TopN 是統計報表和大屏非常常見的功能,主要用來實時計算排行榜。流式的 TopN 不同于批處理的 TopN,它的特點是持續的在記憶體中按照某個統計名額(如出現次數)計算 TopN 排行榜,然後當排行榜發生變化時,發出更新後的排行榜。本文主要講解 Flink SQL 是如何從文法和實作上設計 TopN 的。
使用者最關心的是如何用 SQL 寫出 TopN 的查詢。大家最熟悉的 TopN 的寫法一般是這樣的:
如上文法是 MySQL 的 TopN 文法,使用 <code>ORDER BY</code> 指定排序鍵和排序方向,使用 <code>LIMIT</code> 來指定選出前幾名。不同的資料庫的 TopN 文法不盡相同,比如 MS SQL Server 使用 TOP 的關鍵字,Oracle 使用 ROWNUM 的隐藏字段。不過幾家資料庫提供的 TopN 文法都是全局 TopN,也就是資料是全局進行排序的,查詢的結果隻有一組排行榜。比如希望對全網商家按銷售額排序,計算出銷售額排名前十的商家。這就是全局 TopN,範例如下:
上文講述了全局 TopN 的文法,但是很多時候使用者希望根據不同的分組進行排序,計算出每個分組的一個排行榜。例如對全網商家根據行業按銷售額排序,計算出每個行業銷售額前十名的商家。這時候,傳統的 TopN 文法就無法表達這種需求了。有些 Stream SQL 系統為了解決這個問題,會 hack 一種新的 TopN 文法允許使用者指定分組字段。但是 Flink SQL 是基于 ANSI SQL 标準文法的,不能加入任何非标準的文法。于是我們嘗試從批處理的角度去思考這個問題,在傳統批進行中常用 ROW_NUMBER 的開窗聚合函數來解決分組 TopN 的問題。文法如下所示:
參數說明:
<code>ROW_NUMBER()</code>: 是一個計算行号的OVER視窗函數,行号計算從1開始。
<code>PARTITION BY col1[, col2..]</code> : 指定分區的列,可以不指定。
<code>ORDER BY col1 [asc|desc][, col2 [asc|desc]...]</code>: 指定排序的列,可以多列不同排序方向。
如上文法所示,TopN 需要兩層 query,子查詢中使用<code>ROW_NUMBER()</code>開窗函數來為每條資料标上排名,排名的計算根據<code>PARTITION BY</code>和<code>ORDER BY</code>來指定分區列和排序列,也就是說每一條資料會計算其在所屬分區中,根據排序列排序得到的排名。在外層查詢中,對排名進行過濾,隻取出排名小于 N 的,如 N=10,那麼就是取 Top 10 的資料。如果沒有指定<code>PARTITION BY</code>那麼就是一個全局 TopN 的計算,是以 ROW_NUMBER 在使用上更為靈活。
ROW_NUMBER 方式的 TopN 文法非常靈活,能滿足全局 TopN 和分組 TopN 的需求。但是在流計算上的實體執行是一個挑戰。如上文所述的每個行業銷售額前十商家排行榜,經過 SQL 編譯後得到的抽象文法樹(AST)如下所示。
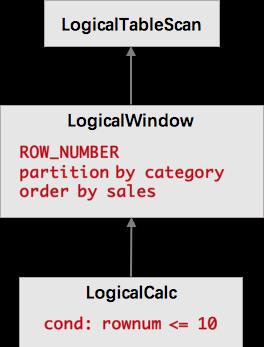
LogicalWindow 會對所有資料進行排名,也就是說每當到達一個資料,就要對曆史資料進行重排序,并輸出曆史資料的新的排名,然後 LogicalCalc 節點會根據排名進行過濾。這在性能上是非常糟糕的,因為這無限放大了流量。而我們知道,最優的流式 TopN 的計算隻需要維護一個 N 元素大小的小根堆,每當有資料到達時,隻需要與堆頂元素比較,如果比堆頂元素還小,則直接丢棄;如果比堆頂元素大,則更新小根堆,并輸出更新後的排行榜。也就是說我們不需要分為兩個節點進行計算,不需要将所有資料進行排序,隻需要在一個節點中就可以高效地完成計算。是以我們在查詢優化器中加入了一條規則,在使用 TopN 文法時,将 LogicalWindow 和 LogicalCalc 合并成了 LogicalRank 節點。LogicalRank 在翻譯成實體執行計劃時,會使用一個經過特殊設計的 TopN 算子。

TopN 算子的實作上主要有兩個資料結構,一個是 TreeMap,另一個是 MapState。TreeMap 的作用類似于上文的小根堆,有序地存放了排名前 N 的元素。但是 TreeMap 是個記憶體資料結構,在 failover 後會丢失,無法保證資料的一緻性。是以我們還有一個 MapState 結構,MapState 是 Flink 提供的狀态接口,用來存儲 TopN 的資料(保證資料不丢)。當有 failover 發生後,MapState 能保證狀态的恢複,而 TreeMap 會從 MapState 中重新構造出來。我們并有沒有把順序也存到狀态中去,因為順序是可以在恢複時重構的。因為每一次狀态的讀寫操作都會涉及到序列化/反序列化,往往是性能的瓶頸,是以 TreeMap 的主要作用是降低了對 MapState 狀态的讀寫操作。對大部分資料來說都是與 TreeMap 進行互動,不需要對 MapState 進行讀寫的,全是記憶體操作,是以 TopN 的性能是非常高的。
TopN 算子的主要處理流程是,每當有資料到達時,會與 TreeMap 的最小的元素比較,如果比它小,那麼該資料就不可能是 TopN 的一員,直接丢棄即可。如果比它大,那麼就會先更新 TreeMap,同時更新 MapState 中的存的資料。最後輸出更新後的排行榜。為了減少備援資料的輸出,我們隻會輸出排名發生變化的資料。例如原先的第7名上升到了第六名,那麼隻需要輸出新的第六名和第七名即可。
TopN 的計算與 GroupBy 的計算類似,如果資料存在傾斜,則會有計算熱點的現象。比如全局 TopN,那麼所有的資料隻能彙集到一個節點進行 TopN 的計算,那麼計算能力就會受限于單台機器,無法做到水準擴充。解決思路與 GroupBy 是類似的,就是使用嵌套 TopN,或者說兩層 TopN。在原先的 TopN 前面,再加一層 TopN,用于分散熱點。例如,計算全網排名前十的商鋪,會導緻單點的資料熱點,那麼可以先加一層分組 TopN,組的劃分規則是根據店鋪 ID 哈希取模後分成128組(并發的倍數)。第二層 TopN 與原先的寫法一樣,沒有 PARTITION BY。第一層會計算出每一組的 TopN,而後在第二層中進行合并彙總,得到最終的全網前十。第二層雖然仍是單點,但是大量的計算量由第一層分擔了,而第一層是可以水準擴充的。使用嵌套 TopN 的優化寫法如下所示: