0. 科普
1. 为什么需要Bloom Filter
2. 基本原理
3. 如何设计Bloom Filter
4. 实例操作
5. 扩展
Bloom Filter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。
举例说明:假设有2000万个url,现在判断一个新的url是否在这2000万个之中。可以有的思路:
将访问过的URL保存到数据库。
用HashSet将访问过的URL保存起来。那只需接近O(1)的代价就可以查到一个URL是否被访问过了。
URL经过MD5等单向哈希后再保存到HashSet或数据库。
Bit-Map方法。建立一个BitSet,将每个URL经过一个哈希函数映射到某一位。
分析
思路1:当数据量很大时,查询数据库变得效率底下
思路2:太消耗内存,还得把字符串全部储存起来
思路3:字符串经过MD5处理后有128个bit,比思路2省了很多空间
思路4:一个字符串仅用一位来表示,比思路3还节省空间
当然前提是会出现误判(哈希后表示相同),为了继承这么好的思路,同时减少误判的情况,可以来个折衷:一个哈希函数生成一个位,用多个哈希函数生成多个位来存储一个字符串。这样比Bit-Map多用了些空间,但是减少了误判率。
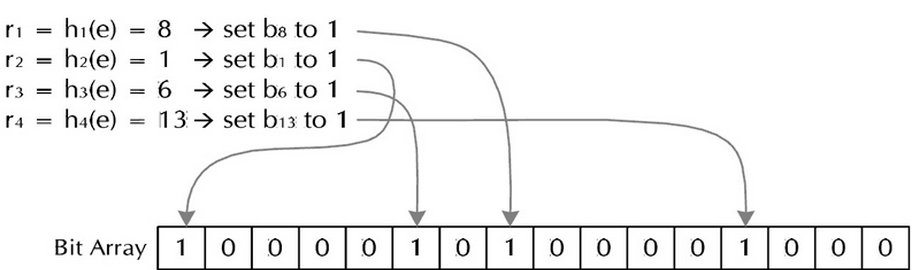
这样把大量的字符串存起来。查找时,用同样的哈希处理待查串,如果对应的各位上都为1,说明该字符串可能在这些字符串中,否则一定不在其中。
如何降低误判率是关键,这需要
选取区分度高的哈希函数
根据存储数组、哈希函数个数、误判率之间的关系,分配空间、个数
直接利用前人的结论:

其中f'是自己期望的误判率,m是总共开辟的存储空间位数,n是待存储字符串的个数,k是哈希函数的个数,f是真正的误判率。
需求:2000万个已知url,100个待查url
设计:
1. 设定误判率为0.1, n=2000万,计算
参考代码(c++)
makefile
View Code
main.cc
bloomfilter.h
bloomfilter.cc
hash.h
hash.cc
如何删除存储数组中的元素?
思路:把存储数组的每一个元素扩展一下(原来是1b)用来存储该位置被置1的次数。存储是,计数次数加一;删除的时候,计数次数减一。
本文转自jihite博客园博客,原文链接:http://www.cnblogs.com/kaituorensheng/p/3669140.html,如需转载请自行联系原作者