本篇文章介紹了 torch 的一個核心——autograd,其中 autograd 中的 variable 和 Tensor 都屬于 torch 中的基礎資料結構,variable 封裝了 Tensor ,擁有着和 Tensor 幾乎一樣的接口,并且提供了自動求導技術。autograd 是 torch 的自動微分引擎,采用動态計算圖的技術,可以更高效的計算導數。 這篇文章說實話是有點偏難的,可以多看幾遍,尤其是對于還沒有寫過實際項目的小白,不過相信有前面幾個小項目練手,以及最後一個線性回歸的小 demo,相信你差也不差的能看懂,但這都不要緊,在未來的項目實戰中,你将會對 autograd 的體會越來越深刻。
0501-Variable
目錄
一、Variable
1.1 Variable 的資料結構
1.2 反向傳播
1.3 autograd 求導數和手動求導數
pytorch完整教程目錄:https://blog.51cto.com/u_13804357/2794310
一、Variable
autograd 子產品的核心資料結構是 Variable,它是對 tensor 的封裝,并且會記錄 tensor 的操作記錄用來建構計算圖。Variable 的資料結構如下圖所示:
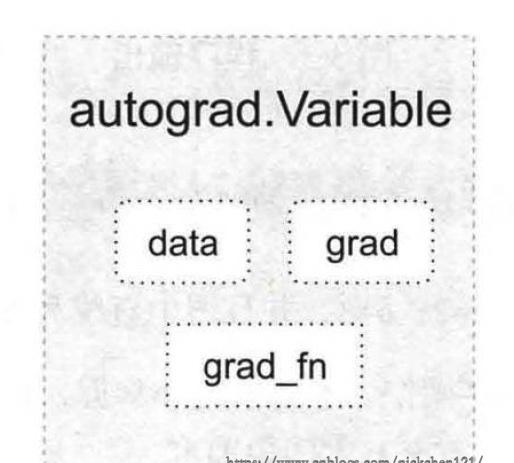
上圖主要包含三個屬性:
data:儲存 variable 所包含的 tensor
grad:儲存 data 對應的梯度,grad 也是 variable,而非 tensor,它與 data 形狀一緻
grad_fn:指向一個 Function,記錄 variable 的操作曆史,即它是什麼操作的輸出,用來建構計算圖。如果某一變量是使用者建立的,則它為葉子節點,對應的 grad_fn 為 None
Variable 的構造函數需要傳入 tensor,也有兩個可選的參數:
requires_grad(bool):是否需要對該 Variable 求導
volatile(bool):設定為 True,建構在該 Variable 之上的圖都不會求導
Variable 支援大部分 tensor 支援的函數,但不支援部分 inplace 函數,因為它們會修改 tensor 自身,然而在反向傳播中,Variable 需要緩存原來的 tensor 計算梯度。如果想要計算各個 Variable 的梯度,隻需要調用根結點的 backward 方法,autograd 則會自動沿着計算圖反向傳播,計算每一個葉子節點的梯度。
<code>variable.backward(grad_variable=None, retain_fraph=None, create_graph=None)</code>的參數解釋如下:
grad_variables:形狀與 Variable 一直,對于 <code>y.backward()</code>,grad_variables 相當于鍊式法則\(\frac{\partial{z}}{\partial{x}} = \frac{\partial{z}}{\partial{y}}\frac{\partial{y}}{\partial{x}}\)。grad_variables 也可以是 tensor 或序列
retain_graph:反向傳播會緩存一些中間結果,反向傳播之後,這些緩存就會清除,可通過這個參數指定不清除緩存,用來多次反向傳播
create_graph:對反向傳播過程中再次建構計算圖
通過對函數\(y=x^2e^x\)求導,我們可以看看 autograd 求導數和自己寫個方法求導數的差別。這個函數的導數如下:
\[\frac{dy}{dx}=2xe^x+x^2e^x \]
![BP神經網絡推導+示例[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)