(一) 背景資料
GPU就是圖形處理器,是Graphics Processing Unit的縮寫。電腦顯示器上顯示的圖像,在顯示在顯示器上之前。要經過一些列處理,這個過程有個專有的名詞叫“渲染" ,曾經計算機上是沒有GPU的,都是通過CPU來進行“渲染”處理的,這些涉及到“渲染”的計算工作很耗時。占用了CPU的大部分時間。之後出現了GPU,是專門為了實作“渲染”這樣的計算工作的。用來将CPU解放出來,GPU是專為運作複雜的數學和幾何計算而設計的,這些計算是“渲染”所必需的。
以下看看百度百科上CPU同GPU的對照圖。當中綠色的是計算單元:
能夠看出來GPU有大量的計算單元,是以GPU是專門為“渲染”這樣的計算工作設計的。
(二) 應用領域
最開始同GPU相關的應用僅僅是簡單地停留在圖形相關應用上,比方遊戲中3D圖形“渲染”等圖像處理應用。如今GPU的應用已經很廣泛的。在遊戲、娛樂、科研、醫療、網際網路等涉及到大規模計算的領域都有GPU應用的存在。比方高性能計算應用、機器學習應用、人工智能應用、自己主動駕駛應用、虛拟現實應用、自然語言處理應用等等。
1、以下看看Nvidia提供的深度學習領域使用GPU的分析結果:
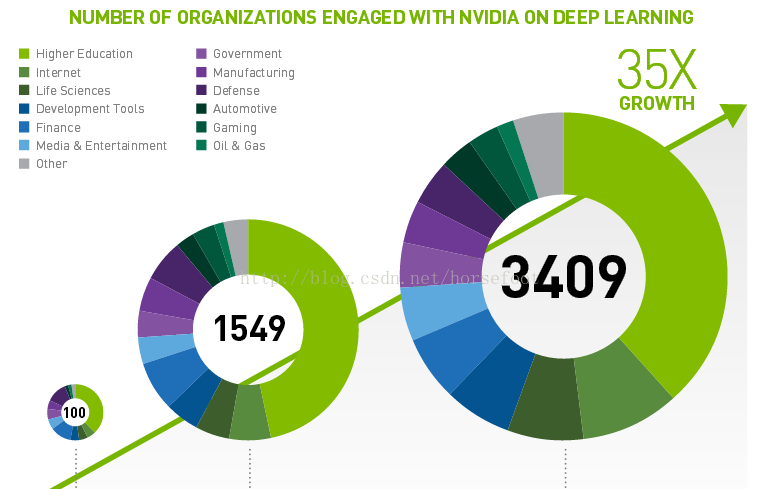
能夠看出來從2013年到2015年在深度學習領域呈現出爆發性增長的趨勢。
2、以下看看Nvidia提供的資料:

使用GPU來實作深度學習應用後,在自己主動駕駛、醫療診斷和機器學習三方面效率提高的十分明顯。
(三) Kubernetes 1.3中支援GPU的實作
在kubernetes1.3中提供了對Nvidia品牌GPU的支援,在kubernetes管理的叢集中每一個節點上,通過将原有的Capacity和Allocatable變量進行擴充,添加了一個針對Nvidia品牌GPU的α特性:alpha.kubernetes.io/nvidia-gpu。當中Capacity變量表示每一個節點中實際的資源容量,包含cpu、memory、storage、alpha.kubernetes.io/nvidia-gpu。而Allocatable變量表示每一個節點中已經配置設定的資源容量。相同包含包含cpu、memory、storage、alpha.kubernetes.io/nvidia-gpu。
在啟動kubelet的時候,通過添加參數--experimental-nvidia-gpu來将帶有GPU的節點加入到kubernetes中進行管理。
這個參數experimental-nvidia-gpu用來告訴kubelet這個節點中Nvidia品牌GPU的個數。假設為0表示沒有Nvidia品牌GPU,假設不添加這個參數,那麼系統默覺得這個節點上沒有Nvidia品牌GPU。
當節點上安裝有多塊Nvidia品牌GPU的時候,參數experimental-nvidia-gpu是能夠輸入大于1的數值的。可是對于kubernetes1.3這個版本号,GPU還是個α特性。在代碼中參數experimental-nvidia-gpu事實上僅僅支援兩個值。各自是0和1,我們通過以下代碼就能夠看出來:
在執行docker的時候,須要映射節點上的裝置到docker中,這段代碼是在告訴docker,僅僅映射第一塊Nvidia品牌GPU。通過上面代碼能夠看出來,在kubernetes1.3中。GPU這個α特性,參數experimental-nvidia-gpu事實上僅僅支援兩個值,各自是0和1。通過上面代碼也能夠看出來,為什麼在kubernetes1.3中僅僅支援Nvidia品牌GPU,對于不同品牌的GPU,映射到linux作業系統裡面有着不同的裝置路徑,須要針對不同的GPU品牌分别進行實作。
(四) Kubernetes 1.6中支援GPU的實作
在kubernetes1.6中更全面的提供了對Nvidia品牌GPU的支援,保留了kubernetes1.3中針對Nvidia品牌GPU的α特性:alpha.kubernetes.io/nvidia-gpu,可是在啟動kubelet的時候。去掉了參數--experimental-nvidia-gpu,改成了通過配置Accelerators為true來啟動這個α特性,完整的啟動參數是--feature-gates="Accelerators=true"。
在kubernetes1.3中僅僅能利用節點上的一顆NvidiaGPU,可是在kubernetes1.6中會自己主動識别節點上的全部Nvidia GPU,并進行排程。
從上面代碼中就能夠看出來。在1.6中能夠擷取節點中全部NvidiaGPU裝置。
以下是1.6中在kubelet中添加的Nvidia GPU相關結構體:
在nvidiaGPUManager這個結構體中,allGPUs變量表示這個節點上全部的GPU資訊;allocated變量表示這個節點上已經被配置設定使用的GPU資訊,這個allocated變量是一個podGPUs結構體變量,用來表示POD同已使用GPU的相應關系。dockerClient變量是docker接口變量,用來表示全部使用GPU的docker。activePodsLister變量表示這個節點上全部活動狀态的POD,通過這個變量,能夠釋放已經處于終止狀态POD所綁定的GPU資源。
在kubernetes中Nvidia GPU這個特性僅僅是在容器是docker的時候才生效。假設容器使用的是rkt,是無法使用到Nvidia GPU的。
在1.6中能夠參照以下例子使用Nvidia GPU:
能夠看到。在1.6中使用GPU的時候,不同docker之間是無法共享GPU的。也就是說每一個docker都會獨占整個GPU,并且事實上還須要kubernetes叢集中全部節點上面的NvidiaGPU類型都是同樣的,假設在一個叢集中有的不同節點上面的Nvidia GPU類型不同。那麼還須要給排程器配置節點标簽和節點選擇器。用來區分不同Nvidia GPU類型的節點。
在節點啟動時,能夠指明Nvidia GPU類型,而且作為節點标簽傳遞給kubelet。例如以下所看到的:
在使用的時候,能夠參考以下例子:
在這個例子中,利用到了節點親和性規則,保證POD僅僅能使用GPU類型是"TeslaK80"或"Tesla P100"的節點。
假設已經在節點上安裝了CUDA(Compute UnifiedDevice Architecture。是顯示卡廠商NVIDIA推出的運算平台。
CUDA™是一種由NVIDIA推出的通用并行計算架構。該架構使GPU可以解決複雜的計算問題。它包括了CUDA指令集架構以及GPU内部的并行計算引擎),那麼POD可以通過hostPath卷插件來訪問CUDA庫:
(五) 未來展望
以後會逐漸完好這個α特性,讓GPU成為kubernetes中原生計算資源的一部分,并且會提高使用GPU資源的友善性,還會讓kubernetes自己主動確定使用GPU的應用能夠達到最佳性能。
随着機器學習的火熱,為了支撐各種以GPU為主的機器學習計算平台。相信kubernetes在GPU處理上還會繼續高速完好,逐漸成為機器學習的底層編排架構。