記錄日期: 2014-07-30 14:25:27
原sql語句:
INSERT INTO RISKREPT.BASE_FMLG (BATCH_DATE, DATE_STAMP_ST, TIME_STAMP_ST, ORG, ACCT, CARD_NBR, CARD_SEQ, MER_ORG, MER_NBR, REQUEST_TYPE_ID, LOGO, SYSTEM_ACTION, FINAL_ACTION, ACTION_REASON, REVERSAL_REASON, AVAIL_CR, CASH_AVAIL_CR, ACCT_CURR_BAL, ACCT_CURR_BAL_CASH, B007_GMT_DATE_TIME, B018_MER_TYPE, B019_CNTRY_CODE, B032_ACQ_ID, B033_FWD_ID, AUTH_CODE, B039_RESP_CODE, B041_CRD_ACCPT_TERM, B042_TERMTYPE2_MER_ID, B043_CRD_ACCPT_NAM, B043_CRD_ACCPT_CITY, B043_CRD_ACCPT_ST_CTRY, MESSAGE_TYPE_ID, RECORD_TYPE, SALES_AMT_RMB, TOTAL_SALES_AMT, B049_CURR_CODE, BLING_AMT, POS_ENTRY_MODE, PIN_ENTRY_MODE, TRADE_INTERNET, SALES_CTRY, SALES_CTRY_NAME, SALES_CITY, SALES_CITY_NAME, SALES_LINK, MER_CODE, MER_MCC, MER_NAM, ACQ_NAME, REVCODE, AUTH_TYPE, REF_NBR, VI_B011_SYS_AUDT_TRCE, CARD_TYPE, STAGE_TYPE, STAGE_NUM, OVERSEA_FLAG, RISK_FCD, RISK_LCD) SELECT BATCH_DATE, DATE_STAMP_ST, TIME_STAMP_ST, ORG, ACCT, CARD_NBR, CARD_SEQ, MER_ORG, MER_NBR, REQUEST_TYPE_ID, LOGO, SYSTEM_ACTION, FINAL_ACTION, ACTION_REASON, REVERSAL_REASON, AVAIL_CR, CASH_AVAIL_CR, ACCT_CURR_BAL, ACCT_CURR_BAL_CASH, B007_GMT_DATE_TIME, B018_MER_TYPE, B019_CNTRY_CODE, B032_ACQ_ID, B033_FWD_ID, AUTH_CODE, B039_RESP_CODE, B041_CRD_ACCPT_TERM, B042_TERMTYPE2_MER_ID, B043_CRD_ACCPT_NAM, B043_CRD_ACCPT_CITY, B043_CRD_ACCPT_ST_CTRY, MESSAGE_TYPE_ID, RECORD_TYPE, SALES_AMT_RMB, TOTAL_SALES_AMT, B049_CURR_CODE, BLING_AMT, POS_ENTRY_MODE, PIN_ENTRY_MODE, TRADE_INTERNET, SALES_CTRY, SALES_CTRY_NAME, SALES_CITY, SALES_CITY_NAME, SALES_LINK, MER_CODE, MER_MCC, MER_NAM, ACQ_NAME, REVCODE, AUTH_TYPE, REF_NBR, VI_B011_SYS_AUDT_TRCE, CARD_TYPE, STAGE_TYPE, STAGE_NUM, OVERSEA_FLAG, SYSDATE, SYSDATE FROM TEMP_FMLG_PURGE
原sql執行計劃非常簡單:
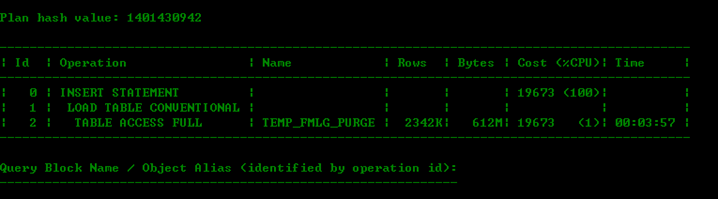
該語句是job中的語句,每天都需要跑的,其曆史執行時間如下圖,可以看出執行時間非常長的都是user_io_wait等待比較嚴重的一些:

檢視一下相關表的屬性和資料量:
SELECT v.OWNER,
v.TABLE_NAME,
v.partitioned,
v.LAST_ANALYZED,
v.NUM_ROWS,
v.table_size2 ,
v.EMPTY_BLOCKS
FROM vw_table_lhr v
WHERE v.TABLE_NAME IN ('BASE_FMLG',
'TEMP_FMLG_PURGE');
BASE_FMLG有15億的資料量,是個分區表,每次從TEMP_FMLG_PURGE中取數,TEMP_FMLG_PURGE大約有234W的資料量,
索引資訊:
SELECT v.index_owner,
v.index_name,
v.index_type,
v.索引列,
v.index_size,
v.num_rows
FROM vw_table_index_lhr v
被插入的表有5個索引,且都是分區索引,不涉及全局索引,涉及到的分區索引:
select v.index_owner,
v.partition_size,
from vw_table_index_part2_lhr V
where V.TABLE_NAME='BASE_FMLG'
and v.PARTITION_NAME='P201407' ;
查一下資料來源:
SELECT t.BATCH_DATE,
COUNT(1)
FROM TEMP_FMLG_PURGE t
GROUP BY t.BATCH_DATE;
看來,都是當天的資料,是以隻涉及到分區表的單個分區
select v.PARTITION_NAME,
v.partition_size ,
v.EMPTY_BLOCKS,v.LOGGING
from VW_TABLE_PART_LHR V
where V.TABLE_NAME='BASE_FMLG';
系統預估剩餘時間:select * from VW_LONGRUN_LHR a where a.SQL_ID='2pnas8zbxtk3a';
插入200W的資料到一個單個分區16G的分區表中需要花費将近12個小時,似乎慢了點。。。。。
問題解決:
查詢會話的統計資訊,發現redo的産生量非常的大,是以解決辦法:
第一步: 将表修改為nologging屬性
第二步: 将索引修改為nologging屬性
第三步: 插入的時候采用append方式來插入
第四步:如果還是慢點的話,可以采用并行插入,增大排序緩沖區
第五步:如果有可能可以先把索引置于無效狀态,然後插入完成之後再重建索引
注意: 以上解決辦法①必須是該表的資料不重要,不然修改為nologging屬性後萬一資料丢失可能就找不回來了,② 索引一般都為nologging模式,索引記錄redo沒有作用 ③ 采用append插入的前提是該表上邊沒有大量的delete動作
最後優化後的代碼:
先将表及其索引置于NOLOGGING模式:
alter table RISKREPT.BASE_FMLG NOLOGGING;
alter index DX_RKO_FMLG_BATCH_DATE NOLOGGING;
alter index IDX_RKO_FMLG_ACCT NOLOGGING;
alter index IDX_RKO_FMLG_CARD NOLOGGING;
alter index IDX_RKO_FMLG_DT NOLOGGING;
alter index IDX_RKO_FMLG_MER NOLOGGING;
----- 修改會話的屬性,開啟并行插入:
alter session set workarea_size_policy=manual;
alter session set sort_area_size=1000000000;
alter session ENABLE parallel dml;
EXPLAIN PLAN for
INSERT /*+parallel(BASE_FMLG,4) */ INTO RISKREPT.BASE_FMLG (BATCH_DATE, DATE_STAMP_ST, TIME_STAMP_ST, ORG, ACCT, CARD_NBR, CARD_SEQ, MER_ORG, MER_NBR, REQUEST_TYPE_ID, LOGO, SYSTEM_ACTION, FINAL_ACTION, ACTION_REASON, REVERSAL_REASON, AVAIL_CR, CASH_AVAIL_CR, ACCT_CURR_BAL, ACCT_CURR_BAL_CASH, B007_GMT_DATE_TIME, B018_MER_TYPE, B019_CNTRY_CODE, B032_ACQ_ID, B033_FWD_ID, AUTH_CODE, B039_RESP_CODE, B041_CRD_ACCPT_TERM, B042_TERMTYPE2_MER_ID, B043_CRD_ACCPT_NAM, B043_CRD_ACCPT_CITY, B043_CRD_ACCPT_ST_CTRY, MESSAGE_TYPE_ID, RECORD_TYPE, SALES_AMT_RMB, TOTAL_SALES_AMT, B049_CURR_CODE, BLING_AMT, POS_ENTRY_MODE, PIN_ENTRY_MODE, TRADE_INTERNET, SALES_CTRY, SALES_CTRY_NAME, SALES_CITY, SALES_CITY_NAME, SALES_LINK, MER_CODE, MER_MCC, MER_NAM, ACQ_NAME, REVCODE, AUTH_TYPE, REF_NBR, VI_B011_SYS_AUDT_TRCE, CARD_TYPE, STAGE_TYPE, STAGE_NUM, OVERSEA_FLAG, RISK_FCD, RISK_LCD) SELECT BATCH_DATE, DATE_STAMP_ST, TIME_STAMP_ST, ORG, ACCT, CARD_NBR, CARD_SEQ, MER_ORG, MER_NBR, REQUEST_TYPE_ID, LOGO, SYSTEM_ACTION, FINAL_ACTION, ACTION_REASON, REVERSAL_REASON, AVAIL_CR, CASH_AVAIL_CR, ACCT_CURR_BAL, ACCT_CURR_BAL_CASH, B007_GMT_DATE_TIME, B018_MER_TYPE, B019_CNTRY_CODE, B032_ACQ_ID, B033_FWD_ID, AUTH_CODE, B039_RESP_CODE, B041_CRD_ACCPT_TERM, B042_TERMTYPE2_MER_ID, B043_CRD_ACCPT_NAM, B043_CRD_ACCPT_CITY, B043_CRD_ACCPT_ST_CTRY, MESSAGE_TYPE_ID, RECORD_TYPE, SALES_AMT_RMB, TOTAL_SALES_AMT, B049_CURR_CODE, BLING_AMT, POS_ENTRY_MODE, PIN_ENTRY_MODE, TRADE_INTERNET, SALES_CTRY, SALES_CTRY_NAME, SALES_CITY, SALES_CITY_NAME, SALES_LINK, MER_CODE, MER_MCC, MER_NAM, ACQ_NAME, REVCODE, AUTH_TYPE, REF_NBR, VI_B011_SYS_AUDT_TRCE, CARD_TYPE, STAGE_TYPE, STAGE_NUM, OVERSEA_FLAG, SYSDATE, SYSDATE FROM TEMP_FMLG_PURGE_2 ;
commit;
select * from table(DBMS_XPLAN.display('','',''));
優化後的執行計劃:
自己跑了一下,大約30分鐘就可以跑完,從12個小時縮短到30分鐘,這個還是比較有成就感的。。。。
産生的redo量不足500M,未優化之前的那個redo量達到了15G左右,忘記截圖了,是以這個sql就優化的差不多了:
select * from VW_SESSTAT_LHR a where a.SID=850 order by a.VALUE desc ;