個人項目
軟體工程
網工1934連結
作業要求:
1.在Github倉庫中建立一個學号為名的檔案夾
2.在開始實作程式之前,在PSP表格記錄下在程式開發各個步驟耗費時間,實作程式後,在PSP表格記錄各個子產品上實際花費時間
3.語言不限,實作程式後将代碼釋出到Github倉庫的realease中
4.送出的代碼要求經過Code Quality Analysis工具分析并消除所有警告
5.完成項目首個版本之後,使用性能分析工具Studio Profiling Tools找出代碼性能瓶頸
6.使用Github來管理源代碼和測試用例,代碼有進展即簽入Github
7.使用單元測試對項目進行測試,并使用插件檢視測試分支覆寫率等名額
作業要求連結
作業目标:
完成論文查重項目的實作後進行測試并按以上要求使用Github進行版本釋出及源碼和測試用例管理
個人作業github連結
PSP2.1
Personal Software Process Stages
預估耗時(分鐘)
實際耗時(分鐘)
Planning
計劃
· Estimate
· 估計這個任務需要多少時間
405
340
Development
開發
· Analysis
· 需求分析 (包括學習新技術)
100
120
· Design Spec
· 生成設計文檔
30
· Design Review
· 設計複審
10
· Coding Standard
· 代碼規範 (為目前的開發制定合适的規範)
· Design
· 具體設計
40
· Coding
· 具體編碼
80
· Code Review
· 代碼複審
60
20
· Test
· 測試(自我測試,修改代碼,送出修改)
15
Reporting
報告
· Test Repor
· 測試報告
· Size Measurement
· 計算工作量
· Postmortem & Process Improvement Plan
· 事後總結, 并提出過程改進計劃
· 合計
工具類:
FileUtils:檔案工具類,具有讀寫檔案,擷取檔案名等靜态方法
QueryReapeat :查重工具類,具有對兩段字元串進行查重等靜态方法
ResultEditor類:結果處理工具類,具有對查重結果進行處理并傳回的靜态方法
主類:
Application 類 :程式的入口類,其中的main方法可以接收多個參數用來作為輸入輸出檔案的絕對路徑,main方法中調用工具類中的靜态方法實作整個查重功能。
各類之間的關系:
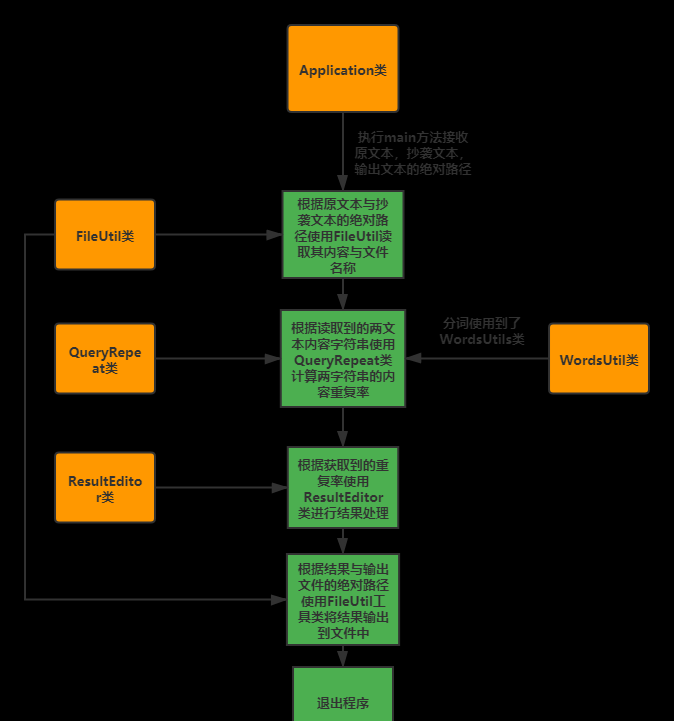
項目結構:

關鍵函數在于如何實作查重函數queryRepeat()?
通過上網查閱資料,參考了TF-IDF與餘弦相似性的應用(二):找出相似文章 這篇博文。
假設有兩個句子A,B
句子A:我喜歡吃蘋果,不喜歡吃榴蓮。
句子B:我不喜歡吃蘋果,也不喜歡吃榴蓮。
第一步,分詞。
句子A:我/喜歡/吃/蘋果,不/喜歡/吃/榴蓮。 句子B:我/不/喜歡/吃/蘋果,也/不/喜歡/吃/榴蓮。
實作:通過IKAnalyzer中文分詞器實作,即通過查詢内置的詞典進行分詞
第二步,列出所有的詞。
我,喜歡,吃,蘋果,榴蓮,不,也。
第三步,計算詞頻。
句子A:我 1,喜歡 2,吃 2,蘋果 1,榴蓮 1,不 1,也 0。 句子B:我 1,喜歡 2,吃 2,蘋果 1,榴蓮 1,不 2,也 1。
第四步,寫出詞頻向量。
句子A:[1, 2, 2, 1, 1, 1, 0] 句子B:[1, 2, 2, 1, 1, 2, 1]
實作:詞與詞頻是鍵值對的形式,是以可以用哈希表來存儲
到這裡,問題就變成了如何計算這兩個向量的相似程度。
我們可以把它們想象成空間中的兩條線段,都是從原點([0, 0, ...])出發,指向不同的方向。兩條線段之間形成一個夾角,如果夾角為0度,意味着方向相同、線段重合;如果夾角為90度,意味着形成直角,方向完全不相似;如果夾角為180度,意味着方向正好相反。是以,我們可以通過夾角的大小,來判斷向量的相似程度。夾角越小,就代表越相似。
則計算A, B向量間的夾角的餘弦值
假定a向量是[x1, y1],b向量是[x2, y2],那麼可以将餘弦定理改寫成下面的形式:
推廣至n維
餘弦值越接近1,說明兩向量間夾角越接近0,即兩個句子越相似,是以餘弦值即為兩句子的相似度
可以看出程式中消耗最大的函數是中文分詞器查詢字典調用的相關函數
使用JUnit4進行單元測試,建立一個TestCoverage類,在其中測試各子產品方法。
測試結果:
空串情況下:
剩餘情況:
通過上面單元測試發現了QueryRepeat.getRepeatRadius("", "")方法會報空指針異常并對其進行了捕獲處理,在控制台輸出了相應報錯資訊。
也可以在Application類加入判斷,當有空串時就退出程式并列印資訊到控制台