我把MySQL的内容整理成9篇部落格,學完這9篇部落格雖不能說能成為大神,但是應付一般中小企業的開發已經足夠了,有疑問或建議的歡迎留言讨論。

a) 适當的違反三大範式。
b) 适當建立索引。
c) 對表進行水準劃分(按照一個周期對表資料進行拆分)。
d) 對表進行垂直劃分(對字段内容較長的字段進行拆分到一個新表)。
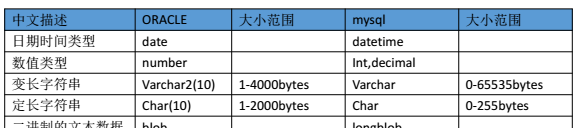
e) 選擇合适的字段類型。能占用位元組小的字段就不要去大字段。
f) 檔案、圖檔等二進制的檔案使用檔案系統存儲,不用資料庫。資料庫中隻存儲檔案路徑。
g) 甯可集中批量操作 也不要頻繁操作。
h) 合适的引擎選擇 mysql 的資料庫引擎,innodb,myisam,memory 。Myisam 比innodb 的讀速度更快。Innodb 是支援事務。Myisam 不支援事務。
a. 使用 EXPLAIN 進行 SQL 語句的執行解析。
b. Mysql 慢 日 志 的 功 能 需 要 去 配 置 文 件 修 改 slow_query_log=/usr/xx.txtlong_query_time=2 機關秒。
c. 查詢語句盡量避免全表掃描,在 where order by 等涉及的字段建立索引。
d. 盡量避免在 where 子句中對 null 值進行判斷,如果進行 null 判斷則會放棄索引查詢走全表掃描,解決辦法:在 null 字段設定一個預設值來代表無值。
e. 盡量避免在 where 子句中使用!= 或 <>操作符,放棄走索引進行全表掃描,解決辦法:改為>= <=。
f. Like 查詢,使用’%jame’ 不會走索引,使用’jame%’ 會走索引。
g. 盡量避免在 where 子句中使用 or 來連接配接條件 不會走索引走全表掃描。解決辦法:将兩個條件作為兩條 sql 語句執行 使用 union all 來進行結果集的整合。
h. In 和 not in 也要少用,會導緻全表掃描。
i. 盡量避免在 where 子句中對字段進行表達式的操作,不會走索引會走全表掃描。Num/3=100 修改成 num = 3*100。
j. 盡量避免在 where 子句中使用函數對字段進行操作. Substring(name,1,3)=’xzg’ 修改成name like ‘xzg%’。
k. 不要在 Where 字句的 =号的左邊進行函數或者其他表達式的運算,資料庫可能就無法正确使用索引。
l. 使用 exists 來代替 in。
m. 在代碼中盡量避免使用 select * from 而是列出準确的字段名。
n. 盡量避免使用遊标。
o. 資料較少的表 盡量讓他走全表掃描。