0. 科普
1. 為什麼需要Bloom Filter
2. 基本原理
3. 如何設計Bloom Filter
4. 執行個體操作
5. 擴充
Bloom Filter是由Bloom在1970年提出的一種多哈希函數映射的快速查找算法。通常應用在一些需要快速判斷某個元素是否屬于集合,但是并不嚴格要求100%正确的場合。
舉例說明:假設有2000萬個url,現在判斷一個新的url是否在這2000萬個之中。可以有的思路:
将通路過的URL儲存到資料庫。
用HashSet将通路過的URL儲存起來。那隻需接近O(1)的代價就可以查到一個URL是否被通路過了。
URL經過MD5等單向哈希後再儲存到HashSet或資料庫。
Bit-Map方法。建立一個BitSet,将每個URL經過一個哈希函數映射到某一位。
分析
思路1:當資料量很大時,查詢資料庫變得效率底下
思路2:太消耗記憶體,還得把字元串全部儲存起來
思路3:字元串經過MD5處理後有128個bit,比思路2省了很多空間
思路4:一個字元串僅用一位來表示,比思路3還節省空間
當然前提是會出現誤判(哈希後表示相同),為了繼承這麼好的思路,同時減少誤判的情況,可以來個折衷:一個哈希函數生成一個位,用多個哈希函數生成多個位來存儲一個字元串。這樣比Bit-Map多用了些空間,但是減少了誤判率。
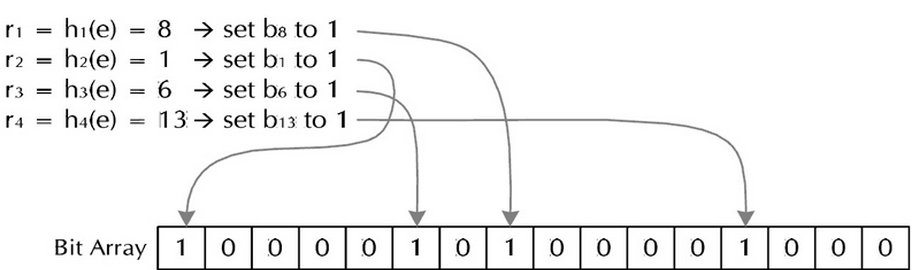
這樣把大量的字元串存起來。查找時,用同樣的哈希處理待查串,如果對應的各位上都為1,說明該字元串可能在這些字元串中,否則一定不在其中。
如何降低誤判率是關鍵,這需要
選取區分度高的哈希函數
根據存儲數組、哈希函數個數、誤判率之間的關系,配置設定空間、個數
直接利用前人的結論:

其中f'是自己期望的誤判率,m是總共開辟的存儲空間位數,n是待存儲字元串的個數,k是哈希函數的個數,f是真正的誤判率。
需求:2000萬個已知url,100個待查url
設計:
1. 設定誤判率為0.1, n=2000萬,計算
參考代碼(c++)
makefile
View Code
main.cc
bloomfilter.h
bloomfilter.cc
hash.h
hash.cc
如何删除存儲數組中的元素?
思路:把存儲數組的每一個元素擴充一下(原來是1b)用來存儲該位置被置1的次數。存儲是,計數次數加一;删除的時候,計數次數減一。
本文轉自jihite部落格園部落格,原文連結:http://www.cnblogs.com/kaituorensheng/p/3669140.html,如需轉載請自行聯系原作者