上面,ring_buffer也會有一些錯誤,會有OOM通知。
Q1:時鐘指針到底是幹嘛用的?和lazywrite有關系嗎?
A1:2005把cache分為2部分,BP和其他cache,lazywrite還是會控制資料頁的記憶體消耗。在2005中引入了通用的cache架構,除了buffer pool之外都會使用這個,這個架構是由RM和一系列store組成,有3中store:cache,user,object。cache,user使用通用的基于cost的LRU算法,object隻是一個pool不需要LRU算法和Cost。時鐘指針所過之處,cost減半,當cost變0,就可以銷毀了,當要重用的時候重新設定cost。指針分為2中:1.全局(外部),以全局記憶體做LRU算法。2.本地(内部):以本元件記憶體做LRU算法。盡管每個cache都有外部,但是都是同時運作的,就是為了模拟全局指針。RM通過通知記憶體壓力來驅動外部指針。内部指針在cache需要被裁剪的時候運作,保證cache的記憶體占用的合理大小。
Q1:在sql server2000的MemToLeave的概念是否在64Bit下是否繼續可用?
A1:是的,當元件需求大于8kb的時候還是會從MemToleave中配置設定。
Q2:大于8KB在MEMToLeave配置設定,那麼在64位下還是如此嗎?
A2:還是一樣的8KB一樣的會從MemToLeave配置設定,但是有的時候如果資料結構過大的,也會直接從MemToLeave配置設定
Q: 在我的2005中,開啟了Page Lock碰到了一個問題,我懷疑是記憶體都沒2005占用沒有釋放,倒是可用記憶體不足,導緻伺服器僵死。如何能和2000一樣當出現記憶體壓力的時候可以釋放呢?
A: 在2005中不管是不是Page lock都會對記憶體壓力做出反應。沒有釋放記憶體可能是沒有cpu時鐘去運作釋放的問題造成。對于page lock的要設定max server memory,有幾個max server memory的建議配置:
< 4GB 512MB - 1GB
4-32GB 1GB - 2GB
32GB - 128GB 2GB-4GB
128GB - 4GB-
有記下幾點要注意:
1.當伺服器運作在記憶體的邊界,需要設定max server memroy
2.在高峰期的時候,注意,你的max server memory是否設定在一個合理的值中
3.記憶體越多max的設定越重要
4.通過測試,或者基線尋址自己的max server memory
5.max worker thread,stacj 在32為512KB,在64為2MB,在IA64中為4mb,是以設定的時候注意是否會引起記憶體問題
6.max server memory 隻對BP起作用,對其他元件沒有作用
7.對于外部元件,如xps,com的記憶體配置設定不受max server memory控制
![【MySQL資料庫】資料庫索引事務1.索引2.事務[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)