如果你對本文工作感興趣,點選底部的閱讀原文即可檢視原論文。
<b>關于作者:羅浩,浙江大學博士研究所學生,研究方向為計算機視覺和深度學習,現為曠視科技(Face++)的 research intern。</b>
論文 | Neural Person Search Machines
連結 | http://www.paperweekly.site/papers/1088
作者 | LUOHAO
1. 摘要
作者調查了一下室外真實場景下的 Person ReID 工作,大部分相關工作都是 detection+ReID 分成兩步來做的,這篇文章提出 NPSM 方法來實作一步到位。
NPSM 主要借助 LSTM 和 attention的思想,逐漸衰減原圖中所應該關注的 ROI 區域,直到最後得到一個很精确的 ROI 區域,這個區域就是應該搜尋的 person 目标。實驗結果表明,在 CUHK-SYSU 和 PWR 資料集上都取得了 State-of-the-arts 的結果。
2. Detection & ReID
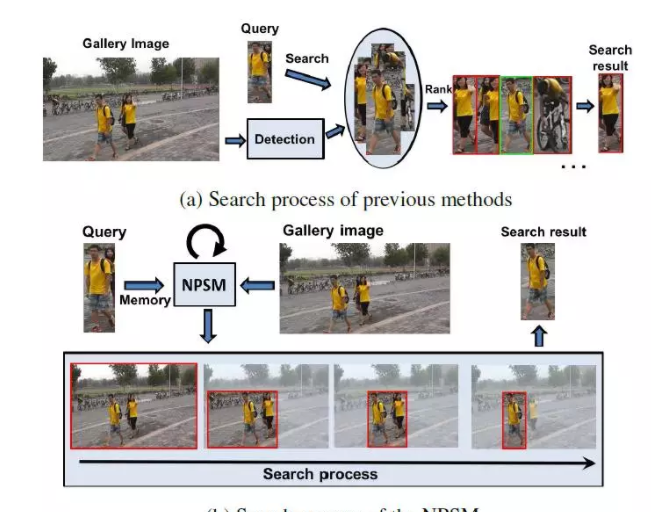
上圖給出了目前 Person ReID 的主流做法和本文做法的對比。(a) 是主流做法,先會用一個 detection 的模型檢測圖檔中的行人圖檔,可能存在錯誤檢測的 bounding box,然後用一個訓練好的 ReID 模型把所有 bounding box 的圖檔和帶檢索的 Query 圖檔進行相似度比較,之後按照相似度進行一個排序,排名最靠前的就是檢索的結果。
而 NPSM 則把兩個結合起來,每次輸入 ROI 區域圖檔,根據 Query 圖檔生成 attention map,然後選擇 attention 比較大的區域作為新的 ROI 區域。是以新的 ROI 區域是之前輸入 ROI 區域的子集,進過 LSTM 反複衰減這個 ROI,最終就可以得到一個比較精确的搜尋結果。
當然這裡不負責任的吐槽一下,這個插圖很可能是為了展現這篇工作的一個“擺拍”。因為提供原圖的 ReID 資料集比較少,論文裡使用了 CUHK-SYSU 和 PWR 兩個資料集,但是這幅圖根據我的經驗應該不屬于這兩個資料集,也許是為了展現主流方法失效而本文方法有效的一個擺拍吧。
因為在着裝非常類似的情況下,比如都穿黃衣服的兩個行人主流方法确實很難區分,是以不是很清楚這個是不是為了寫論文自己去拍的或者從資料集裡面特意挑選的。不過這都沒關系,作為一副插圖,很明白的展現自己工作的創新點,一圖勝千言,是以這幅插圖是非常合格的。
3. Neural Search Networks
這篇論文的模型以 seq2seq 為背景,主要在三個點上做改進。(1)在 embedding 上加情感資訊(2)改進 loss function(3)beam search 時考慮情感。

Neural Search Networks (NSN) 主要的核心就是一個 Conv-LSTM 網絡,CNN 網絡采用的是 Resnet50。Resnet50 被分成了兩部分,前面幾層淺層特征用來提取 attention map,後面幾層高層網絡用來提取 ReID 所需要的 feature。
如上圖所示,輸入一張 query 圖檔,經過 Resnet50(Primitive Memory)之後會輸出兩個,一個是 ROI pooling 得到的 feature map,這個 feature map 用來輸入到 NSN 裡進行 attention map 的計算。另外一個就是輸出的就行高層的 ReID feature,這個 feature 将會輸入到 IDNet 進行 ReID 的識别任務。
Query 圖檔經過 Primitive Memory 網絡的 part1 部分會得到一個 attention map q,之後 q 将會輸入到 NSN 的 LSTM 單元裡進行計算,傳統的 LSTM 的 cell 是考慮隐狀态
和目前的輸入
,在 NSN 中進一步增加了 query 圖檔的特征 q,最終改進後的 LSTM 的公示如下所示:
可以看出就是把 q 引入到 LSTM 裡面去計算三個門的值而已。LSTM 單元的狀态一直在變,但是輸入的 q 是一直不變的,因為需要用新的 ROI 區域和 Query 圖檔比較來得到新的 attention map。不過 LSTM 的時間步長論文沒有提及。
4. Region Shrinkage with Primitive Memory
上一個小節介紹了如何更新 attention map,但是得到 attention map 之後要如何得到 ROI 區域?
首先作者使用一個無監督的 object proposal 模型(例如 Edgeboxes)來産生很多個 proposal,很多 detection 的任務都是這樣做的。之後每個 proposal 我們都可以得到其矩形的中點,之後利用中點的坐标來對這些 proposal 進行聚類。而作者使用最簡單的歐氏距離來進行距離的衡量,假設 aa 和 bb 是兩個 proposal 框的中點坐标,則它們的距離定義為:
之後利用聚類算法可以将所有的 proposal 聚為 C 類,聚類細節論文沒有提及。每一類的子區域由區域
覆寫,所有
區域的父區域定義為
。這一塊不是很看懂,可能
也是覆寫所有
區域的意思。很明顯第 t 時刻的
區域是從 t−1 時刻的
中産生。
另外由于每次 NSN 輸出的 ROI 區域大小都是不一樣的,這對于後續計算 ReID 的 feature 是不好處理的,于是作者自己設計了一個 ROI pooling,保證不管輸出多大的 ROI 區域,進過 ROI pooling 之後都可以得到一個固定大小 K×K×D 的 feature map 輸入到後面的網絡。
當然這個 pooling 的細節論文裡也沒透露。之後對于 K×K 的 feature map,我們可以計算它們的 attention 得分,其實就是很簡單的做了一個二維的 softmax,公示如下:
是每個像素點坐标的 attention 得分,加起來整幅圖的總分就是 1。前面我們通過聚類得到了一些 proposal,現在我們就要計算每個 proposal 的重要性得分。實作方式就是計算每個 proposal 中所有像素重要性得分的平均值,那個 proposal 的平均值更高,就認為這個框的更重要,最終選擇分最高的那個作為 ROI 區域輸入到下一個時刻。
5. Training Strategy
LSTM 最後一個時刻輸出的 ROI 區域進過 ROI pooling 進入到網絡的 part2 計算 ReID feature,然後這個 feature 用來計算 ReID 的損失,作者在論文中使用 IDNet,也就是說把 ReID 當做分類問題來看待,計算分類損失。
另外還有一部分損失時輸出的 bounding box 的損失,計算方法就是 grand truth 的 bounding box 中的像素如果落在 Rt 中就認為 ok,否則就算一個損失,就是一個很簡單的 0-1 損失問題。這個損失會強迫 grand truth 落在網絡的預測的 ROI 裡面,并且随着 ROI 的衰減這個 ROI 會越來越接近 grand truth。
6. 結果
作者使用 CUHK-SYSU 和 PWR 兩個資料集來驗證算法的有效性,因為和一般 detection+ReID 的方法不同,是以計算 mAP 和 top-1 的方法有點不一樣。mAP 和标準的 detection 任務的計算方法一樣,使計算 bounding box 的坐标,而 top-1 計算是認為網絡預測的 ROI 和 grand truth 重合度超過 50% 就認為識别正确。是以本論文也隻能和自己思路一樣的方法進行比較,最後結果是本文方法比 baseline 高了兩個點左右。
從展現出來的 attention map 來看,方法還是比較不錯的:
7. 簡評
這篇論文的工作和主流的 ReID 工作不大一樣,把 detection+ReID 結合在一起做,方法還是比較新穎的,不過有太多論文細節沒有透露,除非作者公布源碼否則複現起來基本不可能。另外除了 ReID 任務,我覺得這篇文章擴充成 tracking 可能更加有意義。
原文釋出時間為:2017-11-13
本文作者:羅浩