企業級解決方案
緩存預熱
緩存雪崩
緩存擊穿
緩存穿透
性能名額監控
“當機”
伺服器啟動後迅速當機
問題排查
請求數量較高
主從之間資料吞吐量較大,資料同步操作頻度較高
前置準備工作:
日常例行統計資料通路記錄,統計通路頻度較高的熱點資料
利用LRU資料删除政策,建構資料留存隊列
例如:storm與kafka配合
準備工作:
将統計結果中的資料分類,根據級别,redis優先加載級别較高的熱點資料
利用分布式多伺服器同時進行資料讀取,提速資料加載過程
熱點資料主從同時預熱
實施:
使用腳本程式固定觸發資料預熱過程
如果條件允許,使用了CDN(内容分發網絡),效果會更好
總結
緩存預熱就是系統啟動前,提前将相關的緩存資料直接加載到緩存系統。避免在使用者請求的時候,先查詢資料庫,然後再将資料緩
存的問題!使用者直接查詢事先被預熱的緩存資料
資料庫伺服器崩潰(1)
系統平穩運作過程中,忽然資料庫連接配接量激增
應用伺服器無法及時處理請求
大量408,500錯誤頁面出現
客戶反複重新整理頁面擷取資料
資料庫崩潰
應用伺服器崩潰
重新開機應用伺服器無效
Redis伺服器崩潰
Redis叢集崩潰
重新開機資料庫後再次被瞬間流量放倒
在一個較短的時間内,緩存中較多的key集中過期
此周期内請求通路過期的資料,redis未命中,redis向資料庫擷取資料
資料庫同時接收到大量的請求無法及時處理
Redis大量請求被積壓,開始出現逾時現象
資料庫流量激增,資料庫崩潰
重新開機後仍然面對緩存中無資料可用
Redis伺服器資源被嚴重占用,Redis伺服器崩潰
Redis叢集呈現崩塌,叢集瓦解
應用伺服器無法及時得到資料響應請求,來自用戶端的請求數量越來越多,應用伺服器崩潰
應用伺服器,redis,資料庫全部重新開機,效果不理想
問題分析
短時間範圍内
大量key集中過期
更多的頁面靜态化處理
建構多級緩存架構
Nginx緩存+redis緩存+ehcache緩存
檢測Mysql嚴重耗時業務進行優化
對資料庫的瓶頸排查:例如逾時查詢、耗時較高事務等
災難預警機制
監控redis伺服器性能名額
CPU占用、CPU使用率
記憶體容量
查詢平均響應時間
線程數
限流、降級
短時間範圍内犧牲一些客戶體驗,限制一部分請求通路,降低應用伺服器壓力,待業務低速運轉後再逐漸放開通路
LRU與LFU切換
資料有效期政策調整
根據業務資料有效期進行分類錯峰,A類90分鐘,B類80分鐘,C類70分鐘
過期時間使用固定時間+随機值的形式,稀釋集中到期的key的數量
超熱資料使用永久key
定期維護(自動+人工)
對即将過期資料做通路量分析,确認是否延時,配合通路量統計,做熱點資料的延時
加鎖
慎用
緩存雪崩就是瞬間過期資料量太大,導緻對資料庫伺服器造成壓力。如能夠有效避免過期時間集中,可以有效解決雪崩現象的出現(約40%),配合其他政策一起使用,并監控伺服器的運作資料,根據運作記錄做快速調整
資料庫伺服器崩潰(2)
系統平穩運作過程中
資料庫連接配接量瞬間激增
Redis伺服器無大量key過期
Redis記憶體平穩,無波動
Redis伺服器CPU正常
Redis中某個key過期,該key通路量巨大
多個資料請求從伺服器直接壓到Redis後,均未命中
Redis在短時間内發起了大量對資料庫中同一資料的通路
單個key高熱資料
key過期
預先設定
以電商為例,每個商家根據店鋪等級,指定若幹款主打商品,在購物節期間,加大此類資訊key的過期時長
注意:購物節不僅僅指當天,以及後續若幹天,通路峰值呈現逐漸降低的趨勢
現場調整
監控通路量,對自然流量激增的資料延長過期時間或設定為永久性key
背景重新整理資料
啟動定時任務,高峰期來臨之前,重新整理資料有效期,確定不丢失
二級緩存
設定不同的失效時間,保障不會被同時淘汰就行
分布式鎖,防止被擊穿,但是要注意也是性能瓶頸,慎重!
緩存擊穿就是單個高熱資料過期的瞬間,資料通路量較大,未命中redis後,發起了大量對同一資料的資料庫通路,導緻對資料庫服
務器造成壓力。應對政策應該在業務資料分析與預防方面進行,配合運作監控測試與即時調整政策,畢竟單個key的過期監控難度
較高,配合雪崩處理政策即可。
資料庫伺服器崩潰(3)
應用伺服器流量随時間增量較大
Redis伺服器命中率随時間逐漸降低
Redis記憶體平穩,記憶體無壓力
Redis伺服器CPU占用激增
資料庫伺服器壓力激增
Redis中大面積出現未命中
出現非正常URL通路
擷取的資料在資料庫中也不存在,資料庫查詢未得到對應資料
Redis擷取到null資料未進行持久化,直接傳回
下次此類資料到達重複上述過程
出現黑客攻擊伺服器
緩存null
對查詢結果為null的資料進行緩存(長期使用,定期清理),設定短時限,例如30-60秒,最高5分鐘
白名單政策
提前預熱各種分類資料id對應的bitmaps,id作為bitmaps的offset,相當于設定了資料白名單。當加載正常資料時,放
行,加載異常資料時直接攔截(效率偏低)
使用布隆過濾器(有關布隆過濾器的命中問題對目前狀況可以忽略)
實施監控
實時監控redis命中率(業務正常範圍時,通常會有一個波動值)與null資料的占比
非活動時段波動:通常檢測3-5倍,超過5倍納入重點排查對象
活動時段波動:通常檢測10-50倍,超過50倍納入重點排查對象
根據倍數不同,啟動不同的排查流程。然後使用黑名單進行防控(營運)
key加密
問題出現後,臨時啟動防災業務key,對key進行業務層傳輸加密服務,設定校驗程式,過來的key校驗
例如每天随機配置設定60個加密串,挑選2到3個,混淆到頁面資料id中,發現通路key不滿足規則,駁回資料通路
緩存擊穿通路了不存在的資料,跳過了合法資料的redis資料緩存階段,每次通路資料庫,導緻對資料庫伺服器造成壓力。通常此類資料的出現量是一個較低的值,當出現此類情況以毒攻毒,并及時報警。應對政策應該在臨時預案防範方面多做文章。
無論是黑名單還是白名單,都是對整體系統的壓力,警報解除後盡快移除
監控名額
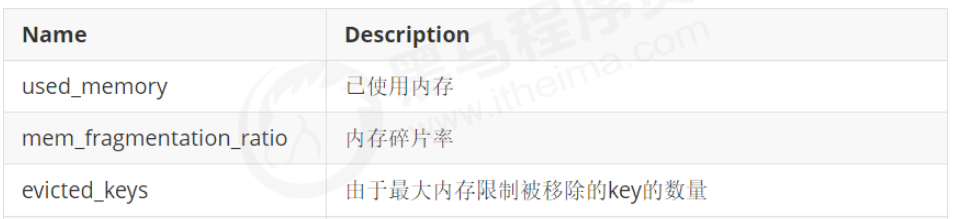
性能名額:Performance
記憶體名額:Memory
基本活動名額:Basic activity
持久性名額:Persistence
錯誤名額:Error

工具
Cloud Insight Redis
Prometheus
Redis-stat
Redis-faina
RedisLive
zabbix
指令
benchmark
redis cli
monitor
showlog
redis-benchmark [-h ] [-p ] [-c ] [-n [-k ]
範例1
redis-benchmark
說明:50個連接配接,10000次請求對應的性能
範例2
redis-benchmark -c 100 -n 5000
說明:100個連接配接,5000次請求對應的性能
列印伺服器調試資訊
showlong [operator]
get :擷取慢查詢日志
len :擷取慢查詢日志條目數
reset :重置慢查詢日志
相關配置
slowlog-log-slower-than 1000 #設定慢查詢的時間下線,機關:微妙 slowlog-max-len 100 #設定慢查詢指令對應的日志顯示長度,機關:指令數